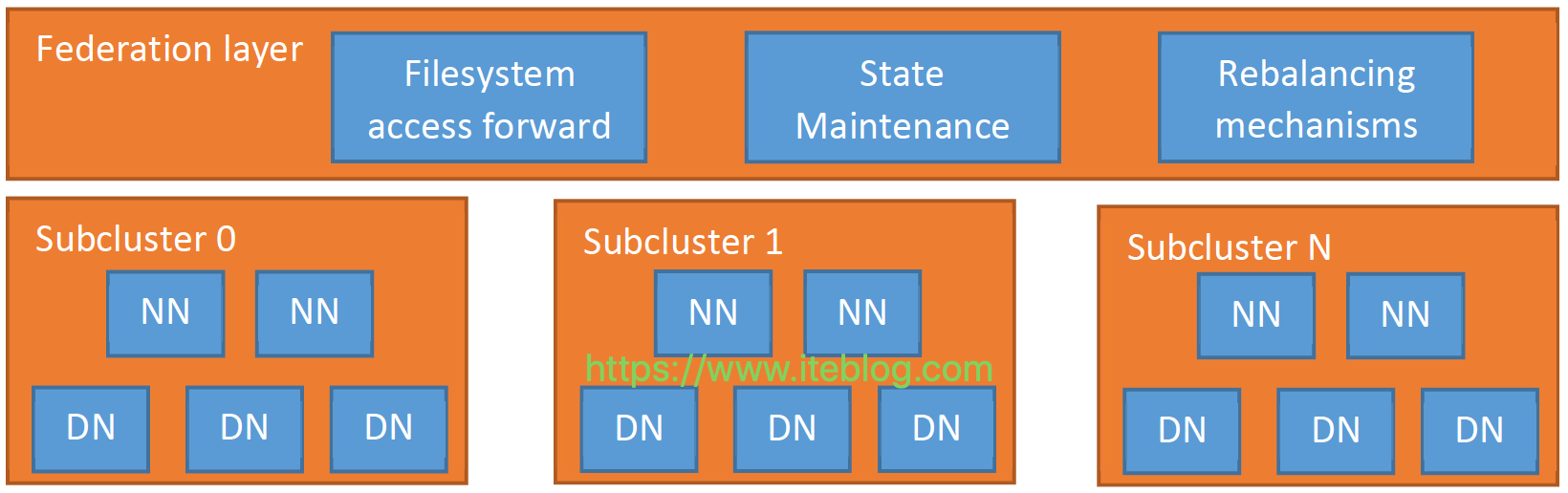
在 《Apache Hadoop 的 HDFS federation 前世今生(上)》 已经介绍了 Hadoop 2.9.0 版本之前 HDFS federation 存在的问题,那么为了解决这个问题,社区采取了什么措施呢?HDFS Router-based FederationViewFs 方案虽然可以很好的解决文件命名空间问题,但是它的实现有以下几个问题:ViewFS 是基于客户端实现的,需要用户在客户端进行相关的配置,那 w397090770 6年前 (2019-07-26) 2112℃ 0评论2喜欢
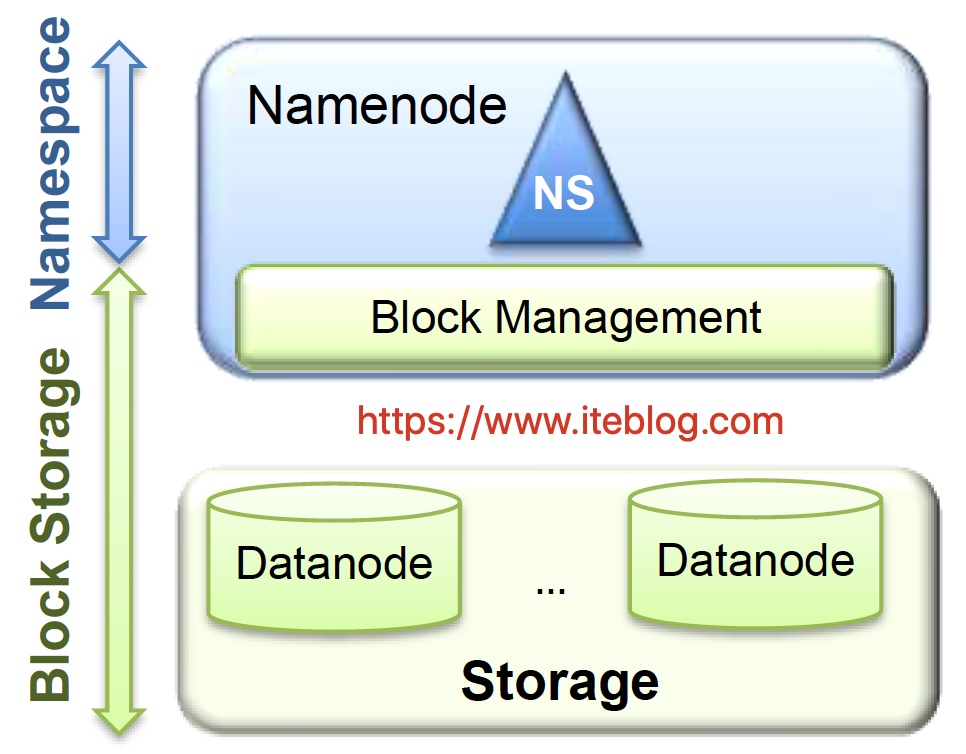
背景熟悉大数据的人应该都知道,HDFS 是一个分布式文件系统,它是基于谷歌的 GFS 思路实现的开源系统,它的设计目的就是提供一个高度容错性和高吞吐量的海量数据存储解决方案。在经典的 HDFS 架构中有2个 NameNode 和多个 DataNode 的,如下:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop从 w397090770 6年前 (2019-07-25) 2313℃ 0评论3喜欢
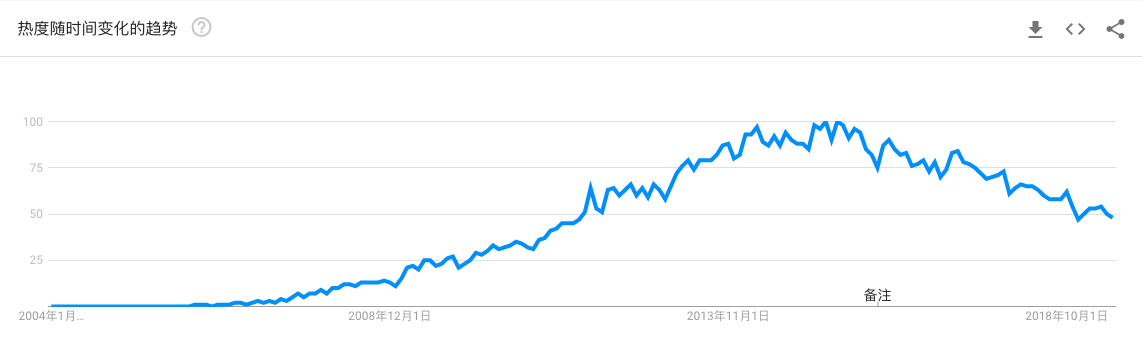
Hadoop我先从一个悲观的观点说起:Hadoop 正在迅速失去市场,我们可以从 Google 趋势走向看出这个现象:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面的炒作生命周期表也上面的趋势很类似:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop看起来 Hadoo w397090770 6年前 (2019-06-23) 3706℃ 0评论32喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 6年前 (2019-06-06) 3393℃ 0评论8喜欢
前两篇文章,《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 和 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 分别介绍了两种方法读取加盐之后的 HBase 表。本文将介绍如何在 MapReduce 读取加盐之后的表。在 MapReduce 中也可以使用 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 文章里面的 SaltRangeTableInputForm w397090770 6年前 (2019-02-27) 2984℃ 0评论7喜欢
本文来自 submarine 团队投稿。作者: Wangda Tan & Sunil Govindan & Zhankun Tang(这篇博文由网易的刘勋和周全协助编写)。原文地址:https://hortonworks.com/blog/submarine-running-deep-learning-workloads-apache-hadoop/介绍Hadoop 是用于大型企业数据集的分布式处理的最流行的开源框架,它在本地和云端环境中都有很多重要用途。深度学习对于语 w397090770 7年前 (2019-01-01) 4191℃ 0评论4喜欢
HDFS 快照是从 Hadoop 2.1.0-beta 版本开始引入的新功能,详见 HDFS-2802。概述HDFS 快照(HDFS Snapshots)是文件系统在某个时间点的只读副本。可以在文件系统的子树或整个文件系统上创建快照。快照的常见用途主要包括数据备份,防止用户误操作和容灾恢复。HDFS 快照的实现非常高效:快照的创建非常迅速:除去 inode 的查找时间, w397090770 7年前 (2018-12-02) 2204℃ 0评论3喜欢
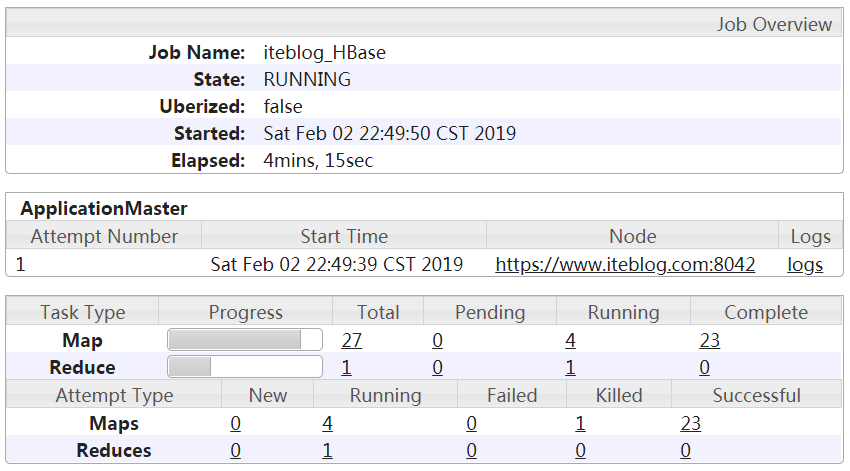
我们知道,HDFS 被设计成存储大规模的数据集,我们可以在 HDFS 上存储 TB 甚至 PB 级别的海量数据。而这些数据的元数据(比如文件由哪些块组成、这些块分别存储在哪些节点上)全部都是由 NameNode 节点维护,为了达到高效的访问, NameNode 在启动的时候会将这些元数据全部加载到内存中。而 HDFS 中的每一个文件、目录以及文件块, w397090770 7年前 (2018-10-09) 9450℃ 2评论31喜欢
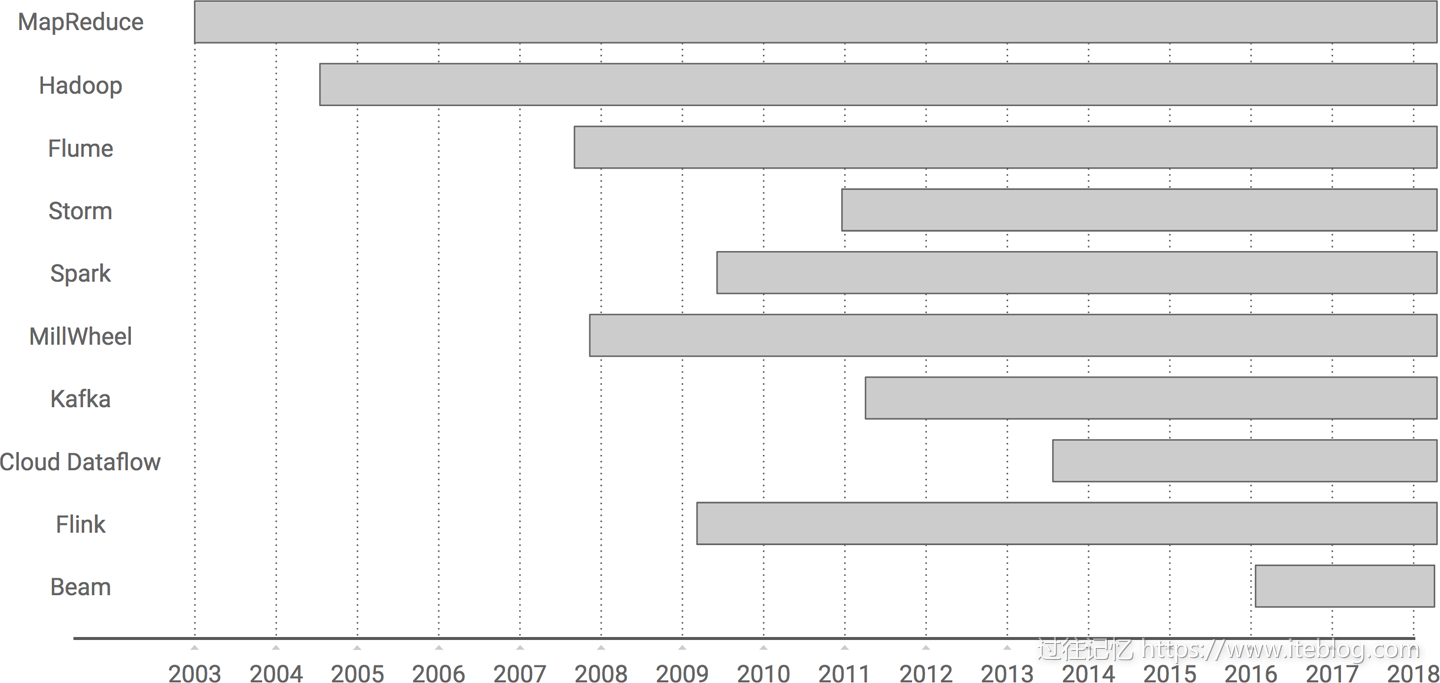
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 7年前 (2018-10-08) 10427℃ 2评论27喜欢
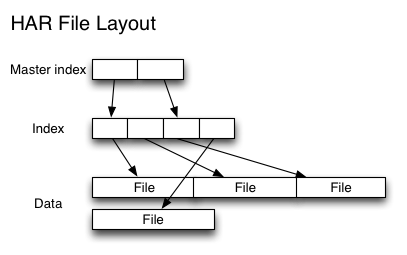
概述Hadoop archives 是特殊的档案格式。一个 Hadoop archive 对应一个文件系统目录。 Hadoop archive 的扩展名是 *.har。Hadoop archive 包含元数据(形式是 _index 和 _masterindx)和数据(part-*)文件。_index 文件包含了档案中文件的文件名和位置信息。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如何 w397090770 7年前 (2018-09-17) 2152℃ 0评论1喜欢