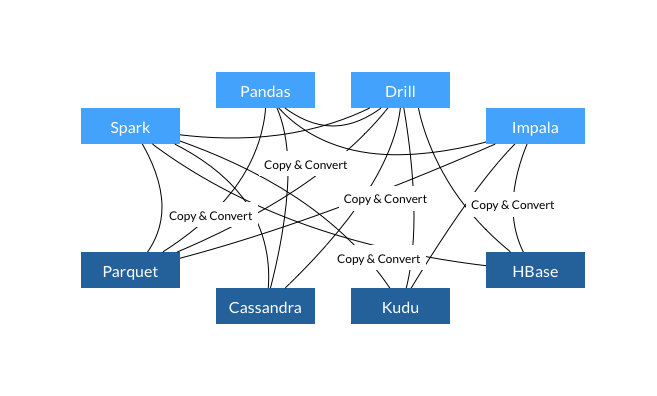
Apache Arrow是Apache基金会下一个全新的开源项目,同时也是顶级项目。它的目的是作为一个跨平台的数据层来加快大数据分析项目的运行速度。 用户在应用大数据分析时除了将Hadoop等大数据平台作为一个经济的存储和批处理平台之外也很看重分析系统的扩展性和性能。过去几年开源社区已经发布了很多工具来完善大数据分 w397090770 9年前 (2016-03-01) 3942℃ 0评论2喜欢
Apache Arrow项目为列式内存存储的处理和交互提供了规范。目前来自Apache Hadoop社区的开发者们致力于将它制定为大数据系统项目的事实性标准。 Apache Arrow主要有以下几点的优势: 1、列式的内存布局可以使得随机访问的速度达到O(1)。这种内存布局在处理分析流和允许SIMD(Single input multiple data) 优化的现代处理器上非常 w397090770 9年前 (2016-02-22) 6300℃ 0评论6喜欢