Apache Spark社区刚刚发布了1.5版本,大家一定想知道这个版本的主要变化,这篇文章告诉你答案。DataFrame执行后端优化(Tungsten第一阶段) DataFrame可以说是整个Spark项目最核心的部分,在1.5这个开发周期内最大的变化就是Tungsten项目的第一阶段已经完成。主要的变化是由Spark自己来管理内存而不是使用JVM,这样可以避免JVM 9年前 (2015-09-09) 4778℃ 0评论14喜欢
Spark 1.5.0是1.x线上的第6个发行版。这个版本共处理了来自230+contributors和80+机构的1400+个patches。Spark 1.5的许多改变都是围绕在提升Spark的性能、可用性以及操作稳定性。Spark 1.5.0焦点在Tungsten项目,它主要是通过对低层次的组建进行优化从而提升Spark的性能。Spark 1.5版本为Streaming增加了operational特性,比如支持backpressure。另外比较重 9年前 (2015-09-09) 2975℃ 0评论12喜欢
基于社区开发者们的观察,绝大多数的Spark应用程序的瓶颈不在于I/O或者网络,而在于CPU和内存。基于这个事实,开发者们发起了Tungsten项目,而Spark 1.5是Tungsten项目的第一阶段。Tungsten项目主要集中在三个方面,于此来提高Spark应用程序的内存和CPU的效率,使得性能能够接近硬件的限制。Tungsten项目的三个阶段内存管理和二 9年前 (2015-09-09) 7293℃ 0评论5喜欢
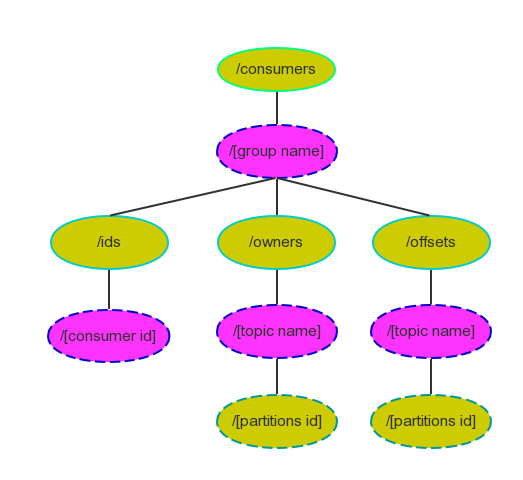
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》High Level Consumer 很多时候,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理。同时也希望提供一些语义,例如同 9年前 (2015-09-08) 9620℃ 0评论22喜欢
北京第九次Spark Meetup活动于2015年08月22日下午14:00-18:00在北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼进行。活动内容如下: 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and Apache Zeppelin committer 3、《Apache Kylin introductio 9年前 (2015-09-04) 2636℃ 0评论4喜欢
我们在《Tachyon 0.7.0伪分布式集群安装与测试》文章中介绍了如何搭建伪分布式Tachyon集群。从官方文档得知,Spark 1.4.x和Tachyon 0.6.4版本兼容,而最新版的Tachyon 0.7.1和Spark 1.5.x兼容,目前最新版的Spark为1.4.1,所以下面的操作步骤全部是基于Tachyon 0.6.4平台的,Tachyon 0.6.4的搭建步骤和Tachyon 0.7.0类似。 废话不多说,开始介绍吧 9年前 (2015-08-31) 5447℃ 0评论6喜欢
先说明一下,这里说的Hive on Spark是Hive跑在Spark上,用的是Spark执行引擎,而不是MapReduce,和Hive on Tez的道理一样。 从Hive 1.1版本开始,Hive on Spark已经成为Hive代码的一部分了,并且在spark分支上面,可以看这里https://github.com/apache/hive/tree/spark,并会定期的移到master分支上面去。关于Hive on Spark的讨论和进度,可以看这里https:// 9年前 (2015-08-31) 41686℃ 30评论43喜欢
animate.css是一系列很酷的、有趣的以及跨浏览器的动画库,你可以在你的项目在红引入这个动画库。使用animate.css方式也非常简单,我们只需要在页面上引入animate.css文件,如下:[code lang="css"]<head> <link rel="stylesheet" href="animate.min.css"></head>[/code] 然后在你想动的元素上加上animated class。你 9年前 (2015-08-28) 3210℃ 0评论3喜欢
上海Spark Meetup第六次聚会将于2015年08月08日下午1:30 PM to 5:00 PM在上海市杨浦云计算创新基地发展有限公司举办,详细地址上海市杨浦区伟德路6号云海大厦13楼。本次聚会由Intel举办。大会主题主讲题目:Tachyon: 内存为中心可容错的分布式存储系统 摘要:在越来越多的大数据应用场景诸如机器学习,数据分析等, 内存成 9年前 (2015-08-28) 4444℃ 0评论1喜欢
Spark SQL主要目的是使得用户可以在Spark上使用SQL,其数据源既可以是RDD,也可以是外部的数据源(比如Parquet、Hive、Json等)。Spark SQL的其中一个分支就是Spark on Hive,也就是使用Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。本文就是来介绍如何通过Spark SQL来 9年前 (2015-08-27) 74575℃ 19评论38喜欢