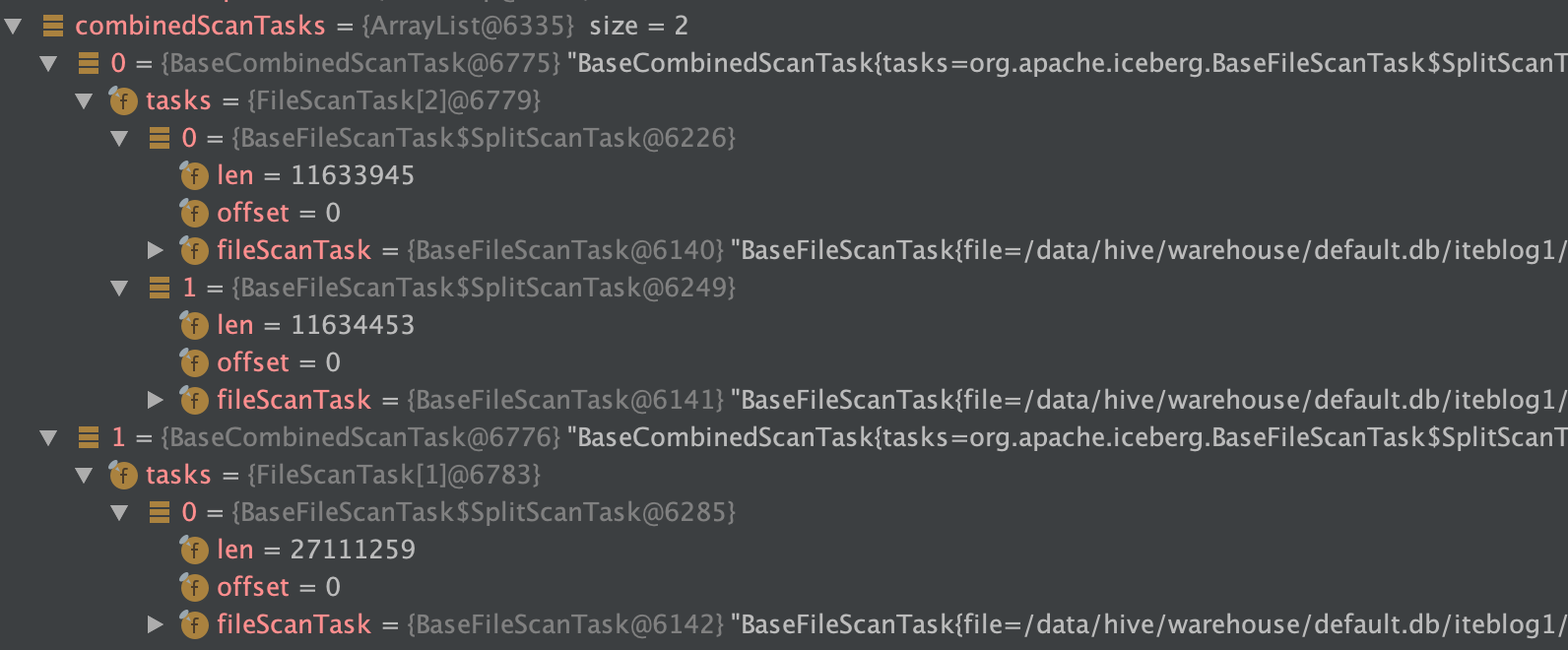
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。
Apache Iceberg 的底层数据组织
我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache I
w397090770
5年前 (2020-11-29) 3910℃ 0评论
5喜欢
在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中我们分析了 Apache Iceberg 写数据的源码。如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局(测试代码在 这里):
[code lang="bash"]
/data/hive/warehouse/default.db/iteblog
├── data
│ └── ts_year=2020
│ ├── id_bucket=0
│ │ ├── 00000-0-19603f5a-d38a
w397090770
5年前 (2020-11-20) 7318℃ 6评论
8喜欢
本文基于 Apache Iceberg 0.9.0 最新分支,主要分析 Apache Iceberg 中使用 Spark 2.4.6 来写数据到 Iceberg 表中,也就是对应 iceberg-spark2 模块。当然,Apache Iceberg 也支持 Flink 来读写 Iceberg 表,其底层逻辑也 Spark 类似,感兴趣的同学可以去看看。
使用 Spark2 将数据写到 Apache Iceberg
在介绍下面文章之前,我们先来看下在 Apache Spark 2.4.6 中写数
w397090770
5年前 (2020-11-12) 6411℃ 0评论
9喜欢