

文章目录
本文是《Apache Iceberg 源码解析》专题的第 2 篇,共 3 篇:
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。
Apache Iceberg 的底层数据组织
我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache Iceberg 的写流程,我们在那篇文章最开始的测试案例中提到了写完数据之后在磁盘的文件目录结构;但当时并没有详细的介绍这些文件之间的关联以及用途。本篇文章我们将详细的介绍这些文件的组织关系以及用途,不过在这之前,我们需要先了解一下 Apache Iceberg 关于底层数据结构的一些术语。
Apache Iceberg 用到的一些术语
数据文件(data files)
数据文件(data files)是 Apache Iceberg 表真实存储数据的文件,一般是在表的数据存储目录的 data 目录下。如果我们的文件格式选择的是 parquet,那么文件是以 .parquet 结尾,比如 00000-0-0eca9076-9c03-4077-baa9-e68769e15c58-00001.parquet 就是一个数据文件。
每次更新会产生多个数据文件。
清单文件(Manifest file)
清单文件其实是元数据文件,其里面列出了组成某个快照(snapshot)的数据文件列表。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据的行数等信息。其中列级别的统计信息在 Scan 的时候可以为算子下推提供数据,以便可以过滤掉不必要的文件。
清单文件是以 avro 格式进行存储的,所以是以 .avro 后缀结尾的,比如 d5ba704c-1453-4f18-9077-6944baa1b3f2-m0.avro。
每次更新会产生多个清单文件。
清单列表(Manifest list)
清单列表也是元数据文件,其里面存储的是清单文件的列表,每个清单文件占据一行。每行中存储了清单文件的路径、清单文件里面存储数据文件的分区范围、增加了几个数据文件、删除了几个数据文件等信息。这些信息可以用来在查询时提供过滤。
清单列表也是 avro 格式进行存储的,所以是以 .avro 后缀结尾的;而且这个文件是以 snap- 开头的,比如 snap-7389540589641972921-1-aa90f6ed-aee2-49c7-a61c-bd13ed411c66.avro,其中 7389540589641972921 这串数字是代表快照 id(snapshot_id)。
每次更新都会产生一个清单列表文件。
快照(Snapshot)
快照代表一张表在某个时刻的状态。每个快照里面会列出表在某个时刻的所有数据文件列表。Data files 是存储在不同的 manifest files 里面, manifest files 是存储在一个 Manifest list 文件里面,而一个 Manifest list 文件代表一个快照。
Apache Iceberg 表的数据组织
前面我们已经介绍了 Apache Iceberg 的常用术语,有了这些知识,我们就可以看懂一张 Iceberg 表的底层数据结构组织。比如下面的目录结构是某一张表在某个时刻的状态:
iteblog@iteblog :/data/hive/warehouse/iteblog|
⇒ tree
.
├── data
│ └── ts_year=2020
│ └── id_bucket=0
│ ├── 00000-0-0eca9076-9c03-4077-baa9-e68769e15c58-00001.parquet
│ ├── 00000-0-2b289c49-c807-4187-ac8c-8d74c674d577-00001.parquet
│ ├── 00000-0-e114f45e-5431-409e-9c00-67bb39f21918-00001.parquet
│ ├── 00001-1-259dfb2b-10f5-41dc-a0fb-6bc7f890a28a-00001.parquet
│ ├── 00001-1-7353eecc-2306-4eea-b6fe-bce9ef650837-00001.parquet
│ └── 00001-1-e11d79c5-a4b1-4178-a4a2-1a5787d6ff18-00001.parquet
└── metadata
├── 00000-fc69176c-1ad7-4a66-99f7-a53f4ec0cb4d.metadata.json
├── 00001-e83023da-46d5-42fb-9652-fd88faa4b536.metadata.json
├── 00002-32cd214b-1ce8-4642-ab70-4e1951f35fed.metadata.json
├── 00003-8b83e7d6-83e7-4589-9a20-1e02f1488a2d.metadata.json
├── aa90f6ed-aee2-49c7-a61c-bd13ed411c66-m0.avro
├── d20a2213-469f-4652-803f-f149741e9a6e-m0.avro
├── d20a2213-469f-4652-803f-f149741e9a6e-m1.avro
├── d20a2213-469f-4652-803f-f149741e9a6e-m2.avro
├── d5ba704c-1453-4f18-9077-6944baa1b3f2-m0.avro
├── snap-2875980136834144366-1-d20a2213-469f-4652-803f-f149741e9a6e.avro
├── snap-7112118703100649335-1-d5ba704c-1453-4f18-9077-6944baa1b3f2.avro
└── snap-7389540589641972921-1-aa90f6ed-aee2-49c7-a61c-bd13ed411c66.avro
4 directories, 18 files
可以看到,这里面有三个清单列表文件,分别是 snap-2875980136834144366-1-d20a2213-469f-4652-803f-f149741e9a6e.avro、snap-7112118703100649335-1-d5ba704c-1453-4f18-9077-6944baa1b3f2.avro 以及 snap-7389540589641972921-1-aa90f6ed-aee2-49c7-a61c-bd13ed411c66.avro。这三个清单列表文件其实对于的就是表的三个快照。
Apache Iceberg 时间旅行的实现
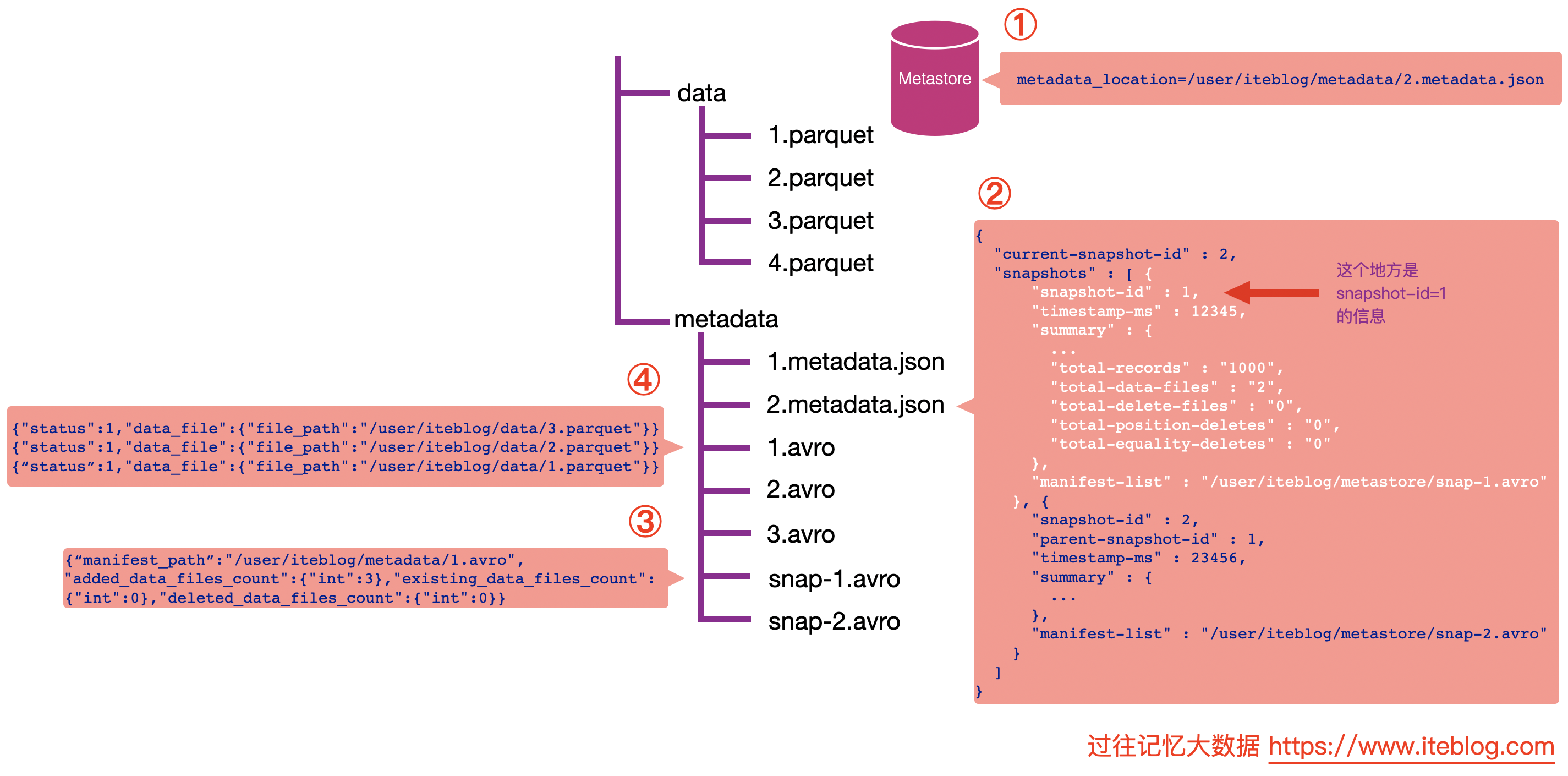
现在是时候介绍时间旅行的实现了。时间旅行其实对应的是如何读取 Iceberg 表中的数据,为了更加清晰的说明这些,我画了一张图以便大家可以更好的理解。

假设我们的表是存储在 Hive 的 MetaStore 里面的,表名为 iteblog,并且数据的组织结构如上如所示。
查询最新快照的数据
如果想查询表的最新快照数据,在 Iceberg 中是这么进行的:
- 通过数据库名和表名,从 Hive 的 MetaStore 里面拿到表的信息。从表的属性里面其实可以拿到
metadata_location属性,通过这个属性可以拿到 iteblog 表的 Iceberg 的 metadata 相关路径,这个也就是上图步骤①的 /user/iteblog/metadata/2.metadata.json。 - 解析 /user/iteblog/metadata/2.metadata.json 文件,里面可以拿到当前表的快照 id(current-snapshot-id),以及这张表的所有快照信息,也就是 JOSN 信息里面的 snapshots 数组对应的值。从上图可以看出,当前表有两个快照,id 分别为 1 和 2。快照 1 对应的清单列表文件为 /user/iteblog/metastore/snap-1.avro;快照 2 对应的清单列表文件为 /user/iteblog/metastore/snap-2.avro。
- 如果我们想读取表的最新快照数据,从 current-snapshot-id 可知,当前最新快照的 ID 等于 2,所以我们只需要解析 /user/iteblog/metastore/snap-2.avro 清单列表文件即可。从上图可以看出,snap-2.avro 这个清单列表文件里面有两个清单文件,分别为 /user/iteblog/metadata/3.avro 和 /user/iteblog/metadata/2.avro。注意,除了清单文件的路径信息,还有 added_data_files_count、existing_data_files_count 以及 deleted_data_files_count 三个属性。Iceberg 其实是根据 deleted_data_files_count 大于 0 来判断对应的清单文件里面是不是被删除的数据。由于上图 /user/iteblog/metadata/2.avro 清单文件的 deleted_data_files_count 大于 0 ,所以读数据的时候就无需读这个清单文件里面对应的数据文件。在这个场景下,读取最新快照数据只需要看下 /user/iteblog/metadata/3.avro 清单文件里面对应的数据文件即可。
- 这时候 Iceberg 会解析 /user/iteblog/metadata/3.avro 清单文件,里面其实就只有一行数据,也就是 /user/iteblog/data/4.parquet,所以我们读 iteblog 最新的数据其实只需要读 /user/iteblog/data/4.parquet 数据文件就可以了。
注意,上面 /user/iteblog/data/2.avro 文件里面对应的内容为
{"status":2,"data_file":{"file_path":"/user/iteblog/data/3.parquet"}}
{"status":2,"data_file":{"file_path":"/user/iteblog/data/2.parquet"}}
{“status":2,"data_file":{"file_path":"/user/iteblog/data/1.parquet"}}
其中的 status = 2 代表 DELETED,也就是删除,也印证了读最新快照的数据其实不用读 /user/iteblog/data/2.avro 清单文件的数据文件。而 /user/iteblog/data/3.avro 清单文件里面存储的内容为 {"status":1,"data_file":{"file_path":"/user/iteblog/data/4.parquet"}},其 status = 1,代表 ADDED,也就是新增的文件,所以得读取。
查询某个快照的数据
Apache Iceberg 支持查询历史上任何时刻的快照,在查询的时候只需要指定 snapshot-id 属性即可,比如我们想查询上面 snapshot-id 为 1 的数据,可以在 Spark 中这么写:
spark.read
.option("snapshot-id", 1L)
.format("iceberg")
.load("path/to/table")
下面是读取指定快照的图示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
从上图可以看出,和读取最新快照数据不一样的地方是上图中的第三步。由于我们指定了 snapshot-id = 1,所以 Iceberg 会读取上面第二步白色的部分,可以知道,snapshot-id = 1 对应的清单列表文件为 /user/iteblog/metastore/snap-1.avro。这时候读出清单列表里面的文件,其实就只有一行数据,对应的清单文件为 /user/iteblog/metadata/1.avro,其中 added_data_files_count 为 3。
下一步我们读取 /user/iteblog/metadata/1.avro 清单文件,可以看到里面有三个数据文件路径,这些数据文件就是 snapshot-id = 1 的数据。
根据时间戳查看某个快照的数据
Iceberg 还支持通过 as-of-timestamp 参数指定时间戳来读取某个快照的数据。如下所示:
spark.read
.option("as-of-timestamp", "12346")
.format("iceberg")
.load("path/to/table")
在上面例子中,我们指定 as-of-timestamp = 123456。那 Iceberg 是如何处理这个查询呢?其查询逻辑如下图:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
我们注意上面图中第二步里面的 JSON 数据里面有个 snapshot-log 数组,如下:
"snapshot-log" : [ {
"timestamp-ms" : 12345,
"snapshot-id" : 1
}, {
"timestamp-ms" : 23456,
"snapshot-id" : 2
}]
每个列表里面都有个 timestamp-ms 属性和 snapshot-id 属性,并且是按照 timestamp-ms 升序的。在 Iceberg 内部实现中,它会将 as-of-timestamp 指定的时间和 snapshot-log 数组里面每个元素的 timestamp-ms 进行比较,找出最后一个满足 timestamp-ms <= as-of-timestamp 对应的 snapshot-id。
由于 as-of-timestamp=12346 比 12345 时间戳大,但是比 23456 小,所以会取 snapshot-id = 1,也就是拿到 snapshot-id = 1 的快照数据。剩下的数据查询步骤和在查询中指定 snapshot-id 是一致的,我就不再介绍了。
好了,到这里我们已经基本清楚 Iceberg 是如何根据查询条件获取对应哪个快照,并且映射到数据文件,完成一次查询。后面我会详细地介绍 Apache Spark 是如何读取 Iceberg 表的,敬请关注。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Iceberg 的时间旅行是如何实现的?】(https://www.iteblog.com/archives/9901.html)






