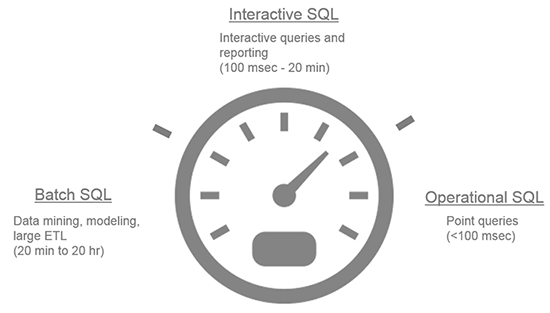
以下文章是转载自国外网站,介绍了Hadoop生态系统上面的几种SQL:Hive、Drill、Impala、Presto以及Spark\Shark等应用场景、对比以及一些结论Within the big data landscape there are multiple approaches to accessing, analyzing, and manipulating data in Hadoop. Each depends on key considerations such as latency, ANSI SQL completeness (and the ability to tolerate machine-generated SQL), developer and a w397090770 11年前 (2014-08-11) 10037℃ 0评论14喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 11年前 (2014-07-15) 92553℃ 0评论164喜欢
Spark和Flume-ng整合,可以参见本博客:《Spark和Flume-ng整合》《使用Spark读取HBase中的数据》如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 大家可能都知道很熟悉Spark的两种常见的数据读取方式(存放到RDD中):(1)、调用parallelize函数直接从集合中获取数据,并存入RDD中;Java版本如 w397090770 11年前 (2014-06-29) 75184℃ 47评论58喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复之后才可见的内容!!请大家不要介意,本博 w397090770 11年前 (2014-05-13) 14266℃ 30评论3喜欢
Shark是一种分布式SQL查询工具,它的设计目标就是兼容Hive,今天就来总结一下Shark对Hive特性的兼容。 一、Shark可以直接部署在Hive的数据仓库上。支持Hive的绝大多数特性,具体如下: Hive查询语句,包括以下: SELECT GROUP_BY ORDER_BY CLUSTER_BY SORT_BY 支持Hive中所有的操作符: 关系运算符(=, ⇔, ==, <>, <, & w397090770 11年前 (2014-04-30) 7411℃ 1评论4喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 12年前 (2014-01-28) 7346℃ 2评论2喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 12年前 (2014-01-27) 5177℃ 1评论1喜欢
经过三个多月,发现自己已经写了好几篇关于常用Hadoop生态圈分布式安装的文章,比如Hadoop、Hive、Zookeeper、Hbase等软件的分布式安装,今天就汇总一下吧,这样也方便大家查阅,如果发现里面有任何错误可以邮件联系我(wyphao.2007@163.com)或者直接在相应文章里面留言,我会及时更正。 1、Hadoop-2.2.0伪分布式安装:《在Fedora w397090770 12年前 (2014-01-26) 7001℃ 1评论8喜欢
在本博客的《Flume-1.4.0和Hbase-0.96.0整合》我们已经学习了如何使用Flume-1.4.0和Hbase-0.96.0进行整合。我们可以很容易的配置Hbase sink,并和最新版的Hbase整合,但是由于项目的特殊情况,我需要将Flume-0.9.4和Hbase-0.96整合,搞过这个的人应该知道,Flume-0.9.4和Hbase-0.96非常棘手,各种版本的不兼容等情况,最终通过我和同事的两天奋战 w397090770 12年前 (2014-01-25) 7204℃ 1评论2喜欢
最近由于项目需要把Flume收集到的日志信息插入到Hbase中,由于第一次接触这些,在整合的过程中,我遇到了许多问题,我相信很多人也应该会遇到这些问题的,于是我把整个整合的过程写出来,希望给那些同样遇到这样问题的朋友帮助。 在使用Flume的时候,请确保你电脑里面已经搭建好Hadoop、Hbase、Zookeeper以及Flume。本文 w397090770 12年前 (2014-01-21) 11348℃ 6评论1喜欢