我目前使用的Hive版本是apache-hive-1.2.0-bin,每次在使用 show create table 语句的时候如果你字段中有中文注释,那么Hive得出来的结果如下:hive> show create table iteblog;OKCREATE TABLE `iteblog`( `id` bigint COMMENT '�id', `uid` bigint COMMENT ...... w397090770 9年前 (2016-06-08) 11395℃ 0评论13喜欢
本文原文:Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop Deep dive into the new Tungsten execution engine:https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html本...... w397090770 9年前 (2016-05-27) 6084℃ 1评论16喜欢
在Spark 1.x版本,我们收到了很多询问SparkContext, SQLContext和HiveContext之间关系的问题。当人们想使用DataFrame API的时候把HiveContext当做切入点的确有点奇怪。在Spark 2.0,引入了SparkSession,作为一个新的切入点并且包含了SQLContext和HiveContext的功能。为...... w397090770 9年前 (2016-05-26) 14132℃ 0评论13喜欢
昨天我提到了如何在《Flink Streaming中实现多路文件输出(MultipleTextOutputFormat)》,里面我们实现了一个MultipleTextOutputFormatSinkFunction类,其中封装了mutable.Map[String, TextOutputFormat[String]],然后根据key的不一样选择不同的TextOutputFormat从而实...... w397090770 9年前 (2016-05-11) 4180℃ 3评论6喜欢
有时候我们需要根据记录的类别分别写到不同的文件中去,正如本博客的 《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(二)》以及《Spark多文件输出(MultipleOutputFormat)》等文章...... w397090770 9年前 (2016-05-10) 8373℃ 4评论7喜欢
Hive内部提供了很多操作字符串的相关函数,本文将对其中部分常用的函数进行介绍。下表为Hive内置的字符串函数,具体的用法可以参见本文的下半部分。返回类型函数名描述intascii(string str)返回str第一个字符串的数值stringbase64(b...... w397090770 9年前 (2016-04-24) 116634℃ 91喜欢
本文将介绍如何在Google Compute Engine(https://cloud.google.com/compute/)平台上基于 Hadoop 1 或者 Hadoop 2 自动部署 Flink 。借助 Google 的 bdutil(https://cloud.google.com/hadoop/bdutil) 工具可以启动一个集群并基于 Hadoop 部署 Flink 。根据下列步骤开始...... w397090770 9年前 (2016-04-21) 1918℃ 0评论3喜欢
本文是面向Spark初学者,有Spark有比较深入的理解同学可以忽略。前言很多初学者其实对Spark的编程模式还是RDD这个概念理解不到位,就会产生一些误解。比如,很多时候我们常常以为一个文件是会被完整读入到内存,然后做各种变换,这很可能是受两个概念的误导:1、RD...... w397090770 9年前 (2016-04-20) 8517℃ 0评论33喜欢
Apache HBase 1.2.1 于2016-04-12正式发布了,HBase 1.2.1是HBase 1.2.z版本线上的第一个维护版本,该版本的主题仍然是为Hadoop和NoSQL社区带来稳定和可靠的数据库。此版本在1.2.0版本上解决了27个issues。主要的Bug修改* [HBASE-15441] - Fix WAL splitting when r...... w397090770 9年前 (2016-04-14) 3181℃ 0评论2喜欢
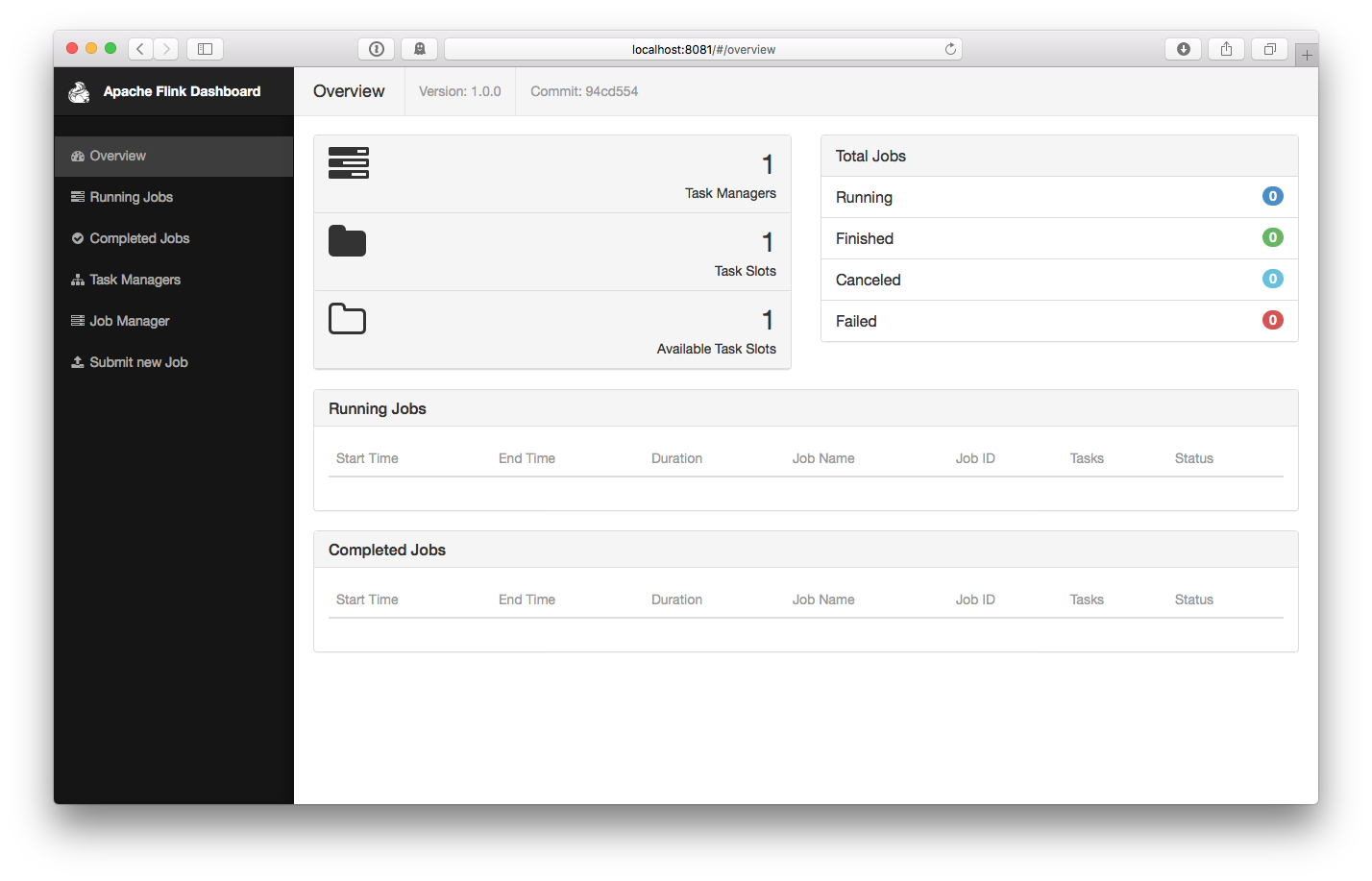
安装:下载并启动 Flink可以在Linux、Mac OS X以及Windows上运行。为了能够运行Flink,唯一的要求是必须安装Java 7.x或者更高版本。对于Windows用户来说,请参考 Flink on Windows 文档,里面介绍了如何在Window本地运行Flink。下载 从下载页面(http://flink.apac...... w397090770 9年前 (2016-04-05) 17790℃ 0评论23喜欢