下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 112.19.121.141 8123 高匿名 HTTP 9年前 (2015-05-15) 23774℃ 0评论5喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 122.246.148.77 8090 高匿名 HTTP 浙 9年前 (2015-05-15) 41078℃ 0评论0喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 9年前 (2015-05-15) 4779℃ 0评论3喜欢
如果你想知道Hadoop作业运行日志,可以查看这里《Hadoop日志存放路径详解》 在很多情况下,我们需要查看driver和executors在运行Spark应用程序时候产生的日志,这些日志对于我们调试和查找问题是很重要的。 Spark日志确切的存放路径和部署模式相关: (1)、如果是Spark Standalone模式,我们可以直接在Master UI界 9年前 (2015-05-14) 39496℃ 6评论16喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 125.117.130.174 9000 高匿名 HTTP 9年前 (2015-05-13) 46325℃ 0评论0喜欢
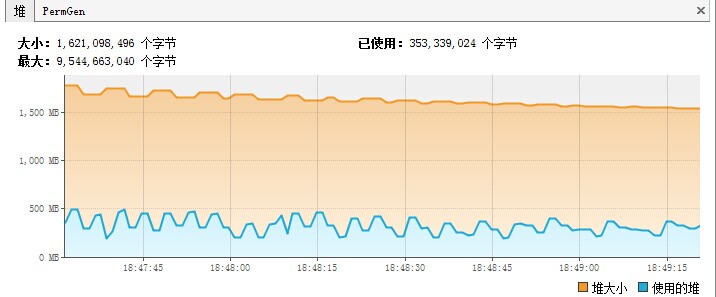
jvisualvm工具JDK自带的一个监控工具,该工具是用来监控java运行程序的cpu、内存、线程等的使用情况,并且使用图表的方式监控java程序、还具有远程监控能力,不失为一个用来监控Java程序的好工具。 同样,我们可以使用jvisualvm来监控Spark应用程序(Application),从而可以看到Spark应用程序堆,线程的使用情况,从而根据这 9年前 (2015-05-13) 10648℃ 0评论9喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 139.226.113.238 8090 高匿名 HTTP 9年前 (2015-05-12) 13654℃ 0评论1喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 117.162.225.199 8123 高匿名 HTTP 江西 9年前 (2015-05-12) 34987℃ 0评论3喜欢
在本博客的《Spark Metrics配置详解》文章中介绍了Spark Metrics的配置,其中我们就介绍了Spark监控支持Ganglia Sink。Ganglia是UC Berkeley发起的一个开源集群监视项目,主要是用来监控系统性能,如:cpu 、mem、硬盘利用率, I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性 9年前 (2015-05-11) 13789℃ 1评论13喜欢
在提交作业的时候出现了以下的异常信息:[code lang="scala"]2015-05-05 11:09:28,071 INFO [Driver] - Attempting to load checkpoint from file hdfs://iteblogcluster/user/iteblog/checkpoint2/checkpoint-14307949860002015-05-05 11:09:28,076 WARN [Driver] - Error reading checkpoint from file hdfs://iteblogcluster/user/iteblog/checkpoint2/checkpoint-1430794986000java.io.InvalidClassException: org.apache.spark.streaming 9年前 (2015-05-10) 18729℃ 0评论7喜欢