大家在使用Spark、MapReduce 或 Flink 的时候很可能遇到这样一种情况:Hadoop 集群使用的 JDK 版本为1.7.x,而我们自己编写的程序由于某些原因必须使用 1.7 以上版本的JDK,这时候如果我们直接使用 JDK 1.8、或 1.9 来编译我们写好的代码,然后直接提交到 YARN 上运行,这时候会遇到以下的异常:[code lang="java"]Exception in thread "main" jav w397090770 8年前 (2017-07-04) 5578℃ 1评论16喜欢
下面文档是今天早上翻译的,因为要上班,时间比较仓促,有些部分没有翻译,请见谅。2017年06月01日儿童节 Apache Flink 社区正式发布了 1.3.0 版本。此版本经历了四个月的开发,共解决了680个issues。Apache Flink 1.3.0 是 1.x.y 版本线上的第四个主要版本,其 API 和其他 1.x.y 使用 @Public 注释的API是兼容的。此外,Apache Flink 社区目前制 w397090770 8年前 (2017-06-01) 2634℃ 1评论10喜欢
经过一个多月的投票,Apache Flink 1.2.1终于正式发布了。看这个版本就知道,Apache Flink 1.2.1仅仅是对 Flink 1.2.0进行一些Bug修复,不涉及重大的新功能。推荐所有的用户升级到Apache Flink 1.2.1。大家可以在自己项目的pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</art w397090770 8年前 (2017-05-04) 1685℃ 0评论6喜欢
这次整理的PPT来自于2017年04月10日至11日在San Francisco进行的flink forward会议,这种性质的会议和大家熟知的Spark summit类似。本次会议的官方日程参见:http://sf.flink-forward.org/kb_day/day1/。因为原始的PPT是在http://www.slideshare.net/网站,这个网站需要翻墙;为了学习交流的方便,这里收集了本次会议所有课下载的PPT(共27个),希望对大家有所 w397090770 8年前 (2017-04-20) 2825℃ 0评论8喜欢
在Flink中有许多函数需要我们为其指定key,比如groupBy,Join中的where等。如果我们指定的Key不对,可能会出现一些问题,正如下面的程序:[code lang="scala"]package com.iteblog.flinkimport org.apache.flink.api.scala.{ExecutionEnvironment, _}import org.apache.flink.util.Collector///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2017 w397090770 8年前 (2017-03-13) 17038℃ 9评论15喜欢
在Flink中我们可以很容易的使用内置的API来读取HDFS上的压缩文件,内置支持的压缩格式包括.deflate,.gz, .gzip,.bz2以及.xz等。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是如果我们想使用Flink内置sink API将数据以压缩的格式写入到HDFS上,好像并没有找到有API直接支持(如果不是这样的, w397090770 8年前 (2017-03-02) 10479℃ 0评论6喜欢
大多数刚刚使用Apache Flink的人很可能在编译写好的程序时遇到如下的错误:[code lang="bash"]Error:(15, 26) could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.TypeInformation[Int] socketStockStream.map(_.toInt).print() ^[/code]如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteb w397090770 8年前 (2017-03-01) 4336℃ 9喜欢
Learning Apache Flink又名Mastering Apache Flink,是由Tanmay Deshpande所著,2017年02月在Packt出版,全书共280页。这本书是学习Apache Flink进行批处理和流数据处理的入门指南。本书首先介绍Apache Flink生态系统,然后介绍如何设置Apache Flink,并使用DataSet和DataStream API分别处理静态数据和流数据。本书将探讨如何在数据集上使用Table API。在本书的 zz~~ 9年前 (2017-02-24) 16440℃ 0评论19喜欢
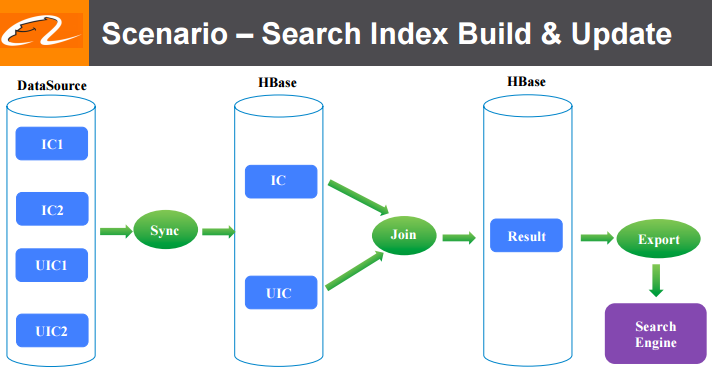
阿里巴巴是世界上最大的电子商务零售商。 我们在2015年的年销售额总计3940亿美元,超过eBay和亚马逊之和。阿里巴巴搜索(个性化搜索和推荐平台)是客户的关键入口,并承载了大部分在线收入,因此搜索基础架构团队需要不断探索新技术来改进产品。 在电子商务网站应用场景中,什么能造就一个强大的搜索引擎?答案 w397090770 9年前 (2017-02-16) 7039℃ 0评论6喜欢
Introduce Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。 容错机制通过持续创建分布式数据流的快照来实现。对于状态占用空间小的流应用,这些快照非常轻量,可以高频率创建而对性能影 zz~~ 9年前 (2017-02-08) 4612℃ 0评论7喜欢






![[电子书]Learning Apache Flink PDF下载](https://www.iteblog.com/pic/flink/Mastering_Apache_Flink_iteblog.png)