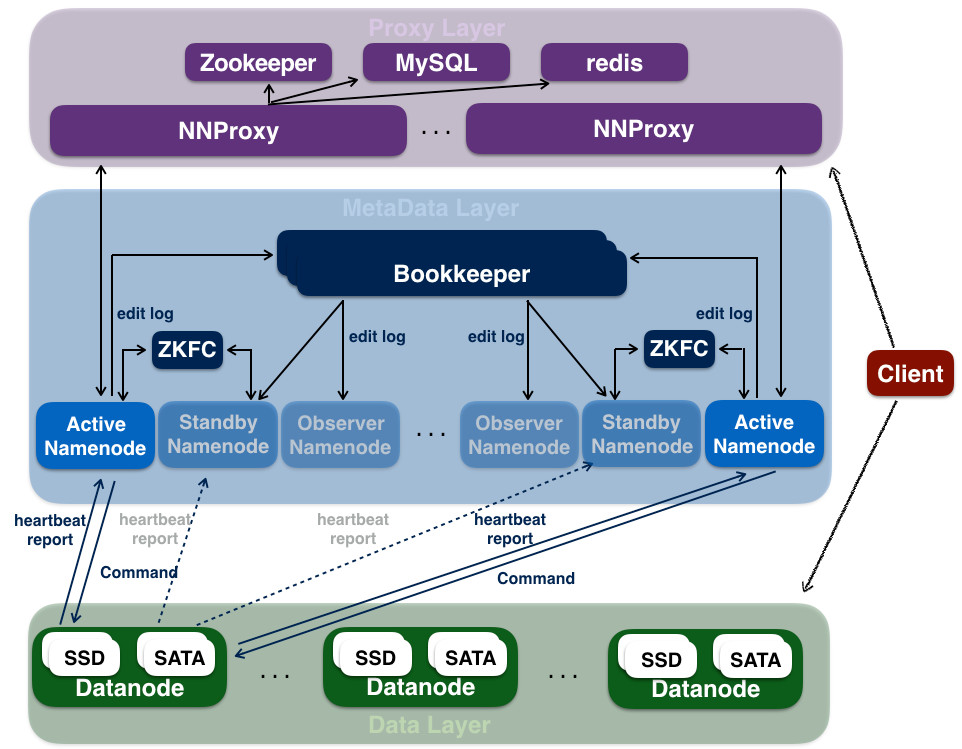
Hadoop 社区推出了新一代分布式Key-value对象存储系统 Ozone,同时提供对象和文件访问的接口,从构架上解决了长久以来困扰HDFS的小文件问题。本文作为Ozone系列文章的第一篇,抛个砖,介绍Ozone的产生背景,主要架构和功能。如果想及时了解Spark、Hadoop或者HBase相关的文...... w397090770 5年前 (2020-05-26) 2078℃ 1评论1喜欢
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 Spark...... w397090770 5年前 (2020-05-14) 2356℃ 0评论4喜欢
一、前言随着大数据技术的飞速发展,海量数据存储和计算的解决方案层出不穷,生产环境和大数据环境的交互日益密切。数据仓库作为海量数据落地和扭转的重要载体,承担着数据从生产环境到大数据环境、经由大数据环境计算处理回馈生产应用或支持决策的重要角色。数据仓库的主...... w397090770 5年前 (2020-03-01) 2084℃ 0评论7喜欢
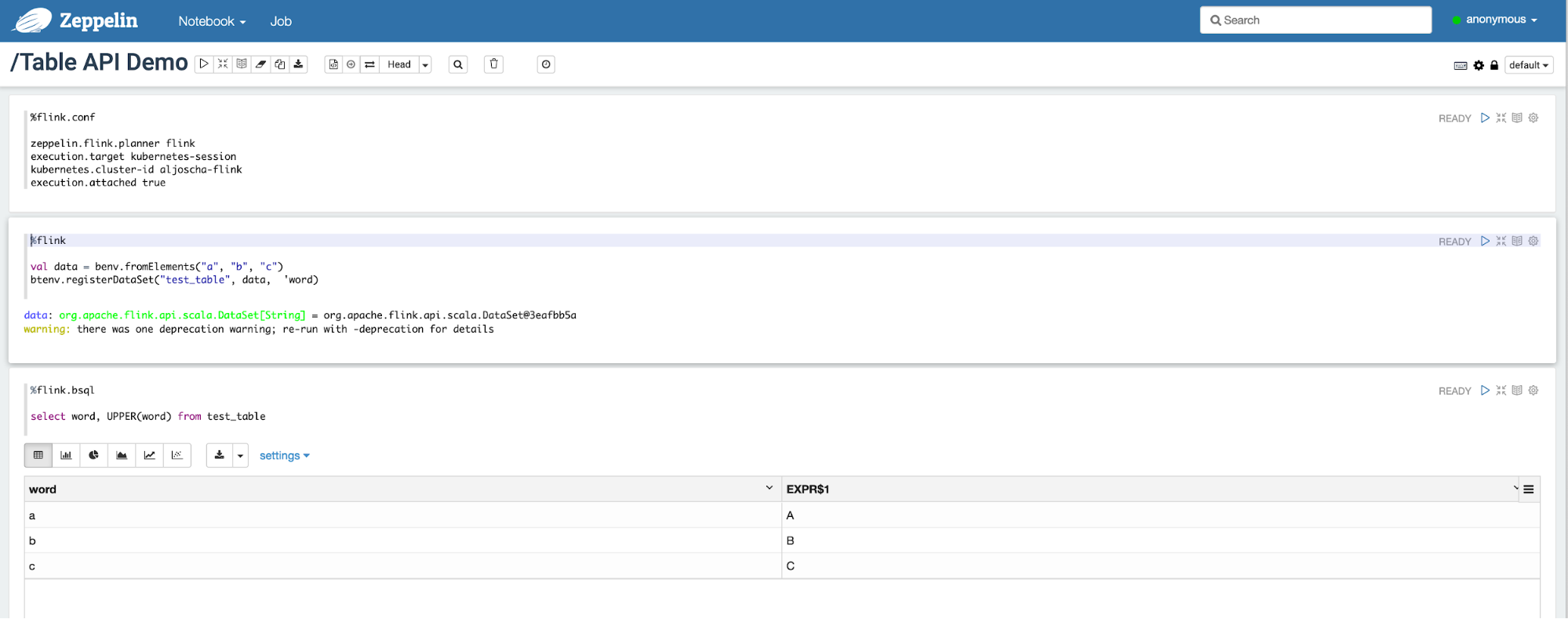
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著...... w397090770 6年前 (2020-02-12) 3512℃ 0评论3喜欢
本文来自 2019年9月23日至26日在纽约举办的 Strata Data Conference,分享者是来自 Cloudera 的 Wangda Tan 和 Wei-Chiu Chuang,会议页面 https://conferences.oreilly.com/strata/strata-ny-2019/public/schedule/detail/77506。请关注 过往记忆大数据 微信公众号,并在...... w397090770 6年前 (2020-02-04) 2711℃ 2评论5喜欢
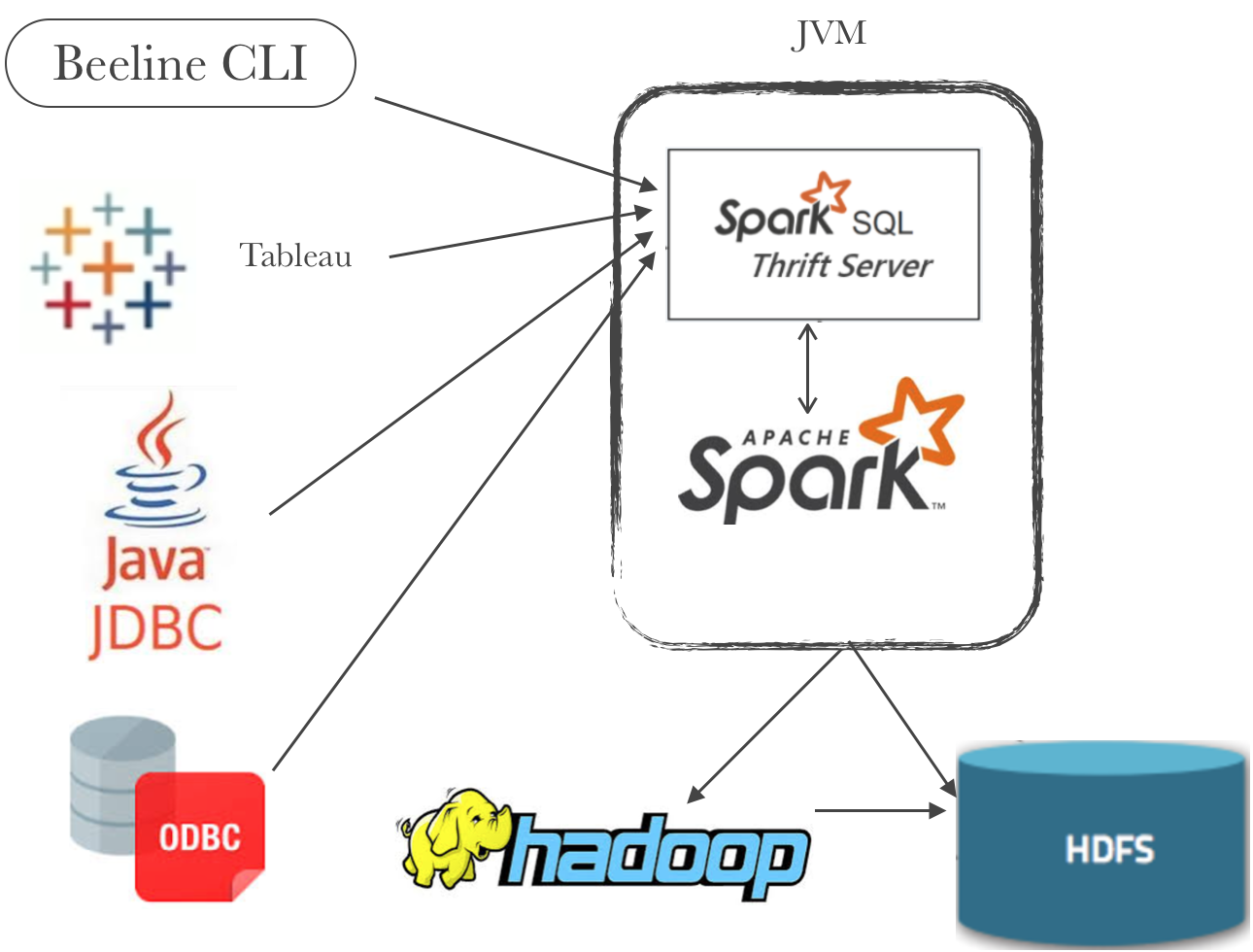
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项...... w397090770 6年前 (2020-01-10) 2448℃ 0评论4喜欢
一、前言在 2019 年 1 月份的时候,我们发表过一篇博客 从 Hive 迁移到 Spark SQL 在有赞的实践,里面讲述我们在 Spark 里所做的一些优化和任务迁移相关的内容。本文会接着上次的话题继续讲一下我们之后在 SparkSQL 上所做的一些改进,以及如何做到 SparkSQL 占比提升到 91...... w397090770 6年前 (2020-01-05) 1779℃ 0评论2喜欢
今天早上 06:53(2019年11月08日 06:53) 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3.0 版本进行大规模社区测试。无论是从 API 还是从功能上来说,这个预览版都不是一个稳定的版本...... w397090770 6年前 (2019-11-08) 2092℃ 0评论6喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的...... w397090770 6年前 (2019-09-23) 12644℃ 0评论34喜欢
今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的...... w397090770 6年前 (2019-08-13) 5714℃ 2评论33喜欢