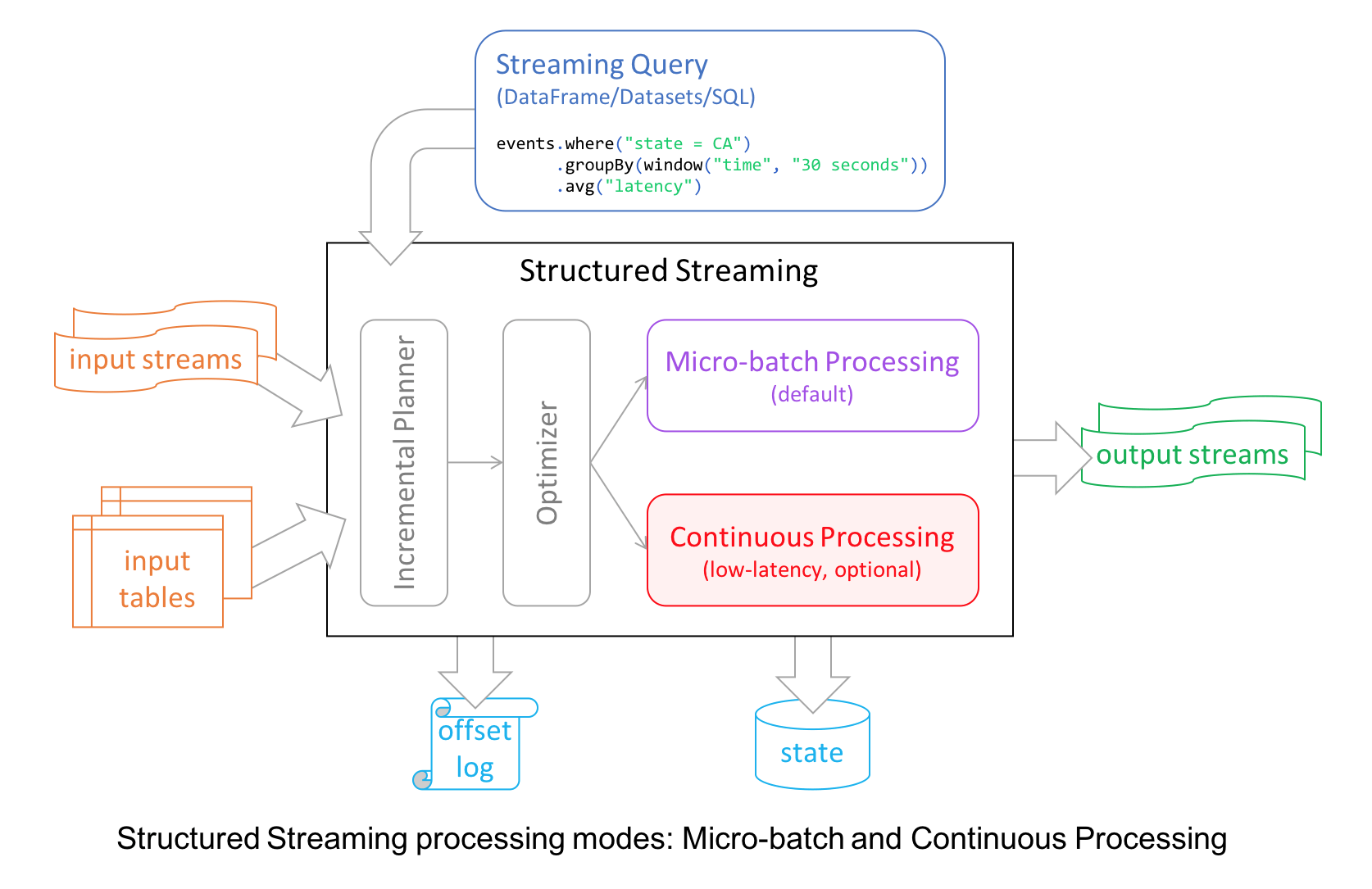
本文翻译自:Introducing Apache Spark 2.3为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.3 在许多模块都做了重要的更新,比如 Structured Streaming 引入了低延迟的连续处理(continuous processing);支持 stream-to-stream joins;通过改善 pandas UDFs 的...... w397090770 7年前 (2018-03-01) 7379℃ 3评论32喜欢
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,我们在此与大家分享一下我们在简化Spark使用和编程以及加快Spark在生产环境落地上做的一些努力。如果想及时了解Spark、Hadoop或者Hbase相关的文章...... w397090770 7年前 (2018-02-28) 6798℃ 0评论13喜欢
在 《使用Python编写Hive UDF》 文章中,我简单的谈到了如何使用 Python 编写 Hive UDF 解决实际的问题。我们那个例子里面仅仅是一个很简单的示例,里面仅仅引入了 Python 的 sys 包,而这个包是 Python 内置的,所有我们不需要担心 Hadoop 集群中的 Python 没有这个包;但...... w397090770 8年前 (2018-01-25) 6627℃ 3评论23喜欢
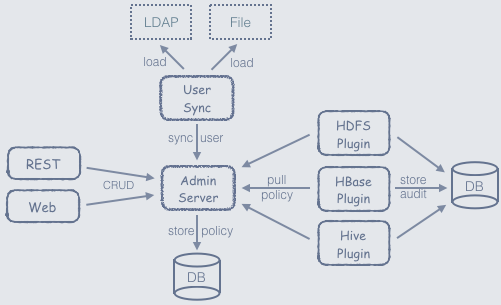
Apache Ranger 是一个用在 Hadoop 平台上并提供操作、监控、管理综合数据安全的框架。Ranger 的愿景是在 Apache Hadoop 生态系统中提供全面的安全性。 目前,Apache Ranger 支持以下 Apache 项目的细粒度授权和审计:Apache HadoopApache HiveApache HBaseApache Storm...... w397090770 8年前 (2018-01-07) 9524℃ 2评论16喜欢
本文主要盘点了 2017 年晋升为 Apache Top-Level Project (TLP) 的大数据相关项目,项目的介绍从孵化器毕业的时间开始排的,一共十二个。Apache Beam: 下一代的大数据处理标准Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目...... w397090770 8年前 (2018-01-01) 3576℃ 0评论10喜欢
今天凌晨 Apache Hadoop 3.0.0 GA 版本正式发布,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!这个版本是 Apache Hadoop 3.0.0 的第一个稳定版本,有很多重大的改进,比如支持 EC、支持多于2个的NameNodes、Intra-datanode均衡器等等。下面是关于 Apache Hadoop 3.0...... w397090770 8年前 (2017-12-15) 3547℃ 1评论38喜欢
Apache Spark 2.2.0 于今年7月份正式发布,这个版本是 Structured Streaming 的一个重要里程碑,因为其可以正式在生产环境中使用,实验标签(experimental tag)已经被移除; CBO (Cost-Based Optimizer)有了进一步的优化;SQL完全支持 SQL-2003 标准;R 中引入了新...... w397090770 8年前 (2017-12-13) 2707℃ 0评论19喜欢
本文系奇虎360系统部相关工程师投稿。近两年人工智能技术发展迅速,以Google开源的TensorFlow为代表的各种深度学习框架层出不穷。为了方便算法工程师使用各类深度学习技术,减少繁杂的诸如运行环境部署运维等工作,提升GPU等硬件资源利用率,节省硬件投入成本,奇虎360系统...... w397090770 8年前 (2017-12-08) 2802℃ 0评论15喜欢
在 《如何在Spark、MapReduce和Flink程序里面指定JAVA_HOME》文章中我简单地介绍了如何自己指定 JAVA_HOME 。有些人可能注意到了,上面设置的方法有个前提就是要求集群的所有节点的同一路径下都安装部署好了 JDK,这样才没问题。但是在现实情况下,我们需要的 JDK 版本可能...... w397090770 8年前 (2017-12-05) 3044℃ 0评论18喜欢
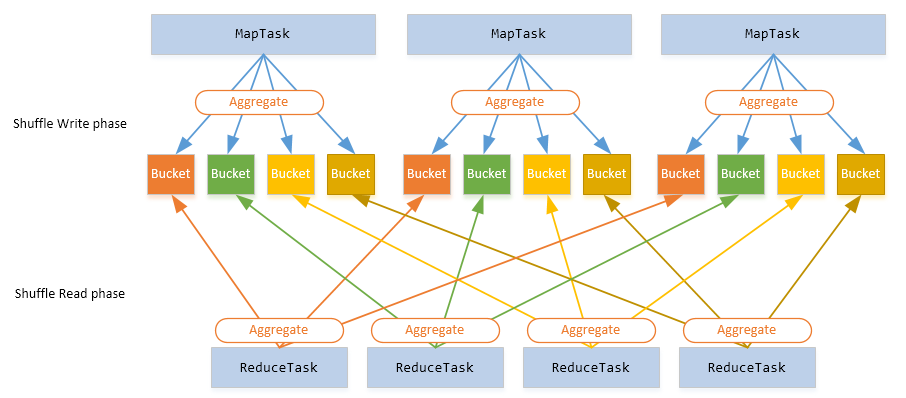
Spark Shuffle 基础在 MapReduce 框架中,Shuffle 是连接 Map 和 Reduce 之间的桥梁,Reduce 要读取到 Map 的输出必须要经过 Shuffle 这个环节;而 Reduce 和 Map 过程通常不在一台节点,这意味着 Shuffle 阶段通常需要跨网络以及一些磁盘的读写操作,因此 Shuffle 的性能...... w397090770 8年前 (2017-11-15) 7598℃ 3评论30喜欢