Apache Trafodion 是由惠普开发并开源的基于 Hadoop 平台的事务数据库引擎。提供了一个基于Hadoop平台的交易型SQL引擎。它是一个擅长处理交易型负载的Hadoop大数据解决方案。其主要特性包括:
- 完整的ANSI SQL语言支持
- 完整的ACID事务支持。对于读、写查询,Trafodion支持跨行,跨表和跨语句的事务保护
- 支持多种异构存储引擎的直接访问
- 为应用程序提供极佳的高可用性保证
- 采用了查询间(intra-query)并发执行模式。轻松支持大数据应用
- 同时应用编译时和运行时优化技术,优化了OLTP工作负载的性能
事务管理特性包括
- 事务串行化基于开源项目HBase-Trx的实现原理,采用多版本并发控制(MVCC)
- 增强的故障恢复机制保证了数据库中用户数据的一致性
- 事务管理器支持多线程的SQL客户端应用
- 支持非事务型数据访问,即直接访问底层HBase表
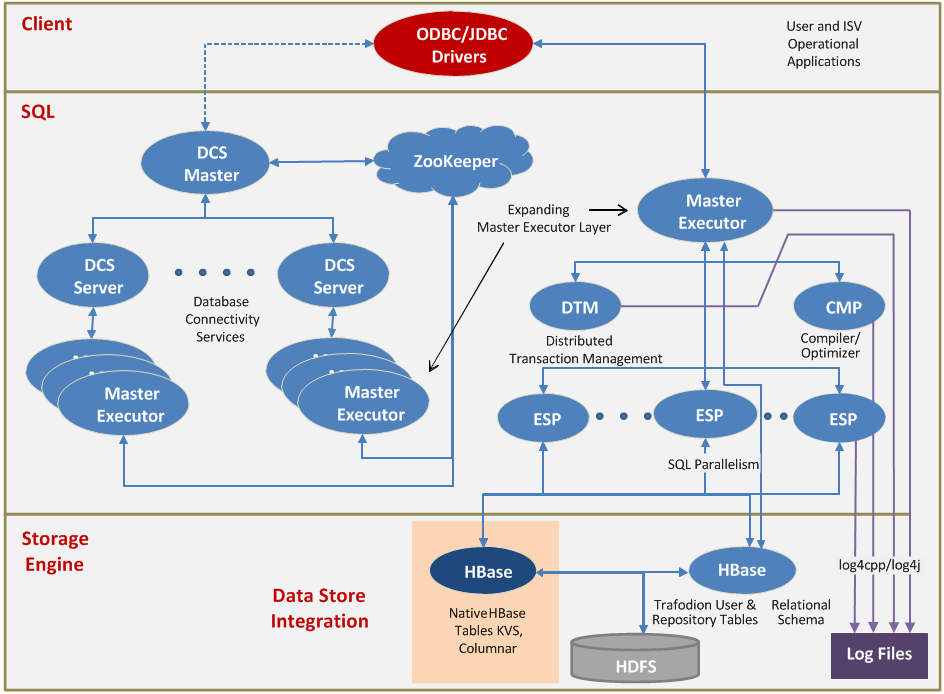
Apache Trafodion的进程构架
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
上图描述了Trafodion的进程构架。主要进程包括:
- 客户端应用通过JDBC或者ODBC访问Trafodion。Trafodion的ODBC驱动采用了优化的wire protocol,高效地同Master Executor进程进行网络交互。上图演示了一个Type 4的JDBC配置。.
- Master Executor是负责执行用户SQL语句的主进程。它内部包含了一份SQL compiler代码的拷贝,因此多数SQL语句可以在Master Executor进程内部进行编译而无需和单独的编译进程进行通信。此外,所有执行计划中的root节点都在Master Executor进程中执行。
- 少部分SQL语句(比如,DDL和一些应用工具)需要启动第二个独立的编译器进程对SQL语句进行处理;即上图中的CMP进程
- Trafodion 支持多种不同形式的并发执行方式。当系统生成了并发查询计划时,系统会动态地启动多个ESP进程,即Executor Server Processes。每一个ESP负责执行查询计划中的一个分段(fragment)
- DTM进程负责分布式事务。DTM的职责包括日志管理和事务协调。
- Trafodion支持访问原生HBase表,为此,SQL引擎将读取HBase的元数据。为了提供更好的OLTP访问性能,Trafodion还提供了定制的Trafodion表结构,用HBase Table进行存储。Trafodion表拥有自己的元数据,同样存储在HBase中。
Apache Trafodion 官方网址:https://trafodion.apache.org/
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Trafodion:基于 Hadoop 平台的事务数据库引擎】(https://www.iteblog.com/archives/2312.html)