背景我们基于 Apache Hadoop® 的数据平台以最小的延迟支持了数百 PB 的分析数据,并将其存储在基于 HDFS 之上的数据湖中。我们使用 Apache Hudi™ 作为我们表的维护格式,使用 Apache Parquet™ 作为底层文件格式。我们的数据平台利用 Apache Hive™、Apache Presto™ 和 Apache Spark™ 进行交互和长时间运行的查询,满足 Uber 不同团队的各种需求。 w397090770 3年前 (2022-03-13) 2576℃ 0评论1喜欢
数据处理现状:当前基于Hive的离线数据仓库已经非常成熟,数据中台体系也基本上是围绕离线数仓进行建设。但是随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,业界最近几年就一直聚焦并探索于两个相关的热点问题:实时数仓建设和大数据架构的批流一体建设。实时数仓建设:实时数仓1.0 传统 w397090770 3年前 (2022-02-18) 780℃ 0评论2喜欢
本次的分享内容分成四个部分: 1.汽车之家离线计算平台现状2.平台构建过程中遇到的问题3.基于构建过程中问题的解决方案4.离线计算平台未来规划 汽车之家离线计算平台现状 1. 汽车之家离线计算平台发展历程如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 2013年的时候汽 w397090770 3年前 (2021-08-30) 612℃ 0评论4喜欢
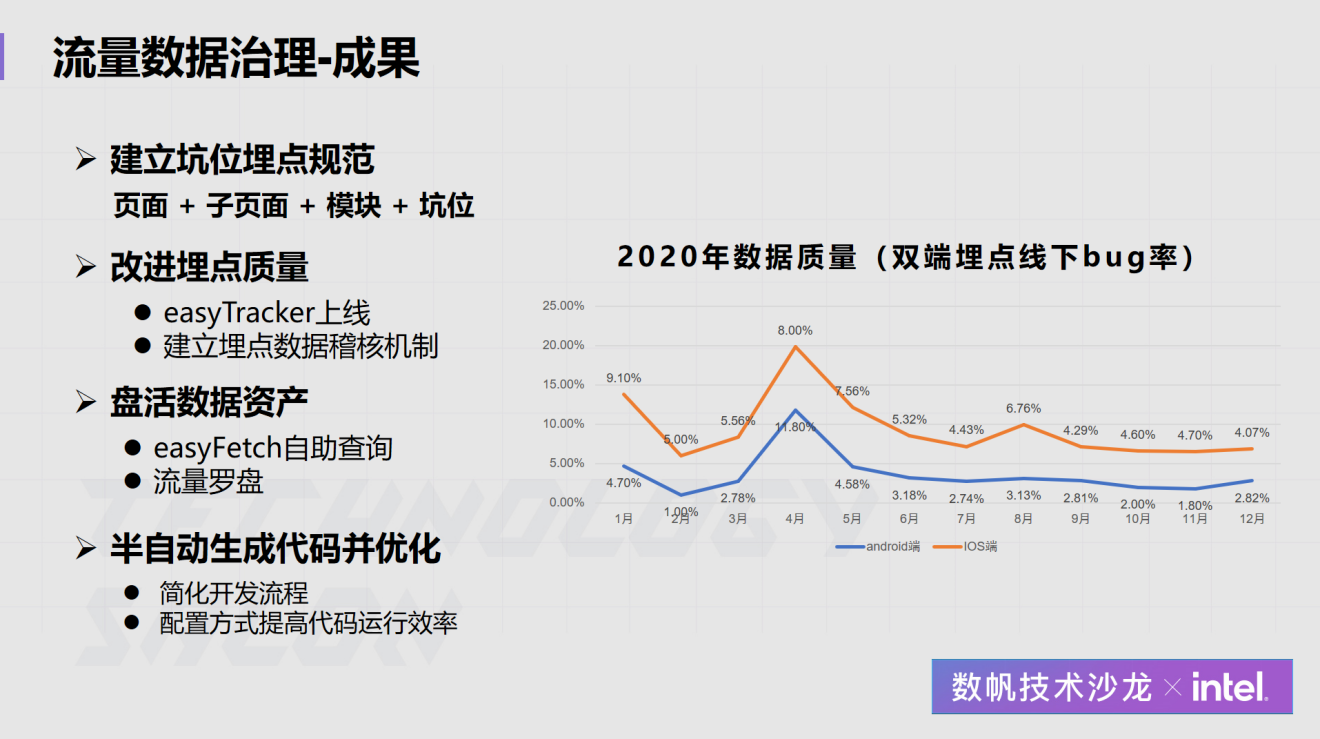
网易云音乐作为一个MAU已经超过亿级的业务,在数据仓库、数据体系、数据应用建设是怎么做的?在近日举办的“网易数帆技术沙龙”上,网易云音乐数据专家雷剑波就此话题做了全面的分享,介绍了数仓建设的目标,为此建立的一系列规范和机制,如何通过系统保证这些规范和机制的落地,以及取得的效果。数仓建设痛点与目 w397090770 4年前 (2021-06-30) 1008℃ 0评论1喜欢
作者:小君,部门:技术中台/数据中台前言随着实时技术的不断发展和商家实时应用场景的不断丰富,有赞在实时数仓建设方面做了大量的尝试和实践。本文主要分享有赞在建设实时数仓过程中所沉淀的经验,内容包括以下五个部分: 建设背景 应用场景 方案设计 项目应用 未来展望建设背景 实时需求日趋迫 zz~~ 4年前 (2021-06-10) 386℃ 0评论0喜欢
背景数据湖(Data Lake),湖仓一体(Data Lakehouse)俨然已经成为了大数据领域最为火热的流行词,在接受这些流行词洗礼的时候,身为技术人员我们往往会发出这样的疑问,这是一种新的技术吗,还是仅仅只是概念上的翻新(新瓶装旧酒)呢?它到底解决了什么问题,拥有什么样新的特性呢?它的现状是什么,还存在什么问题呢? w397090770 4年前 (2020-11-28) 5736℃ 0评论7喜欢
我们使用数据库可以快速访问业务数据,但是随着时间的推移,数据库会不断增长,提取信息所需的时间也会更长,数据操作成为瓶颈。这时候我们就需要对数据进行分区(partition)了。分区是将数据库或其组成元素划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性或负载平衡的原因而进行的。在分布式数据 w397090770 5年前 (2020-05-14) 1093℃ 0评论2喜欢