

文章目录
gossip 是什么
gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Alan Demers)于1987年创造的。
从 gossip 单词就可以看到,其中文意思是八卦、流言等意思,我们可以想象下绯闻的传播(或者流行病的传播);gossip 协议的工作原理就类似于这个。gossip 协议利用一种随机的方式将信息传播到整个网络中,并在一定时间内使得系统内的所有节点数据一致。Gossip 其实是一种去中心化思路的分布式协议,解决状态在集群中的传播和状态一致性的保证两个问题。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
gossip 优势
可扩展性(Scalable)
gossip 协议是可扩展的,一般需要 O(logN) 轮就可以将信息传播到所有的节点,其中 N 代表节点的个数。每个节点仅发送固定数量的消息,并且与网络中节点数目无法。在数据传送的时候,节点并不会等待消息的 ack,所以消息传送失败也没有关系,因为可以通过其他节点将消息传递给之前传送失败的节点。系统可以轻松扩展到数百万个进程。
容错(Fault-tolerance)
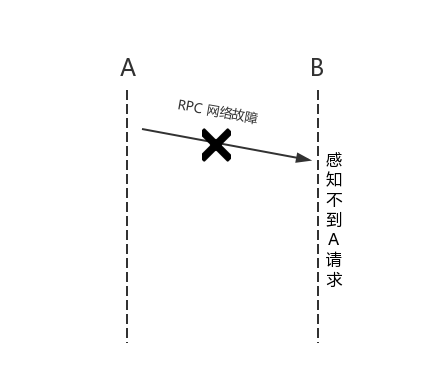
网络中任何节点的重启或者宕机都不会影响 gossip 协议的运行。
健壮性(Robust)
gossip 协议是去中心化的协议,所以集群中的所有节点都是对等的,没有特殊的节点,所以任何节点出现问题都不会阻止其他节点继续发送消息。任何节点都可以随时加入或离开,而不会影响系统的整体服务质量(QOS)
最终一致性(Convergent consistency)
Gossip 协议实现信息指数级的快速传播,因此在有新信息需要传播时,消息可以快速地发送到全局节点,在有限的时间内能够做到所有节点都拥有最新的数据。
gossip 协议的类型
前面说了节点会将信息传播到整个网络中,那么节点在什么情况下发起信息交换?这就涉及到 gossip 协议的类型。目前主要有两种方法:
- Anti-Entropy(反熵):以固定的概率传播所有的数据
- Rumor-Mongering(谣言传播):仅传播新到达的数据
Anti-Entropy
Anti-Entropy 的主要工作方式是:每个节点周期性地随机选择其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异。Anti-Entropy 这种方法非常可靠,但是每次节点两两交换自己的所有数据会带来非常大的通信负担,以此不会频繁使用。
Anti-Entropy 使用“simple epidemics”的方式,所以其包含两种状态:susceptible 和 infective,这种模型也称为 SI model。处于 infective 状态的节点代表其有数据更新,并且会将这个数据分享给其他节点;处于 susceptible 状态的节点代表其并没有收到来自其他节点的更新。
Rumor-Mongering
Rumor-Mongering 的主要工作方式是:当一个节点有了新的信息后,这个节点变成活跃状态,并周期性地联系其他节点向其发送新信息。直到所有的节点都知道该新信息。因为节点之间只是交换新信息,所有大大减少了通信的负担。
Rumor-Mongering 使用“complex epidemics”方法,相比 Anti-Entropy 多了一种状态:removed,这种模型也称为 SIR model。处于 removed 状态的节点说明其已经接收到来自其他节点的更新,但是其并不会将这个更新分享给其他节点。
因为 Rumor 消息会在某个时间标记为 removed,然后不会发送给其他节点,所以 Rumor-Mongering 类型的 gossip 协议有极小概率使得更新不会达到所有节点。
一般来说,为了在通信代价和可靠性之间取得折中,需要将这两种方法结合使用。
gossip 协议的通讯方式
不管是 Anti-Entropy 还是 Rumor-Mongering 都涉及到节点间的数据交互方式,节点间的交互方式主要有三种:Push、Pull 以及 Push&Pull。
- Push:发起信息交换的节点 A 随机选择联系节点 B,并向其发送自己的信息,节点 B 在收到信息后更新比自己新的数据,一般拥有新信息的节点才会作为发起节点。
- Pull:发起信息交换的节点 A 随机选择联系节点 B,并从对方获取信息。一般无新信息的节点才会作为发起节点。
- Push&Pull:发起信息交换的节点 A 向选择的节点 B 发送信息,同时从对方获取数据,用于更新自己的本地数据。
gossip 算法实现
Gossip 协议是按照流言传播或流行病传播的思想实现的,所以,Gossip 协议的实现算法也是很简单的,下面分别是 Anti-Entropy 和 Rumor-Mongering 的实现伪代码。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
gossip 在工程上的使用
gossip 协议可以支持以下需求:
- Database replication
- 消息传播
- Cluster membership
- Failure 检测
- Overlay Networks
- Aggregations (比如计算平均值、最大值以及总和)
在下面的工程上使用到了 gossip 协议。
- Riak(https://github.com/basho/riak) 使用 gossip 协议来共享和传递集群的环状态(ring state)和存储桶属性(bucket properties)。
- Cassandra:节点间的信息交换使用了 gossip 协议,因此所有节点都可以快速了解集群中的所有其他节点。
- Dynamo:采用基于 gossip 协议的分布式故障检测和成员协议,这样集群中添加或移除节点,其他节点可以快速检测到。
- Consul:使用了称为 SERF 的gossip 协议,主要有两个目的:1、发现新的节点或者发现故障节点;2、为一些重要的事件(比如 Leader 选举)传播提供可靠、快速的传播
- Amazon s3:使用 gossip 协议将服务的状态传递给系统。
- Redis Cluster:集群中的 Nodes 之间使用 gossip 协议向其他 nodes 传播集群信息,以达到自动发现的特性。
- 比特币:著名的比特币网络在发送消息(比如发起一笔比特币转账)的时候会使用 gossip 协议,比确保所有的结点都会收到。
- Akka Cluster:Akka 基于 gossip 协议提供了一种故障检测机制,能够自动发现出现故障而离开集群的成员节点,通过事件驱动的方式,将状态传播到整个集群的其它成员节点。
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【分布式原理:一文了解 Gossip 协议】(https://www.iteblog.com/archives/2505.html)







大佬,Cassandra不只是用来做集群信息交换呢,https://docs.datastax.com/en/ddac/doc/datastax_enterprise/dbArch/archGossipAbout.html