下面的操作会影响到Spark输出RDD分区(partitioner)的: cogroup, groupWith, join, leftOuterJoin, rightOuterJoin, groupByKey, reduceByKey, combineByKey, partitionBy, sort, mapValues (如果父RDD存在partitioner), flatMapValues(如果父RDD存在partitioner), 和 filter (如果父RDD存在partitioner)。其他的transform操作不会影响到输出RDD的partitioner,一般来说是None,也就是没 w397090770 11年前 (2014-12-29) 16627℃ 0评论5喜欢
在很多应用场景都需要对结果数据进行排序,Spark中有时也不例外。在Spark中存在两种对RDD进行排序的函数,分别是 sortBy和sortByKey函数。sortBy是对标准的RDD进行排序,它是从Spark 0.9.0之后才引入的(可以参见SPARK-1063)。而sortByKey函数是对PairRDD进行排序,也就是有Key和Value的RDD。下面将分别对这两个函数的实现以及使用进行说明。 w397090770 11年前 (2014-12-26) 84498℃ 7评论92喜欢
Akka学习笔记系列文章: 《Akka学习笔记:ACTORS介绍》 《Akka学习笔记:Actor消息传递(1)》 《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》 《Akka学习笔记:测试Actors》 《Akka学习笔记:Actor消息处理-请求和响应(1) 》 《Akka学习笔记:Actor消息处理-请求和响应(2) 》 《Akka学 w397090770 11年前 (2014-12-22) 5821℃ 0评论8喜欢
Spark 1.2.0于美国时间2014年12月18日发布,Spark 1.2.0兼容Spark 1.0.0和1.1.0,也就是说不需要修改代码即可用,很多默认的配置在Spark 1.2发生了变化 1、spark.shuffle.blockTransferService由nio改成netty 2、spark.shuffle.manager由hash改成sort 3、在PySpark中,默认的batch size改成0了, 4、Spark SQL方面做的修改: spark.sql.parquet.c w397090770 11年前 (2014-12-19) 4684℃ 1评论2喜欢
2014 Spark亚太峰会12月6日在北京珠三角万豪酒店圆满收官,来自易观国际、Intel 、亚信科技、TalkingData、Spark亚太研究院、百度、京东、携程、IBM、星环科技、南京大学、洞庭国际智能硬件检测基地、 AdMaster、Docker中文社区、安徽象形科技的十八位演讲嘉宾为来自国内近305家企业,800多位一线开发者,带来了最干货的分享及一手的 w397090770 11年前 (2014-12-18) 30536℃ 251评论34喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 第四次北京Spark meeting会议 w397090770 11年前 (2014-12-16) 10659℃ 73评论8喜欢
SchemaRDD在Spark SQL中已经被我们使用到,这篇文章简单地介绍一下如果将标准的RDD(org.apache.spark.rdd.RDD)转换成SchemaRDD,并进行SQL相关的操作。[code lang="scala"]scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@6edd421fscala> case class Person(name: String, age:Int)defined class Perso w397090770 11年前 (2014-12-16) 21321℃ 0评论20喜欢
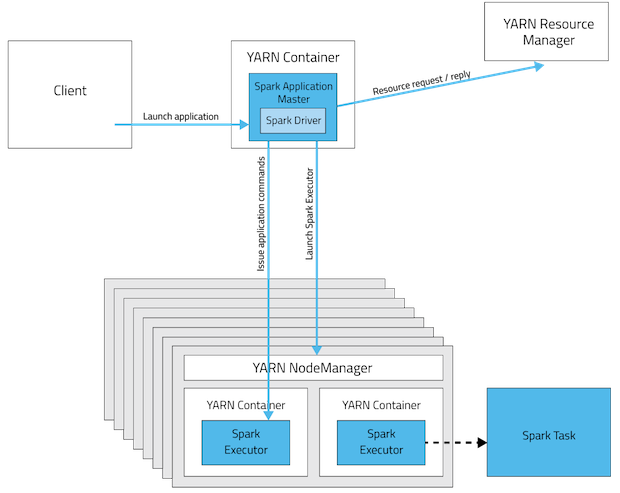
《Spark on YARN集群模式作业运行全过程分析》 《Spark on YARN客户端模式作业运行全过程分析》 《Spark:Yarn-cluster和Yarn-client区别与联系》 《Spark和Hadoop作业之间的区别》 《Spark Standalone模式作业运行全过程分析》(未发布) 我们都知道Spark支持在yarn上运行,但是Spark on yarn有分为两种模式yarn-cluster和yarn-cl w397090770 11年前 (2014-12-15) 58701℃ 4评论94喜欢
Akka学习笔记系列文章: 《Akka学习笔记:ACTORS介绍》 《Akka学习笔记:Actor消息传递(1)》 《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》 《Akka学习笔记:测试Actors》 《Akka学习笔记:Actor消息处理-请求和响应(1) 》 《Akka学习笔记:Actor消息处理-请求和响应(2) 》 《Akka学 w397090770 11年前 (2014-12-12) 10347℃ 1评论5喜欢
目前关于Spark方面的书籍已经有好几本了,这里列出了下面关于Spark 的书籍。部分书目前还没有发布,所以无法提供下载地址。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如果你要找Hadoop相关书籍,可以看这里《精心收集的Hadoop学习资料(持续更新)》 1、大数据技术丛书:Spark快速 w397090770 11年前 (2014-12-08) 36291℃ 3评论58喜欢







![Spark学习书籍收集[持续更新]](https://www.iteblog.com/pic/iteblog.png)