Hadoop的一大基本原则是移动计算的开销要比移动数据的开销小。因此,Hadoop通常是尽量移动计算到拥有数据的节点上。这就使得Hadoop中读取数据的客户端DFSClient和提供数据的Datanode经常是在一个节点上,也就造成了很多“Local Reads”。最初设计的时候,这种Local Reads和Remote Reads(DFSClient和Datanode不在同一个节点)的处理方式都是一 w397090770 7年前 (2018-07-22) 152℃ 0评论0喜欢
在 《HDFS 块和 Input Splits 的区别与联系》 文章中介绍了HDFS 块和 Input Splits 的区别与联系,其中并没有涉及到源码级别的描述。为了补充这部分,这篇文章将列出相关的源码进行说明。看源码可能会比直接看文字容易理解,毕竟代码说明一切。为了简便起见,这里只描述 TextInputFormat 部分的读取逻辑,关于写 HDFS 块相关的代码请参 w397090770 7年前 (2018-05-16) 2420℃ 0评论19喜欢
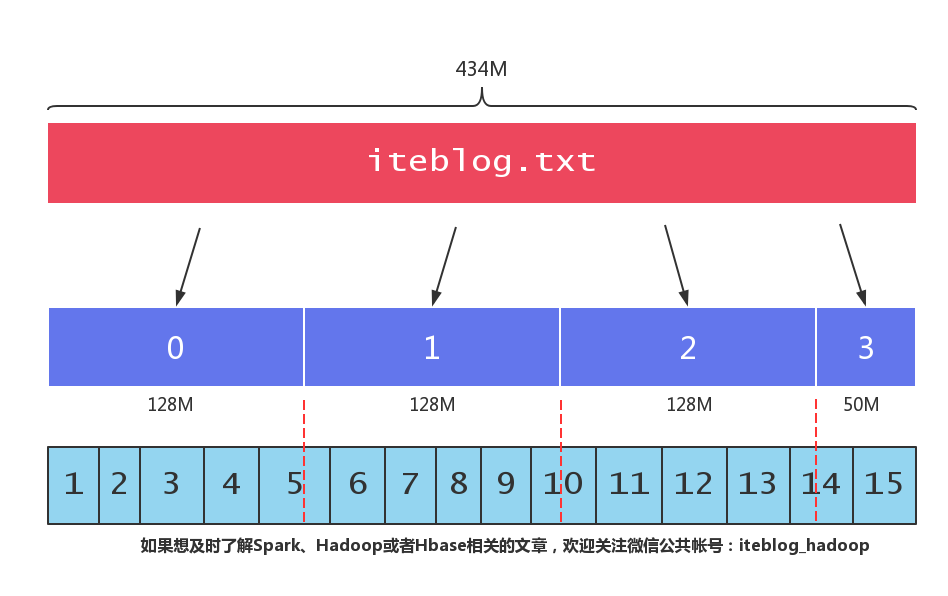
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 7年前 (2018-05-16) 2737℃ 4评论28喜欢
4月6日,Apache Hadoop 3.1.0 正式发布了,Apache Hadoop 3.1.0 是2018年 Hadoop-3.x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,这个版本并不推荐在生产环境下使用,如果需要在正式环境下使用,请等待 3.1.1 或 3.1.2 版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop这个版 w397090770 7年前 (2018-04-08) 3659℃ 0评论15喜欢
在 HDFS 中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。当 w397090770 7年前 (2018-03-28) 5415℃ 3评论24喜欢
我们每天都可能会操作 HDFS 上的文件,这就很难避免误操作,比如比较严重的误操作就是删除文件。本文针对这个问题提供了三种恢复误删除文件的方法,希望对大家的日常运维有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop通过垃圾箱恢复HDFS 为我们提供了垃圾箱的功能, w397090770 8年前 (2018-01-14) 10276℃ 2评论23喜欢
今天凌晨 Apache Hadoop 3.0.0 GA 版本正式发布,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!这个版本是 Apache Hadoop 3.0.0 的第一个稳定版本,有很多重大的改进,比如支持 EC、支持多于2个的NameNodes、Intra-datanode均衡器等等。下面是关于 Apache Hadoop 3.0.0 GA 的正式介绍。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微 w397090770 8年前 (2017-12-15) 3546℃ 1评论38喜欢
就在前几天,Apache Hadoop 3.0.0-beta1 正式发布了,这是3.0.0的第一个 beta 版本。本版本基于 3.0.0-alpha4 版本进行了Bug修复、性能提升以及其他一些加强。好消息是,这个版本之后会正式发行 Apache Hadoop 3.3.0 GA(General Availability,正式发布的版本)版本,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!目前预计 Apache Hadoop 3.3.0 GA 将会在 201 w397090770 8年前 (2017-10-11) 2325℃ 0评论15喜欢
每个 NodeManager 节点内置提供了检测自身健康状态的机制(详情参见 NodeHealthCheckerService);通过这种机制,NodeManager 会将诊断出来的监控状态通过心跳机制汇报给 ResourceManager,然后ResourceManager 端会通过 RMNodeEventType.STATUS_UPDATE 更新 NodeManager 的状态;如果此时的 NodeManager 节点不健康,那么 ResourceManager 将会把 NodeManager 状态变为 NodeState w397090770 8年前 (2017-06-08) 4355℃ 0评论18喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 8年前 (2017-06-07) 3681℃ 0评论21喜欢