
Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,并且通过这种方式去实现零数据丢失(zero data loss)相比使用基于Receiver的方法要高效。但是因为是Spark Streaming系统自己维护Kafka的读偏移量,而Spark Streaming系统并没有将这个消费的偏移量发送到Zookeeper中,这将导致那些基于偏移量的Kafka集群监控软件(比如:Apache Kafka监控之Kafka Web Console、Apache Kafka监控之KafkaOffsetMonitor等)失效。本文就是基于为了解决这个问题,使得我们编写的Spark Streaming程序能够在每次接收到数据之后自动地更新Zookeeper中Kafka的偏移量。
我们从Spark的官方文档可以知道,维护Spark内部维护Kafka便宜了信息是存储在HasOffsetRanges类的offsetRanges中,我们可以在Spark Streaming程序里面获取这些信息:
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
这样我们就可以获取所以分区消费信息,只需要遍历offsetsList,然后将这些信息发送到Zookeeper即可更新Kafka消费的偏移量。完整的代码片段如下:
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
messages.foreachRDD(rdd => {
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val kc = new KafkaCluster(kafkaParams)
for (offsets < - offsetsList) {
val topicAndPartition = TopicAndPartition("iteblog", offsets.partition)
val o = kc.setConsumerOffsets(args(0), Map((topicAndPartition, offsets.untilOffset)))
if (o.isLeft) {
println(s"Error updating the offset to Kafka cluster: ${o.left.get}")
}
}
})
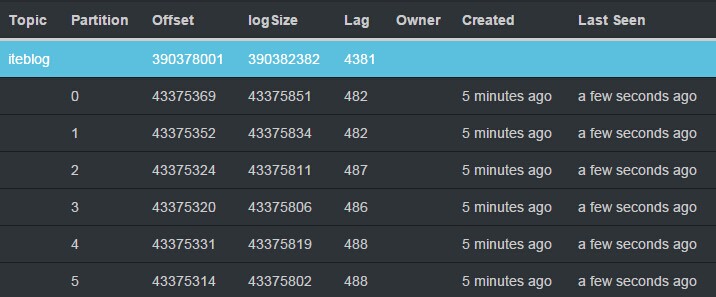
KafkaCluster类用于建立和Kafka集群的链接相关的操作工具类,我们可以对Kafka中Topic的每个分区设置其相应的偏移量Map((topicAndPartition, offsets.untilOffset)),然后调用KafkaCluster类的setConsumerOffsets方法去更新Zookeeper里面的信息,这样我们就可以更新Kafka的偏移量,最后我们就可以通过KafkaOffsetMonitor之类软件去监控Kafka中相应Topic的消费信息,下图是KafkaOffsetMonitor的监控情况:

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
从图中我们可以看到KafkaOffsetMonitor监控软件已经可以监控到Kafka相关分区的消费情况,这对监控我们整个Spark Streaming程序来非常重要,因为我们可以任意时刻了解Spark读取速度。另外,KafkaCluster工具类的完整代码如下:
package org.apache.spark.streaming.kafka
import kafka.api.OffsetCommitRequest
import kafka.common.{ErrorMapping, OffsetMetadataAndError, TopicAndPartition}
import kafka.consumer.SimpleConsumer
import org.apache.spark.SparkException
import org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
import scala.util.control.NonFatal
/**
* User: 过往记忆
* Date: 2015-06-02
* Time: 下午23:46
* bolg: https://www.iteblog.com
* 本文地址:https://www.iteblog.com/archives/1381.html
* 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货
* 过往记忆博客微信公共帐号:iteblog_hadoop
*/
class KafkaCluster(val kafkaParams: Map[String, String]) extends Serializable {
type Err = ArrayBuffer[Throwable]
@transient private var _config: SimpleConsumerConfig = null
def config: SimpleConsumerConfig = this.synchronized {
if (_config == null) {
_config = SimpleConsumerConfig(kafkaParams)
}
_config
}
def setConsumerOffsets(groupId: String,
offsets: Map[TopicAndPartition, Long]
): Either[Err, Map[TopicAndPartition, Short]] = {
setConsumerOffsetMetadata(groupId, offsets.map { kv =>
kv._1 -> OffsetMetadataAndError(kv._2)
})
}
def setConsumerOffsetMetadata(groupId: String,
metadata: Map[TopicAndPartition, OffsetMetadataAndError]
): Either[Err, Map[TopicAndPartition, Short]] = {
var result = Map[TopicAndPartition, Short]()
val req = OffsetCommitRequest(groupId, metadata)
val errs = new Err
val topicAndPartitions = metadata.keySet
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp = consumer.commitOffsets(req)
val respMap = resp.requestInfo
val needed = topicAndPartitions.diff(result.keySet)
needed.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { err: Short =>
if (err == ErrorMapping.NoError) {
result += tp -> err
} else {
errs.append(ErrorMapping.exceptionFor(err))
}
}
}
if (result.keys.size == topicAndPartitions.size) {
return Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs.append(new SparkException(s"Couldn't set offsets for ${missing}"))
Left(errs)
}
private def withBrokers(brokers: Iterable[(String, Int)], errs: Err)
(fn: SimpleConsumer => Any): Unit = {
brokers.foreach { hp =>
var consumer: SimpleConsumer = null
try {
consumer = connect(hp._1, hp._2)
fn(consumer)
} catch {
case NonFatal(e) =>
errs.append(e)
} finally {
if (consumer != null) {
consumer.close()
}
}
}
}
def connect(host: String, port: Int): SimpleConsumer =
new SimpleConsumer(host, port, config.socketTimeoutMs,
config.socketReceiveBufferBytes, config.clientId)
}
完整代码工程下载
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Spark+Kafka的Direct方式将偏移量发送到Zookeeper实现】(https://www.iteblog.com/archives/1381.html)







大神,我想问一下,用这种方式从kafka中读取数据的时候,我看代码里并没有写入到zookeeper,应该是写入到了一个地方进行存储,本来以为是checkpoint中,返现根本就没有设置checkpoint目录。那么,消费的偏移在默认情况下,也就是kafkacluster中是存储到什么地方了?
spark-streaming-kafka-0-10,新版本应该已经不用zookeeper了吧。能够自动实现偏移量提交并且分区一一对应
楼主,val o =kc.setConsumerOffsets(args(0), Map((topicAndPartition, offsets.untilOffset))) 这句话中,args(0) 参数您传的是什么内容呢?我传了一个Array: Array[(String, Int)](("192.168.202.128",9092),("192.168.202.129",9092),("192.168.202.130",9092)) ,不知道是否不对?
args(0)是groupid
报错:Error updating the offset to Kafka cluster: ArrayBuffer(kafka.common.NotCoordinatorForConsumerException,
kafka.common.NotCoordinatorForConsumerException, kafka.common.NotCoordinatorForConsumerException, org.apache.spark.SparkException: Couldn't set offsets for Set([test3,0]))
NotCoordinatorForConsumerCode 这个是什么原因呢?不知楼主是否遇到过
楼主,请教一下,direct 模式如何获取cosumer的groupId呢?因为我看setConsumerOffsetMetadata方法需要groupId的输入参数,谢谢!
你好,groupId是你程序自己传进去的。
加下我QQ 1247652934
请教一下,SimpleConsumerConfig类不能导入,这个怎么弄?我使用的是spark1.6.1版本
楼主你好,代码里 你 import org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig,后面又相当于重写了KafkaCluster类,怎么感觉有点奇怪。按照楼主的写法,代码是编译不过的。请楼主帮忙答疑。
把错误代码贴出来看看
楼主,我扣扣,501208684,能否加我下,我有问题想咨询你~
修改代码错误如下
def setConsumerOffsets(
groupId: String,
offsets: Map[TopicAndPartition, Long],
consumerApiVersion: Short
): Either[Err, Map[TopicAndPartition, Short]] = {
val meta = offsets.map { kv =>
kv._1 -> OffsetAndMetadata(kv._2)
}
setConsumerOffsetMetadata(groupId, meta, consumerApiVersion)
}
def setConsumerOffsetMetadata(
groupId: String,
metadata: Map[TopicAndPartition, OffsetAndMetadata],
consumerApiVersion: Short
): Either[Err, Map[TopicAndPartition, Short]] = {
var result = Map[TopicAndPartition, Short]()
val req = OffsetCommitRequest(groupId, metadata, consumerApiVersion)
val errs = new Err
val topicAndPartitions = metadata.keySet
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp = consumer.commitOffsets(req)
val respMap = resp.commitStatus
val needed = topicAndPartitions.diff(result.keySet)
needed.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { err: Short =>
if (err == ErrorMapping.NoError) {
result += tp -> err
} else {
errs.append(ErrorMapping.exceptionFor(err))
}
}
}
if (result.keys.size == topicAndPartitions.size) {
return Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs.append(new SparkException(s"Couldn't set offsets for ${missing}"))
Left(errs)
}
我上面的不能用么?
能用我还用费这么大劲嘛,搞一天
kafka8.1.1可以用,以后版本都不能用
哈哈,那没法,我这个文章好久之前写的。。
能加我一下qq嘛,1147149597.讨论个问题 🙂
能加我一下qq嘛,有个问题想跟你讨论一下,楼主
已经加了。
args(0)是groupidargs(0)是groupid楼主,我直接用了你的KafkaCluster类但是有问题,
val req = OffsetCommitRequest(groupId, metadata)
说metadata这个中的参数OffsetMetadataAndError要改成OffsetAndMetadata,要不然编译不通过,大神能指点一下吗
找到源代码了,请叫我雷锋。https://apache.googlesource.com/spark/+/branch-1.3/external/kafka/src/main/scala/org/apache/spark/streaming/kafka/KafkaCluster.scala
谁改好了能应用这些代码了,求发送我一份,万分感谢.1147149597@qq.com,谢了
val respMap = resp.requestInfo这行代码有错误, OffsetCommitResponse没有 requestInfo方法,不能编译通过。怎们改啊这行代码,求教。谢谢博主
您好 运行您的代码val req = OffsetCommitRequest(groupId, metadata)报错,val respMap = resp.requestInfo(resp没有requestInfo这个方法)我使用的是spark1.6.1版本,多谢回复
import org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig 不能导入怎么办
请教下 代码中val kc = new KafkaCluster(kafkaParams)
这一句我在new的时候不成功是什么情况,inaccessible from this place
spark 1.6
多谢回复
你是使用Spark自带的KafkaCluster类还是使用我这里提供的?如果你使用Spark自带的肯定不行,因为自带的KafkaCluster类访问级别是private。
是的,使用的自带的KafkaCluster
如果使用你写的KafkaCluster的话,import org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig这句话也是报这种访问不到的错误,是不是和上边我写的是一样的道理?
另外一个问题,你写的这个KafkaCluster是需要打包到spark上吗,相当于重新编译源代码?
多谢
你直接把我那个KafkaCluster类拷贝到你项目里面编译即可。不需要打包到Spark里面。
嗯好的,非常感谢 😐
没搞明白怎么做,是在我的项目里但是我需要打成jar包,老是提示错误。
拷贝进去编译的时候仍然会报错,而且是同一个错误.error: object KafkaCluster is not a member of package org.apache.spark.streaming.kafka
[INFO] Note: class KafkaCluster exists, but it has no companion object.什么情况,能不能回复的具体一点呢?
我也遇到了import org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig访问不到的问题,请问这个和spark的版本有关系么?
没关系,因为org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig这个类的访问权限是private。