

文章目录
Apache CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询,目前该项目正处于Apache孵化过程中。详细介绍可以参见(《CarbonData:华为开发并支持Hadoop的列式文件格式》文章介绍了)。
下载CarbonData源码 阅读CarbonData的Wiki
本文将介绍Apache CarbonData的性能基准测试及其结果,此测试结果是基于Apache CarbonData 0.1.0版本,并且和Apache Parquet进行对比,主要包括以下三方面:
1、数据加载性能;
2、数据压缩率;
3、数据查询和扫描性能。
测试环境
1、硬件配置
机器:Huawei Server RH2288
CPU:Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz (2 CPUs, 6 cores per one,logic cores 48)
内存:387G
磁盘:12 disks(SATA 3600G/7200RPM)
2、软件配置
OS: SUSE Linux 11 SP3 64 Bit
JDK:Oracle JDK 1.8.0
Hadoop版本:hadoop 2.7.2
Spark:Spark 1.6.2
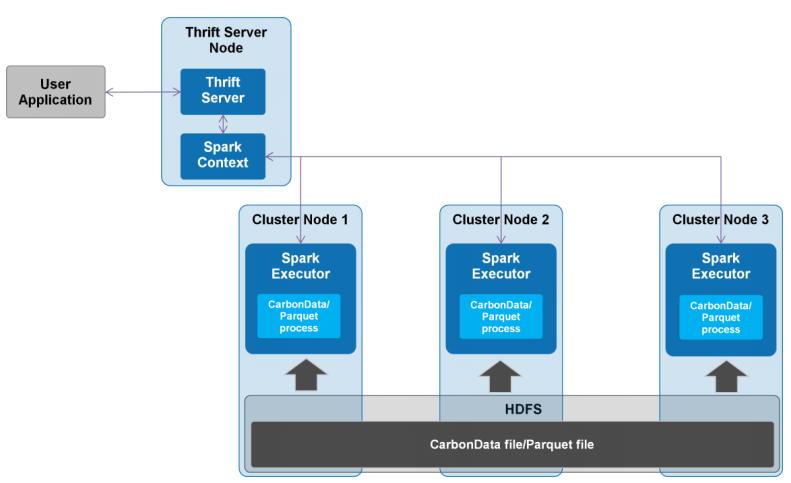
3、部署架构
测试场景和结果
1、基准测试设置
1)配置
节点个数: 3
集群管理:YARN in HA
为Carbon/Parquet配置的资源: --num-executors 3 --executor-cores 32 --executor-memory 250G --driver-memory 20G
HDFS Node Size: 3
HDFS块副本因子: 3
NO_DICTIONARY column:PROD_UNQ_MDL_ID,CUST_NICK_NAME,CUST_LOGIN,CUST_EMAIL_ADDR,PROD_UNQ_DEVICE_ADDR,PROD_UQ_UUID,PROD_BAR_CODE,TRACKING_NO,STR_ORDER_NO
ThriftServer参数: bin/spark-submit --conf spark.sql.hive.thriftServer.singleSession=true --class org.carbondata.spark.thriftserver.CarbonThriftServer --num-executors 3 --driver-memory 20g --executor-memory 250g --executor-cores 32 /srv/OSCON/BigData/HACluster/install/spark/sparkJdbc/lib/carbondata_2.10-0.1.0-incubating-SNAPSHOT-shade-hadoop2.7.2.jar hdfs://hacluster/user/hive/warehouse/carbon.store
2)表模式
本文测试使用到的表一共有300多列,详情请参考下面附件
下面是详细的测试结果
2、数据加载性能测试
数据加载时使用到9.8亿行数据,原始数据大小有1.95TB,我们分别把这些数据加载到Apache CarbonData和Apache Parquet中,结果是:
Apache CarbonData使用了6.14小时;而Apache Parquet使用了5.3小时。可以看到在数据加载方面CarbonData稍微比Parquet要慢,之所以是这样是因为CarbonData需要建立索引和字典编码,这将对后面的数据搜索大有帮助,可以在后面测试看到。
3、数据压缩率
我们把1.9T的数据分别加载到Apache CarbonData和Apache Parquet中,压缩之后大小分别为461GB和432.5,两者压缩率相差不大。
4、查询速度测试
下面的测试SQL是基于以下场景的。
1、SQL 1~3主要是全量数据进行扫描的聚合操作,结果如下:
| 序号 | SQL | Resultset (rows) | CarbonData (s) | Parquet (s) |
|---|---|---|---|---|
| 1 | select CUST_COUNTRY,CUST_CITY, count(distinct CUST_ID) from oscon_carbon where CUST_INCOME >50000 and TOTAL_TX_AMT < 1500 group by CUST_COUNTRY,CUST_CITY; | 2369 | 17.27 | 39.01 |
| 2 | select CUST_COUNTRY, SUM(STR_ORD_QTY) from oscon_carbon group by CUST_COUNTRY; | 56 | 17.10 | 24.88 |
| 3 | select CUST_CITY, AVG(WAITING_PERIOD) from oscon_carbon group by CUST_CITY; | 2360 | 9.19 | 48.42 |
CarbonData通过使用全局字典编码来加快计算速度,其使得处理/查询引擎可以直接在编码好的数据上进行处理而不需要转换数据。数据只有在返回结果给用户的时候才转换成用户可读的形式。
2、SQL 4~5主要进行OLAP的聚合操作,结果如下:
| 序号 | SQL | Resultset (rows) | CarbonData (s) | Parquet (s) |
|---|---|---|---|---|
| 4 | select CUST_SEX,PROD_COLOR, count(distinct CUST_ID) from oscon_carbon where CUST_JOB_TITLE ="Public Relations Associate" and CUST_COUNTRY ="India" and PRODUCT_NAME = "Huawei P9" group by CUST_SEX, PROD_COLOR; | 5 | 3.14 | 25.44 |
| 5 | select PROD_COLOR, SUM(STR_ORD_QTY) from oscon_carbon where CUST_COUNTRY ='India' and CUST_CITY = 'Bengaluru' and PRODUCT_NAME = 'Xiaomi Mi Note Pro' group by PROD_COLOR; | 5 | 0.38 | 19.41 |
CarbonData查询性能之所以好是因为其使用了
(1)、MDK, Min-Max and Inverted indices可以只查询需要的块;
(2)、延迟解码使得聚合操作更快。
3、SQL 6~7测试随机查询,结果如下:
| 序号 | SQL | Resultset (rows) | CarbonData (s) | Parquet (s) |
|---|---|---|---|---|
| 6 | SELECT * from oscon_carbon where CUST_PRFRD_FLG="N" and PROD_BRAND_NAME = "LG" and PROD_COLOR = "GOLD" and CUST_LAST_RVW_DATE = "2015-12-01 00:00:00" and CUST_COUNTRY = "United Kingdom" and product_name = "LG C199 phone" ; | 115 | 3.41 | 459.02 |
| 7 | SELECT CUST_NICK_NAME,CUST_FIRST_NAME,CUST_LAST_NAME, CUST_PRFRD_FLG,CUST_BIRTH_DY,CUST_BIRTH_MM,CUST_BIRTH_YR, CUST_BIRTH_COUNTRY,CUST_LOGIN,CUST_EMAIL_ADDR,CUST_LAST_RVW_DATE, CUST_SEX,CUST_ADDRESS_ID,CUST_STREET_NO,CUST_STREET_NAME,CUST_AGE, CUST_SUITE_NO,CUST_ZIP,CUST_COUNTY,CUST_DEP_COUNT,CUST_VEHICLE_COUNT, CUST_ADDRESS_CNT,CUST_CRNT_CDEMO_CNT,CUST_CRNT_HDEMO_CNT, CUST_CRNT_ADDR_DM,CUST_FIRST_SHIPTO_CNT,CUST_FIRST_SALES_CNT, CUST_GMT_OFFSET,CUST_DEMO_CNT,CUST_INCOME,PRODUCT_ID, PROD_UNQ_DEVICE_ADDR,PROD_UQ_UUID,PROD_SHELL_COLOR, DEVICE_NAME,PROD_SHORT_DESC,PROD_LONG_DESC,PROD_THUMB, PROD_IMAGE from oscon_carbon where CUST_PRFRD_FLG="N" and PROD_BRAND_NAME = "LG" and PROD_COLOR = "GOLD" and CUST_LAST_RVW_DATE = "2015-12-01 00:00:00" and CUST_COUNTRY = "United Kingdom" and product_name = "LG C199 phone" ; | 115 | 0.78 | 61.89 |
CarbonData查询性能之所以好是因为以下原因:
(1)、倒排索引可以更快地重建行数据;
(2)、列组(Column group)技术消除了行数据重建时的隐式join操作。
4、SQL 8~9 也是测试随机查询,主要测试high cardinality column的过滤操作,结果如下:
| 序号 | SQL | Resultset (rows) | CarbonData (s) | Parquet (s) |
|---|---|---|---|---|
| 8 | select * from oscon_carbon where CUST_ID = "Cust00333333" and CUST_CITY="Tirupathur" and CUST_LAST_RVW_DATE between "2015-12-03 00:00:00" and "2015-12-06 00:00:00"; | 46 | 3.46 | 453.83 |
| 9 | select CUST_NICK_NAME,CUST_FIRST_NAME,CUST_LAST_NAME,CUST_PRFRD_FLG,CUST_BIRTH_DY, CUST_BIRTH_MM,CUST_BIRTH_YR,CUST_BIRTH_COUNTRY,CUST_LOGIN,CUST_EMAIL_ADDR, CUST_LAST_RVW_DATE,CUST_SEX,CUST_ADDRESS_ID,CUST_STREET_NO,CUST_STREET_NAME, CUST_AGE,CUST_SUITE_NO,CUST_ZIP,CUST_COUNTY,CUST_DEP_COUNT,CUST_VEHICLE_COUNT, CUST_ADDRESS_CNT,CUST_CRNT_CDEMO_CNT,CUST_CRNT_HDEMO_CNT, CUST_CRNT_ADDR_DM,CUST_FIRST_SHIPTO_CNT,CUST_FIRST_SALES_CNT,CUST_GMT_OFFSET, CUST_DEMO_CNT,CUST_INCOME,PRODUCT_ID,PROD_UNQ_DEVICE_ADDR,PROD_UQ_UUID, PROD_SHELL_COLOR,DEVICE_NAME,PROD_SHORT_DESC,PROD_LONG_DESC,PROD_THUMB, PROD_IMAGE from oscon_carbon where CUST_ID = "Cust00881055" ; | 966 | 0.79 | 52.10 |
CarbonData查询性能之所以好是因为以下原因:
(1)、倒排索引可以更快地重建行数据;
(2)、列组(Column group)技术消除了行数据重建时的隐式join操作。
总结
CarbonData在数据加载和数据压缩率表现稍微比Parquet要差,但是其读性能表现比Parquet好很多,在那种写一次读多次的场景下非常适合使用;而且目前CarbonData版本已经有稳定版本可以下载,相信会有越来越多的项目会使用到。
表模式数据下载
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache CarbonData性能基准报告:查询性能秒杀Parquet】(https://www.iteblog.com/archives/1806.html)





您好,文章中提到测试数据有9.8亿条,但是发现提供下载的表的统计信息中cust_id 仅为100万,是否是提供下载的仅为部分测试数据的统计信息?