

Apache Arrow项目为列式内存存储的处理和交互提供了规范。目前来自Apache Hadoop社区的开发者们致力于将它制定为大数据系统项目的事实性标准。
Apache Arrow主要有以下几点的优势:
1、列式的内存布局可以使得随机访问的速度达到O(1)。这种内存布局在处理分析流和允许SIMD(Single input multiple data) 优化的现代处理器上非常的高效;开发者们可以开发出非常高效的算法来处理Apache Arrow的数据结构;
2、它使得系统之间数据的交互变得很高效,而且避免了数据的序列化和反序列化的消耗;
3、支持复杂的数据类型。
1、A columnar memory-layout permitting O(1) random access. The layout is highly cache-efficient in analytics workloads and permits SIMD optimizations with modern processors. Developers can create very fast algorithms which process Arrow data structures.
2、Efficient and fast data interchange between systems without the serialization costs associated with other systems like Thrift, Avro, and Protocol Buffers.
3、A flexible structured data model supporting complex types that handles flat tables as well as real-world JSON-like data engineering workloads.
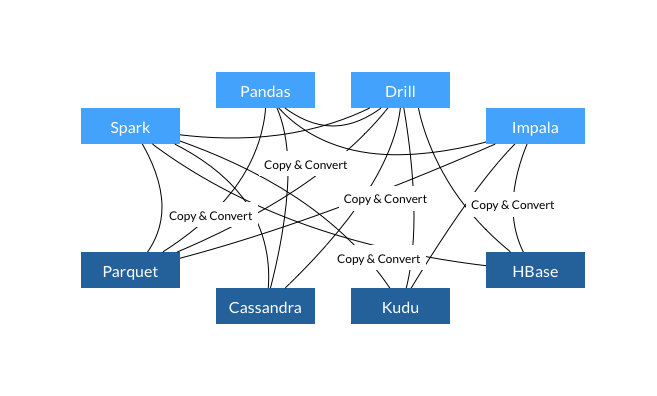
我们知道,很多大数据项目都有其自身的内存存储结构,所以在不同项目进行数据交换的时候有70-80% CPU 时间浪费在数据的serialization和deserialization操作中,而且不同项目都需要实现同一中功能的函数:
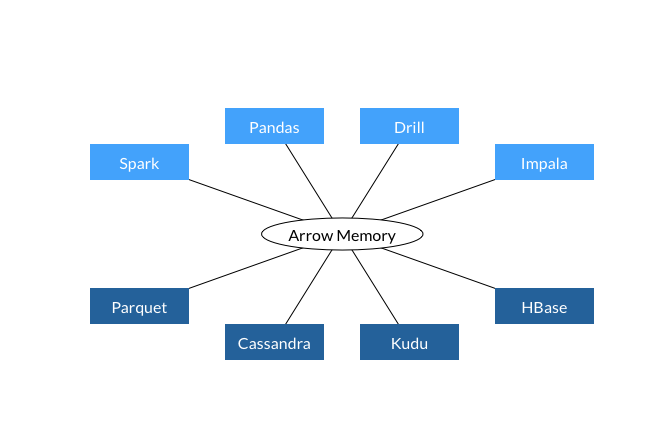
而Apache Arrow项目的出现使得所有的系统都使用相同的内存格式,系统之间的交互不需要很大的开销,新的架构如下所示。
前面也提到过Apache Arrow可以使得数据的随机访问达到O(1)。这是因为Apache Arrow对分析结构化的数据进行了优化,如下的数据:
people = [
{
name: ‘mary’, age: 30,
places_lived: [
{city: ‘Akron’, state: ‘OH’},
{city: ‘Bath’, state: OH’}
]
},
{
name: ‘mark’, age: 33,
places_lived: [
{city: ‘Lodi’, state: ‘OH’},
{city: ‘Ada’, state: ‘OH’},
{city: ‘Akron’, state: ‘OH}
]
}
]
现在假如我们需要访问people.places_lived.city的值。在Arrow中,数组值的访问看起来如下:

Arrow记录了places_lived字段和city字段的偏移量,我们可以通过这个偏移量得到字段的值。因为Arrow通过记录offset,使得数据的访问非常的高效。
Apache Arrow项目官网:http://arrow.apache.org/
Apache Arrow项目Github:https://github.com/apache/arrow
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Arrow:内存列式的数据结构标准】(https://www.iteblog.com/archives/1582.html)
