Databricks官网昨天发布了一篇关于Spark用206个节点打破了原来MapReduce 100TB和1PB排序的世界记录。先前的世界记录是Yahoo在2100个Hadoop节点上运行MapReduce 对102.5 TB数据进行排序,他的运行时间是72分钟;而此次的Spark采用了206 个EC2节点,并部署了Spark,对100 TB的数据进行排序,一共用了23分钟!并且所有的排序都是基于磁盘的。也就是 w397090770 11年前 (2014-10-11) 12332℃ 2评论15喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 第三次北京Spark Meetup活动将于2014年10月26日星期日的下午1:30到6:00在海淀区中关村科学院南路2号融科资讯中心A座8层举行,本次分享的主题主要是MLlib与分布式机器学 w397090770 11年前 (2014-10-09) 4505℃ 6评论6喜欢
Spark支持三种模式的部署:YARN、Standalone以及Mesos。本篇说到的Worker只有在Standalone模式下才有。Worker节点是Spark的工作节点,用于执行提交的作业。我们先从Worker节点的启动开始介绍。 Spark中Worker的启动有多种方式,但是最终调用的都是org.apache.spark.deploy.worker.Worker类,启动Worker节点的时候可以传很多的参数:内存、核、工作 w397090770 11年前 (2014-10-08) 11449℃ 3评论7喜欢
Spark 1.1.0中兼容大部分Hive特性,我们可以在Spark中使用Hive。但是默认的Spark发行版本并没有将Hive相关的依赖打包进spark-assembly-1.1.0-hadoop2.2.0.jar文件中,官方对此的说明是:Spark SQL also supports reading and writing data stored in Apache Hive. However, since Hive has a large number of dependencies, it is not included in the default Spark assembly 所以,如果你直 w397090770 11年前 (2014-09-26) 12968℃ 5评论9喜欢
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 但是Spark官方文档给出的属性只是简单的介绍了一下含义,许多细节并没有涉及到。本文及以后几篇文章将会对Spark官方的各个属性进行说明介绍。以下是根据Spark 1.1.0文档中的属性进行说明。Application相关属性绝大多数的属性控制应用程序的内部设置,并且默认值 w397090770 11年前 (2014-09-25) 18127℃ 1评论20喜欢
随着Spark项目的逐渐成熟, 越来越多的可配置参数被添加到Spark中来。在Spark中提供了三个地方用于配置:Spark properties:这个可以控制应用程序的绝大部分属性。并且可以通过 SparkConf 对象或者Java 系统属性进行设置;环境变量(Environment variables):这个可以分别对每台机器进行相应的设置,比如IP。这个可以在每台机器的 $SPARK_HOME/co w397090770 11年前 (2014-09-24) 57301℃ 1评论22喜欢
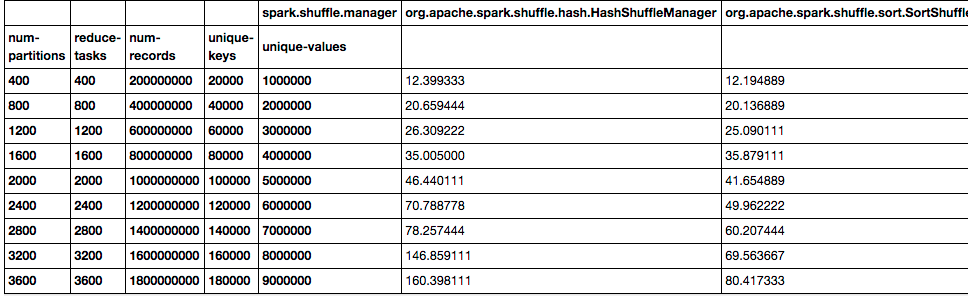
我们都知道Hadoop中的shuffle(不知道原理?可以参见《MapReduce:详细介绍Shuffle的执行过程》),Hadoop中的shuffle是连接map和reduce之间的桥梁,它是基于排序的。同样,在Spark中也是存在shuffle,Spark 1.1之前,Spark的shuffle只存在一种方式实现方式,也就是基于hash的。而在最新的Spark 1.1.0版本中引进了新的shuffle实现(《Spark 1.1.0正式发 w397090770 11年前 (2014-09-23) 15817℃ 3评论15喜欢
Apache Spark是快速的通用集群计算系统。它在Java、Scala以及Python等语言提供了高层次的API,并且在通用的图形计算方面提供了一个优化的引擎。同时,它也提供了丰富的高层次工具,这些工具包括了Spark SQL、结构化数据处理、机器学习工具(MLlib)、图形计算(GraphX)以及Spark Streaming。如果想及时了解Spark、Hadoop或者Hbase相关的文章, w397090770 11年前 (2014-09-18) 3629℃ 0评论6喜欢
Spark 1.1.0已经在前几天发布了(《Spark 1.1.0发布:各个模块得到全面升级》、《Spark 1.1.0正式发布》),本博客对Hive部分进行了部分说明:《Spark SQL 1.1.0和Hive的兼容说明》、《Shark迁移到Spark 1.1.0 编程指南》,在这个版本对Hive的支持更加完善了,如果想在Spark SQL中加入Hive,并加入JDBC server和CLI,我们可以在编译的时候通过加上参 w397090770 11年前 (2014-09-17) 18609℃ 8评论10喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 今天我很激动地宣布Spark 1.1.0发布了,Spark 1.1.0引入了许多新特征(new features)包括了可扩展性和稳定性方面的提升。这篇文章主要是介绍了Spark 1.1.0主要的特性,下面的介绍主要是根据各个特征重要性的优先级进行说明的。在接下来的两个星 w397090770 11年前 (2014-09-12) 4722℃ 2评论8喜欢