2010年,Facebook 的工程师在 ICDC(IEEE International Conference on Data Engineering) 发表了一篇 《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》 的论文,介绍了其为基于 MapReduce 的数据仓库设计的高效存储结构,这就是我们熟知的 RCFile(Record Columnar File)。下面介绍 RCFile 的一些诞生背景和设计。背景早在2010 w397090770 5年前 (2020-06-16) 1430℃ 0评论8喜欢
我已经在之前的 《一条 SQL 在 Apache Spark 之旅(上)》、《一条 SQL 在 Apache Spark 之旅(中)》 以及 《一条 SQL 在 Apache Spark 之旅(下)》 这三篇文章中介绍了 SQL 从用户提交到最后执行都经历了哪些过程,感兴趣的同学可以去这三篇文章看看。这篇文章中我们主要来介绍 SQL 查询计划(Query Plan)常见的处理模型(processing model)。数 w397090770 5年前 (2020-05-13) 1842℃ 0评论6喜欢
OpenCSVSerde 使用大家使用 Hive 分析数据的时候,CSV 格式的数据应该是很常见的,所以从 0.14.0 开始(参见 HIVE-7777) Hive 跟我们提供了原生的 OpenCSVSerde 来解析 CSV 格式的数据。从名字可以看出,OpenCSVSerde 是基于 Open-CSV 2.3 类库实现的,其解析 csv 的功能还是很强大的。为了在 Hive 中使用这个 serde,我们需要在建表的时候指定 row form w397090770 5年前 (2020-05-04) 2013℃ 0评论4喜欢
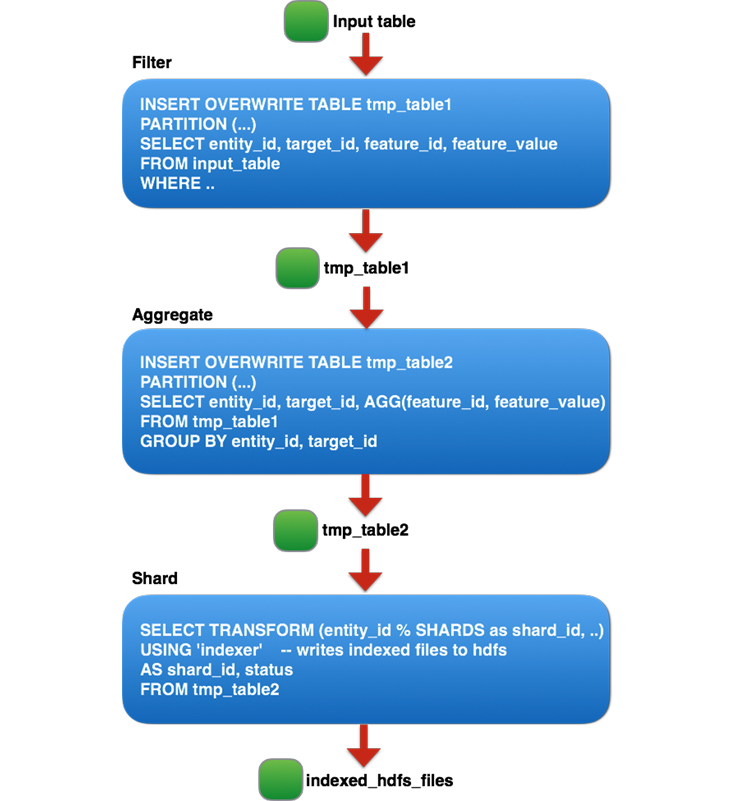
Facebook 经常使用分析来进行数据驱动的决策。在过去的几年里,用户和产品都得到了增长,使得我们分析引擎中单个查询的数据量达到了数十TB。我们的一些批处理分析都是基于 Hive 平台(Apache Hive 是 Facebook 在2009年贡献给社区的)和 Corona( Facebook 内部的 MapReduce 实现)进行的。Facebook 还针对包括 Hive 在内的多个内部数据存储,继续 w397090770 6年前 (2019-12-19) 1914℃ 0评论10喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 6年前 (2019-09-23) 12636℃ 0评论34喜欢
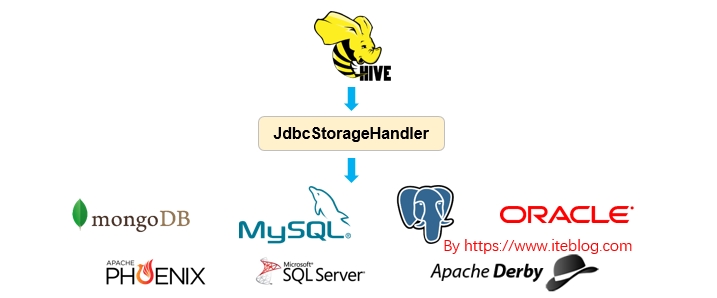
Apache Hive 从 HIVE-1555 开始引入了 JdbcStorageHandler ,这个使得 Hive 能够读取 JDBC 数据源,关于 Apache Hive 引入 JdbcStorageHandler 的背景可以参见 《Apache Hive 联邦查询(Query Federation)》。本文主要简单介绍 JdbcStorageHandler 的使用。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop语法JdbcStorageHandler 使 w397090770 6年前 (2019-04-01) 3714℃ 0评论9喜欢
Hive内部提供了很多操作字符串的相关函数,本文将对其中部分常用的函数进行介绍。下表为Hive内置的字符串函数,具体的用法可以参见本文的下半部分。返回类型函数名描述intascii(string str)返回str第一个字符串的数值stringbase64(binary bin)将二进制参数转换为base64字符串 w397090770 9年前 (2016-04-24) 116589℃ 91喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事在《Hive内置数据类型》文章中,我们提到了Hive w397090770 12年前 (2014-01-07) 139723℃ 1评论690喜欢
在Hive0.8开始支持Insert into语句,它的作用是在一个表格里面追加数据。标准语法语法如下:[code lang="sql"]用法一:INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;用法二:INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;[/code w397090770 12年前 (2013-10-30) 102474℃ 2评论71喜欢