在《Hadoop 1.x中fsimage和edits合并实现》文章中提到,Hadoop的NameNode在重启的时候,将会进入到安全模式。而在安全模式,HDFS只支持访问元数据的操作才会返回成功,其他的操作诸如创建、删除文件等操作都会导致失败。 NameNode在重启的时候,DataNode需要向NameNode发送块的信息,NameNode只有获取到整个文件系统中有99.9%(可以配 w397090770 10年前 (2014-03-13) 17221℃ 3评论16喜欢
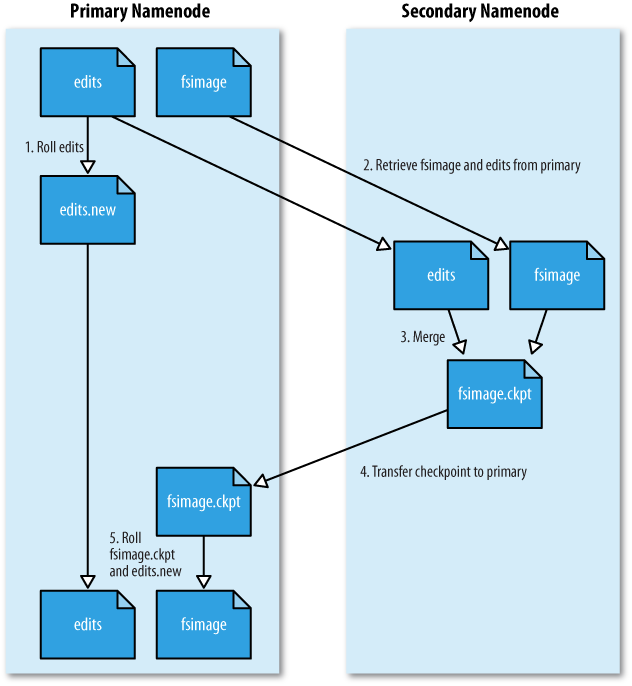
在《Hadoop 1.x中fsimage和edits合并实现》文章中,我们谈到了Hadoop 1.x上的fsimage和edits合并实现,里面也提到了Hadoop 2.x版本的fsimage和edits合并实现和Hadoop 1.x完全不一样,今天就来谈谈Hadoop 2.x中fsimage和edits合并的实现。 我们知道,在Hadoop 2.x中解决了NameNode的单点故障问题;同时SecondaryName已经不用了,而之前的Hadoop 1.x中是通过Se w397090770 10年前 (2014-03-12) 12378℃ 0评论20喜欢
在《Hadoop文件系统元数据fsimage和编辑日志edits》文章中谈到了fsimage和edits的概念、作用等相关知识,正如前面说到,在NameNode运行期间,HDFS的所有更新操作都是直接写到edits中,久而久之edits文件将会变得很大;虽然这对NameNode运行时候是没有什么影响的,但是我们知道当NameNode重启的时候,NameNode先将fsimage里面的所有内容映像到 w397090770 10年前 (2014-03-10) 9722℃ 2评论18喜欢
在《Hadoop NameNode元数据相关文件目录解析》文章中提到NameNode的$dfs.namenode.name.dir/current/文件夹的几个文件:[code lang="JAVA"]current/|-- VERSION|-- edits_*|-- fsimage_0000000000008547077|-- fsimage_0000000000008547077.md5`-- seen_txid[/code] 其中存在大量的以edits开头的文件和少量的以fsimage开头的文件。那么这两种文件到底是什么,有什么用 w397090770 10年前 (2014-03-06) 20299℃ 1评论45喜欢
下面所有的内容是针对Hadoop 2.x版本进行说明的,Hadoop 1.x和这里有点不一样。 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:[code lang="JAVA"][wyp@wyp hadoop-2.2.0]$ $HADOOP_HOME/bin/hdfs namenode -format[/code] 格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构[code lang="JAVA"]c w397090770 10年前 (2014-03-04) 13239℃ 1评论17喜欢
Snappy是用C++开发的压缩和解压缩开发包,旨在提供高速压缩速度和合理的压缩率。Snappy比zlib更快,但文件相对要大20%到100%。在64位模式的Core i7处理器上,可达每秒250~500兆的压缩速度。 Snappy的前身是Zippy。虽然只是一个数据压缩库,它却被Google用于许多内部项目程,其中就包括BigTable,MapReduce和RPC。Google宣称它在这个库本 w397090770 10年前 (2014-03-03) 13436℃ 1评论2喜欢
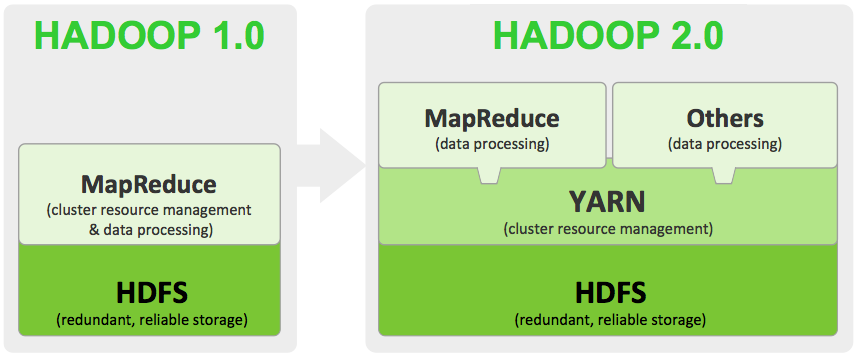
分布式计算开源框架Hadoop近日发布了今年的第一个版本Hadoop-2.3.0,新版本不仅增强了核心平台的大量功能,同时还修复了大量bug。新版本对HDFS做了两个非常重要的增强:(1)、支持异构的存储层次;(2)、通过数据节点为存储在HDFS中的数据提供了内存缓存功能。 借助于HDFS对异构存储层次的支持,我们将能够在同一个Hado w397090770 10年前 (2014-03-02) 4108℃ 0评论1喜欢
Hadoop YARN自带了一系列的web service REST API,我们可以通过这些web service访问集群(cluster)、节点(nodes)、应用(application)以及应用的历史信息。根据API返回的类型,这些URL源归会类到不同的组。一些API返回collector类型的,有些返回singleton类型。这些web service REST API的语法如下:[code lang="JAVA"]http://{http address of service}/ws/{version}/{resourcepa w397090770 10年前 (2014-02-27) 25964℃ 2评论18喜欢
hadoop更新实在是太快了,现在已经更新到Hadoop-2.3.0版本(2014-02-11)。看了一下文档,和之前Hadoop-2.2.0的文档大部分类似,这篇文章主要是翻译一下Hadoop-2.3.0的文档。 Apache Hadoop 2.3.0和之前的Hadoop-1.x稳定版有了很大的提升。本篇文章主要是简要说说Hadoop 2.3.0中的HDFS和Mapreduce的提升(4、5两个特性是Hadoop2.x开始就支持的)。 w397090770 10年前 (2014-02-26) 7570℃ 2评论2喜欢
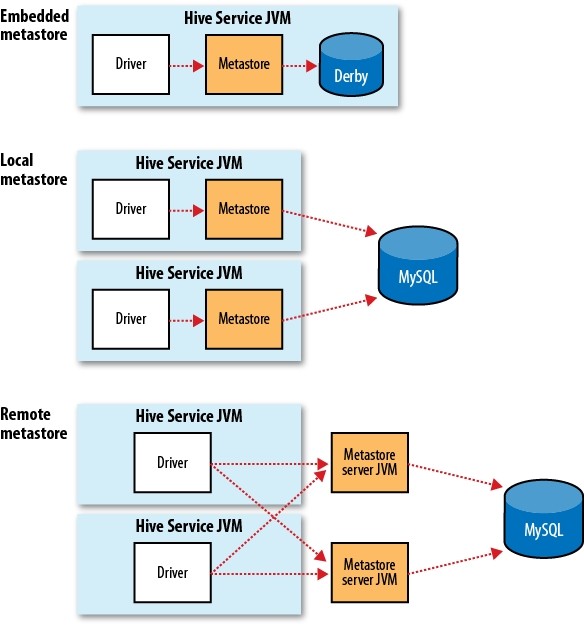
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 Hive内部自带了许多的服务,我们可以 w397090770 10年前 (2014-02-24) 18892℃ 1评论10喜欢