本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 w397090770 5年前 (2020-11-24) 1203℃ 0评论4喜欢
本文资料来自2020年9月23日举办的 Apache Spark Bogotá 题为《Apache Spark 3.0: Overview of What’s New and Why Care》 的分享。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Spark 3.0 继续坚持更快、更简单、更智能的目标,这个版本解决了3000多个 JIRAs。在这次演讲中,主要和 Bogota Spark 社区分享 Spark 3.0 的 w397090770 5年前 (2020-10-24) 905℃ 0评论3喜欢
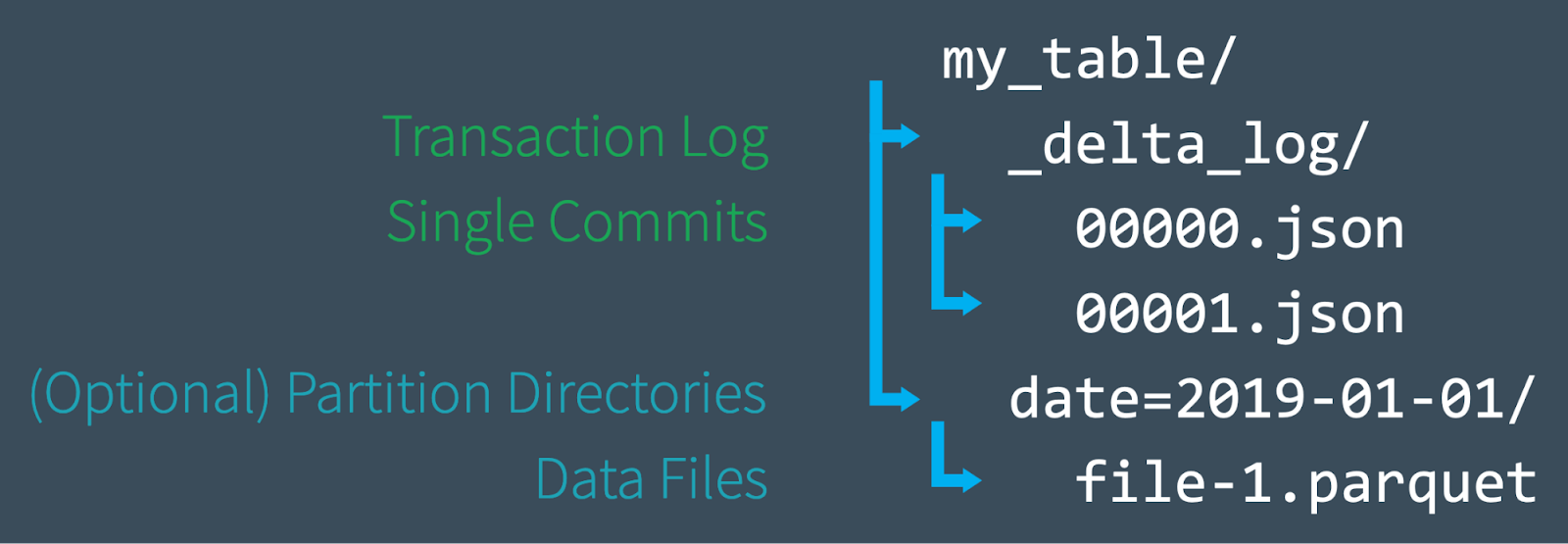
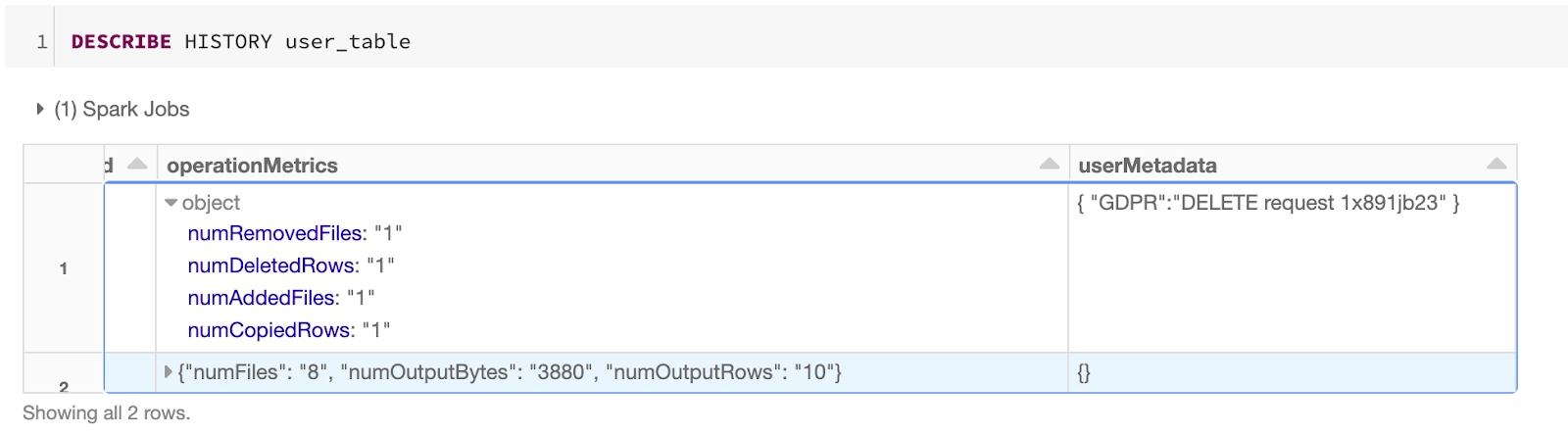
Delta Lake 支持 DML 命令,包括 DELETE, UPDATE, 以及 MERGE,这些命令简化了 CDC、审计、治理以及 GDPR/CCPA 工作流等业务场景。在这篇文章中,我们将演示如何使用这些 DML 命令,并会介绍这些命令的后背实现,同时也会介绍对应命令的一些性能调优技巧。Delta Lake: 基本原理如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 5年前 (2020-10-12) 1678℃ 0评论0喜欢
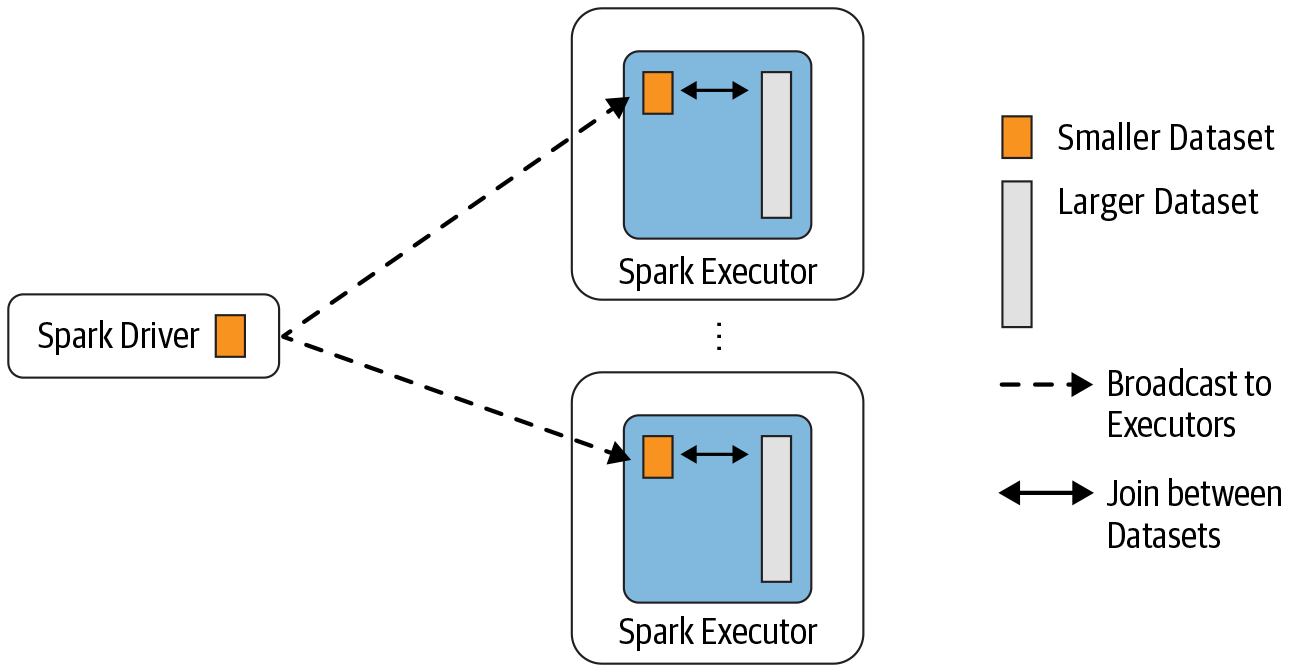
当前 Spark 计算引擎能够利用一些统计信息选择合适的 Join 策略(关于 Spark 支持的 Join 策略可以参见每个 Spark 工程师都应该知道的五种 Join 策略),但是由于各种原因,比如统计信息缺失、统计信息不准确等原因,Spark 给我们选择的 Join 策略不是正确的,这时候我们就可以人为“干涉”,Spark 从 2.2.0 版本开始(参见SPARK-16475),支 w397090770 5年前 (2020-09-15) 3646℃ 0评论3喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划(physical plan)阶段,Spark 的 JoinSelection 类会根据 Join hints 策略、Join 表的大小、 Join 是等值 Join(equi-join) 还是不等值(non-equi-joins)以及参与 Join 的 key 是否可以排序等条件来选择最终的 Join 策略(join strategies),最后 Spark 会利用选择好的 Join 策略执行最 w397090770 5年前 (2020-09-13) 5308℃ 0评论13喜欢
Apache Spark 3.0.0 正式版是2020年6月18日发布的,其为我们带来大量新功能,很多功能加快了数据的计算速度。但是遗憾的是,这个版本并非稳定版。不过就在昨天,Apache Spark 3.0.1 版本悄悄发布了(好像没看到邮件通知)!值得大家高兴的是,这个版本是稳定版,官方推荐所有 3.0 的用户升级到这个版本。Apache Spark 3.0 增加了很多 w397090770 5年前 (2020-09-10) 1315℃ 0评论0喜欢
Delta Lake 0.7.0 是随着 Apache Spark 3.0 版本发布之后发布的,这个版本比较重要的特性就是支持使用 SQL 来操作 Delta 表,包括 DDL 和 DML 操作。本文将详细介绍如何使用 SQL 来操作 Delta Lake 表,关于 Delta Lake 0.7.0 版本的详细 Release Note 可以参见这里。使用 SQL 在 Hive Metastore 中创建表Delta Lake 0.7.0 支持在 Hive Metastore 中定义 Delta 表,而且这 w397090770 5年前 (2020-09-06) 1215℃ 0评论0喜欢
《Learning Spark, 2nd Edition》这本书是由 O'Reilly Media 出版社于2020年7月出版的,作者包括 Jules S. Damji, Brooke Wenig, Tathagata Das, Denny Lee。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书介绍第二版已更新包含了 Spark 3.0 的一些东西,本书向数据工程师和数据科学家展示了 Spark 中结构化和统一 w397090770 5年前 (2020-09-03) 2944℃ 0评论10喜欢
这篇文章本来19年5月份就想写的,最终拖到今天才整理出来😂。Spark 内置给我们带来了非常丰富的各种优化,这些优化基本可以满足我们日常的需求。但是我们知道,现实场景中会有各种各样的需求,总有一些场景在 Spark 得到的执行计划不是最优的,社区的大佬肯定也知道这个问题,所以从 Spark 1.3.0 开始,Spark 为我们提供 w397090770 5年前 (2020-08-05) 1158℃ 2评论3喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop假设我们有以下表:[code lang="scala"]scala> spark.sql("""CREATE TABLE iteblog_test (name STRING, id int) using orc PARTITIONED BY (id)""").show(100)[/code]我们往里面插入一些数据:[code lang="sql"]scala> spark.sql("insert into table iteblog_test select w397090770 5年前 (2020-08-03) 3503℃ 0评论4喜欢