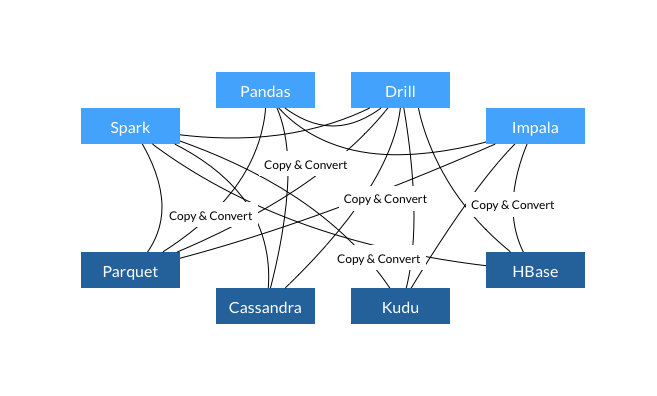
Apache Arrow项目为列式内存存储的处理和交互提供了规范。目前来自Apache Hadoop社区的开发者们致力于将它制定为大数据系统项目的事实性标准。 Apache Arrow主要有以下几点的优势: 1、列式的内存布局可以使得随机访问的速度达到O(1)。这种内存布局在处理分析流...... w397090770 10年前 (2016-02-22) 6376℃ 0评论6喜欢
如何下载整个网站用来离线浏览?怎样将一个网站上的所有 MP3 文件保存到本地的一个目录中?怎么才能将需要登陆的网页后面的文件下载下来?怎样构建一个迷你版的Google?wget 是一个自由的工具,可在包括 Mac,Window 和 Linux 在内的多个平台上使用,它可帮助你实现所有上...... w397090770 10年前 (2016-02-19) 1867℃ 0评论1喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 在前面的例子(《Apache Kafka编程入门指南:Producer篇》)中,我们学习了如何编写简单的Kafka Producer程序。在...... w397090770 10年前 (2016-02-06) 7650℃ 0评论6喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 Kafka最初由Linkedin公司开发的分布式、分区的、多副本的、多订阅者的消息系统。它提供了类似于JMS的特性,但是在...... w397090770 10年前 (2016-02-05) 10315℃ 1评论12喜欢
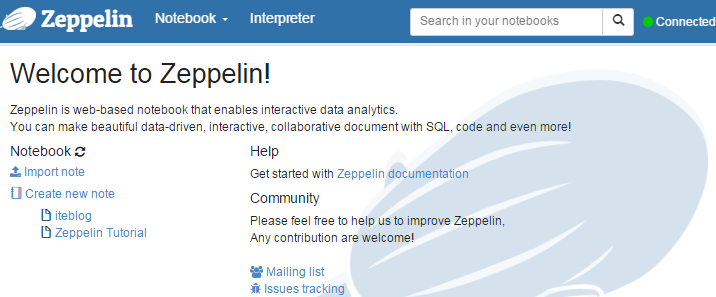
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析。原生就支持Spark、Scala、SQL 、shell, markdown等。而...... w397090770 10年前 (2016-02-02) 20881℃ 9评论20喜欢
上海Spark meetup第七次聚会将于2016年1月23日(周六)在上海市长宁区金钟路968号凌空SOHO 8号楼 进行。此次聚会由Intel联合携程举办。大会主题 1、开场/Opening Keynote: 张翼,携程大数据平台的负责人 个人介绍:本科和研究生都是浙江大学;2015年加入携程,推...... w397090770 10年前 (2016-01-28) 2621℃ 0评论6喜欢
默认情况下,Apache Zeppelin启动Spark是以本地模式起的,master的值是local[*],我们可以通过修改conf/zeppelin-env.sh文件里面的MASTER的值如下:export MASTER= yarn-clientexport HADOOP_HOME=/home/q/hadoop/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HO...... w397090770 10年前 (2016-01-22) 12151℃ 16评论12喜欢
我下载的Apache Zeppelin和Apache Spark版本分别为:0.6.0-incubating-SNAPSHOT和1.5.2,在Zeppelin中使用SQLContext读取Json文件创建DataFrame的过程中出现了以下的异常:val profilesJsonRdd =sqlc.jsonFile("hdfs://www.iteblog.com/tmp/json")val pr...... w397090770 10年前 (2016-01-21) 6939℃ 2评论11喜欢
新年伊始,上海Spark meetup第七次聚会将于2016年1月23日(周六)在上海市长宁区金钟路968号凌空SOHO 8号楼 进行。此次聚会由Intel联合携程举办,此次活动特别邀请到来自 携程,Splunk以及intel大数据的专家和大家分享Spark技术及实践经验,幸运听众还会得到一本签名版的S...... w397090770 10年前 (2016-01-16) 2814℃ 0评论3喜欢
在本博客的《使用Spark SQL读取Hive上的数据》文章中我介绍了如何通过Spark去读取Hive里面的数据,不过有时候我们在创建SQLContext实例的时候遇到类似下面的异常:java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop...... w397090770 10年前 (2016-01-11) 16520℃ 5评论14喜欢