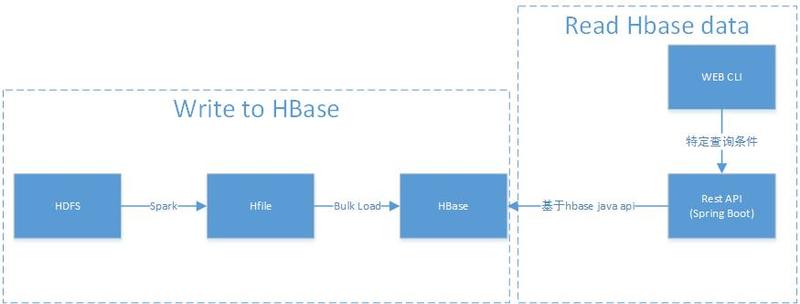
背景介绍本项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询。原实现基于 Oracle 提供存储查询服务,随着数据量的不断增加,在写入和读取过程中面临性能问题,且历史数据仅供业务查询参考,并不影响实际流...... w397090770 8年前 (2017-10-28) 2766℃ 0评论7喜欢
就在前几天,Apache Hadoop 3.0.0-beta1 正式发布了,这是3.0.0的第一个 beta 版本。本版本基于 3.0.0-alpha4 版本进行了Bug修复、性能提升以及其他一些加强。好消息是,这个版本之后会正式发行 Apache Hadoop 3.3.0 GA(General Availability,正式发布的版本)版本,这意味...... w397090770 8年前 (2017-10-11) 2339℃ 0评论15喜欢
本书于2017-07由Packt Publishing出版,作者Md. Rezaul Karim, Sridhar Alla,全书1587页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Understand object-oriented & functional programming concepts of ScalaI...... zz~~ 8年前 (2017-08-21) 7876℃ 0评论31喜欢
本书于2017-03由Packt Publishing出版,作者Muhammad Asif Abbasi,全书356页。通过本书你将学到以下知识:Get an overview of big data analytics and its importance for organizations and data professionalsDelve into Spark to see how it is different from exis...... zz~~ 8年前 (2017-07-26) 14791℃ 0评论29喜欢
大家在使用Spark、MapReduce 或 Flink 的时候很可能遇到这样一种情况:Hadoop 集群使用的 JDK 版本为1.7.x,而我们自己编写的程序由于某些原因必须使用 1.7 以上版本的JDK,这时候如果我们直接使用 JDK 1.8、或 1.9 来编译我们写好的代码,然后直接提交到 YARN 上运行,这时...... w397090770 8年前 (2017-07-04) 5578℃ 1评论16喜欢
每个 NodeManager 节点内置提供了检测自身健康状态的机制(详情参见 NodeHealthCheckerService);通过这种机制,NodeManager 会将诊断出来的监控状态通过心跳机制汇报给 ResourceManager,然后ResourceManager 端会通过 RMNodeEventType.STATUS_UPDATE 更新 NodeManager 的...... w397090770 8年前 (2017-06-08) 4358℃ 0评论18喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn...... w397090770 8年前 (2017-06-07) 3684℃ 0评论21喜欢
Job execution logs and profiles are important when troubleshooting Hadoop errors, tuning job performance, and planning cluster capacity. In the past, the Job History Server has been the primary source for this information, providing logs of important eve...... w397090770 8年前 (2017-06-02) 224℃ 0评论0喜欢
经过一个多月的投票,Apache Flink 1.2.1终于正式发布了。看这个版本就知道,Apache Flink 1.2.1仅仅是对 Flink 1.2.0进行一些Bug修复,不涉及重大的新功能。推荐所有的用户升级到Apache Flink 1.2.1。大家可以在自己项目的pom.xml文件引入以下依赖:<dependency>...... w397090770 8年前 (2017-05-04) 1685℃ 0评论6喜欢
大家在提交MapReduce作业的时候肯定看过如下的输出:17/04/17 14:00:38 INFO mapreduce.Job: Running job: job_1472052053889_000117/04/17 14:00:48 INFO mapreduce.Job: Job job_1472052053889_0001 running in uber mode : false17/04/17 14:00:48 INFO mapreduce...... w397090770 8年前 (2017-04-18) 3749℃ 2评论11喜欢


![[电子书]Scala and Spark for Big Data Analytics PDF下载](https://www.iteblog.com/pic/books/Scala_and_Spark_for_Big_Data_Analytics_iteblog.png)
![[电子书]Learning Apache Spark 2 PDF下载](https://www.iteblog.com/pic/books/Learning-Apache-Spark-2_iteblog.png)




