4月16日在http://mirror.bit.edu.cn/apache/hive/hive-0.13.0/网址就可以下载Hive 0.13,这个版本在Hive执行速度、扩展性、SQL以及其他方面做了相当多的修改:一、执行速度 用户可以选择基于Tez的查询,基于Tez的查询可以大大提高Hive的查询速度(官网上上可以提升100倍)。下面一些技术对查询速度的提升: (1)、Broadcast Joins:和M w397090770 10年前 (2014-04-25) 8221℃ 1评论1喜欢
在本博客的《Spark 0.9.1 Standalone模式分布式部署》详细的介绍了如何部署Spark Standalone的分布式,在那篇文章中并没有介绍如何来如何来测试,今天我就来介绍如何用Java来编写简单的程序,并在Standalone模式下运行。 程序的名称为SimpleApp.java,通过调用Spark提供的API进行的,在程序编写前现在pom引入相应的jar依赖:[code lang="JA w397090770 10年前 (2014-04-24) 7594℃ 0评论2喜欢
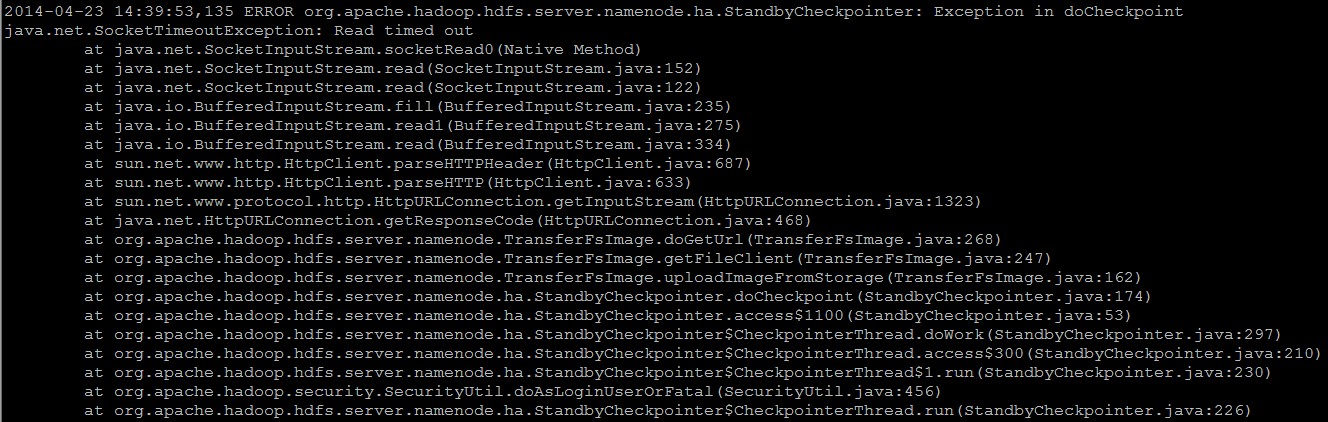
这几天观察了一下Standby NN上面的日志,发现每次Fsimage合并完之后,Standby NN通知Active NN来下载合并好的Fsimage的过程中会出现以下的异常信息:[code lang="JAVA"]2014-04-23 14:42:54,964 ERROR org.apache.hadoop.hdfs.server.namenode.ha. StandbyCheckpointer: Exception in doCheckpointjava.net.SocketTimeoutException: Read timed out at java.net.SocketInputStream.socketRead0( w397090770 10年前 (2014-04-23) 7638℃ 2评论8喜欢
在本博客的《Spark 0.9.1源码编译》和《Spark源码编译遇到的问题解决》两篇文章中,分别讲解了如何编译Spark源码以及在编译源码过程中遇到的一些问题及其解决方法。今天来说说如何部署分布式的Spark集群,在本篇文章中,我主要是介绍如何部署Standalone模式。 一、修改配置文件 1、将$SPARK_HOME/conf/spark-env.sh.template文件 w397090770 10年前 (2014-04-21) 9451℃ 1评论5喜欢
根据官方文档,Spark可以用Maven进行编译,但是我试了好几个版本都编译不通过,所以没用(如果大家用Maven编译通过了Spark,求分享。)。这里是利用sbt对Spark进行编译。中间虽然也遇到了很多问题,但是经过几天的折腾,终于通过了,关于如何解决编译中间出现的问题,可以参见本博客的《Spark源码编译遇到的问题解决》进行 w397090770 10年前 (2014-04-18) 10979℃ 3评论7喜欢
1、内存不够[code lang="JAVA"][ERROR] PermGen space -> [Help 1][ERROR] [ERROR] To see the full stack trace of the errors,re-run Maven with the -e switch.[ERROR] Re-run Maven using the -X switch to enable full debug logging.[ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles:[ERROR] [Help 1]http://cwiki.apache.org/confluence/display/MAVEN/OutOfMemoryErr w397090770 10年前 (2014-04-16) 15478℃ 4评论9喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 在Hive中,我们应该都听过RCFile这种格 w397090770 10年前 (2014-04-16) 83514℃ 9评论73喜欢
这个月的4月7号,Apache Hadoop 2.4.0已经发布了,Hadoop 2.4.0是2014年第二个Hadoop发布版本(在2月20日发布了Apache Hadoop 2.3.0),他在HDFS上做了一些加强,比如对异构存储层次的支持和通过数据节点为存储在HDFS中的数据提供了内存缓存功能。在Hadoop2.4.0主要做了以下工作: (1)、HDFS支持访问控制列表(ACLs,Access Control Lists); w397090770 10年前 (2014-04-12) 8035℃ 0评论3喜欢
Avro有C, C++, C#, Java, PHP, Python, and Ruby等语言的实现,本文只简单介绍如何在Java中使用Avro进行数据的序列化(data serialization)。本文使用的是Avro 1.7.4,这是写这篇文章时最新版的Avro。读完本文,你将会学到如何使用Avro编译模式、如果用Avro序列化和反序列化数据。一、准备项目需要的jar包 文本的例子需要用到的Jar包有这四 w397090770 10年前 (2014-04-08) 44773℃ 4评论38喜欢
Avro(读音类似于[ævrə])是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting牵头开发。Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。 在Hive中,我们可以将数据 w397090770 10年前 (2014-04-08) 15621℃ 1评论6喜欢