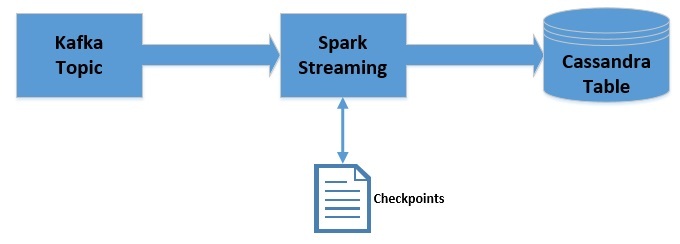
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API...... w397090770 6年前 (2019-09-08) 4145℃ 0评论8喜欢
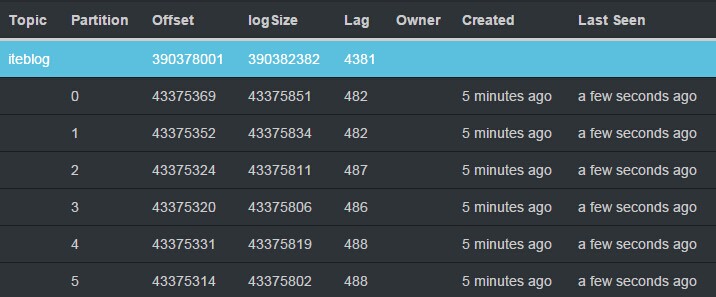
经常使用 Apache Spark 从 Kafka 读数的同学肯定会遇到这样的问题:某些 Spark 分区已经处理完数据了,另一部分分区还在处理数据,从而导致这个批次的作业总消耗时间变长;甚至导致 Spark 作业无法及时消费 Kafka 中的数据。为了简便起见,本文讨论的 Spark Direct 方式读取...... w397090770 7年前 (2018-09-08) 6664℃ 0评论25喜欢
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,我们在此与大家分享一下我们在简化Spark使用和编程以及加快Spark在生产环境落地上做的一些努力。如果想及时了解Spark、Hadoop或者Hbase相关的文章...... w397090770 7年前 (2018-02-28) 6798℃ 0评论13喜欢
在《在Kafka中使用Avro编码消息:Producter篇》 和 《在Kafka中使用Avro编码消息:Consumer篇》 两篇文章里面我介绍了直接使用原生的 Kafka API生成和消费 Avro 类型的编码消息,本文将继续介绍如何通过 Spark 从 Kafka 中读取这些 Avro 格式化的消息。如果想及时了解Spar...... zz~~ 8年前 (2017-09-26) 4805℃ 0评论19喜欢
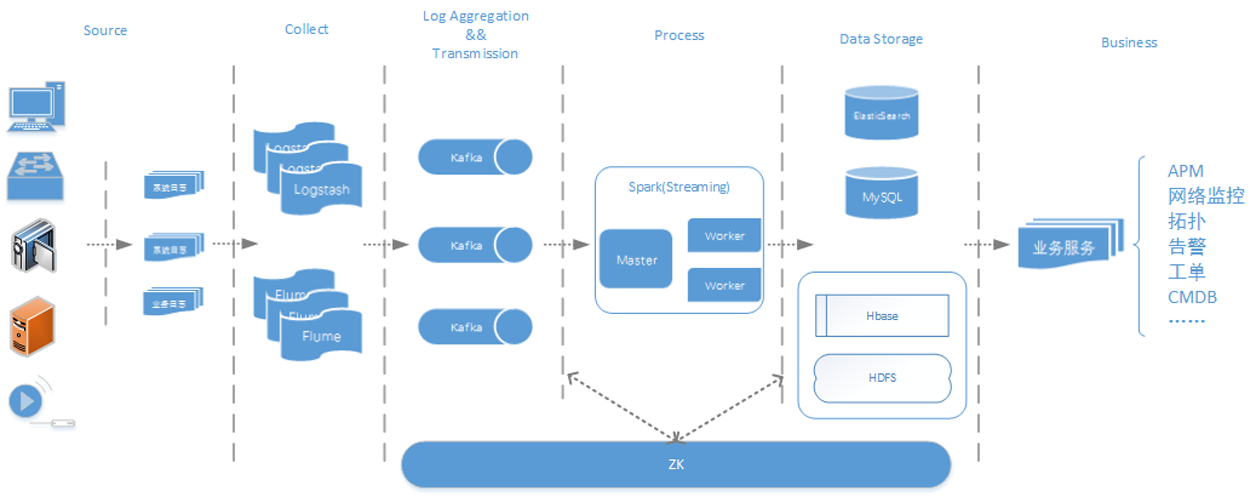
公安行业存在数以万计的前后端设备,前端设备包括相机、检测器及感应器,后端设备包括各级中心机房中的服务器、应用服务器、网络设备及机房动力系统,数量巨大、种类繁多的设备给公安内部运维管理带来了巨大挑战。传统通过ICMP/SNMP、Trap/Syslog等工具对设备进行诊断分...... w397090770 9年前 (2017-01-01) 11357℃ 1评论39喜欢
Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,并且通过这种方式去实现零数据丢失(zero data loss)相比使用基于Receiver的方法要高效。但是因为是Spark Streaming系统自己维护K...... w397090770 10年前 (2015-06-02) 25829℃ 36评论22喜欢
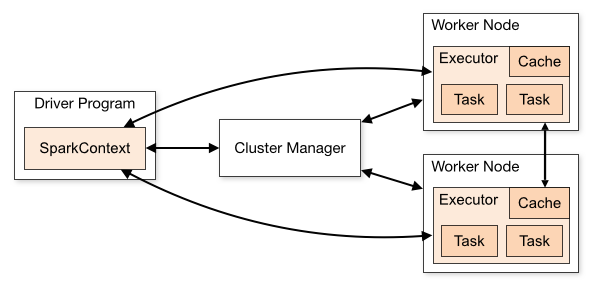
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming、Spark SQL、MLlib、GraphX,这些内建库都提供了高级抽象,可以用非常简洁的代码实现复杂的计算逻辑、这也得益于Scala编程语言的简洁性。这里,我们基...... w397090770 10年前 (2015-05-30) 37602℃ 2评论76喜欢
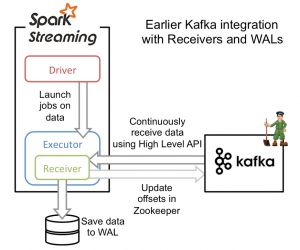
《Spark Streaming和Kafka整合开发指南(一)》 《Spark Streaming和Kafka整合开发指南(二)》 在本博客的《Spark Streaming和Kafka整合开发指南(一)》文章中介绍了如何使用基于Receiver的方法使用Spark Streaming从Kafka中接收数据。本文将介绍如何使用Spark 1....... w397090770 10年前 (2015-04-21) 28473℃ 1评论26喜欢
Apache Kafka近年来迅速地成为开源社区流行的流输入平台。同时我们也看到了Spark Streaming的使用趋势和它类似。因此,在Spark 1.3中,社区对Kafka和Spark Streaming的整合做了很多重要的提升。主要修改如下: 1、为Kafka新增了新的Direct API。这个API可以使得每个...... w397090770 10年前 (2015-04-10) 16829℃ 0评论24喜欢