本文介绍了如何使用 Presto 通过 Alluxio 查询 Iceberg 表。由于这项功能目前处于试验阶段,此处提供的信息可能会发生变化,请及时参考官方文档了解最新功能。关于如何使用 Presto 读取 Iceberg 上的数据请参考这里。我们知道,在 Hive 数据源上,Presto 支持两种形式的 Alluxio 缓存:通过 Alluxio local cache 以及 Alluxio Cluster,截止到本文章 w397090770 3年前 (2021-11-18) 1266℃ 0评论6喜欢
iceberg 详细设计Apache iceberg 是Netflix开源的全新的存储格式,我们已经有了parquet、orc、arvo等非常优秀的存储格式以后,Netfix为什么还要设计出iceberg呢?和parquet、orc等文件格式不同, iceberg在业界被称之为Table Foramt,parquet、orc、avro等文件等格式帮助我们高效的修改、读取单个文件;同样Table Foramt帮助我们高效的修改和读取一类文件 w397090770 4年前 (2021-04-15) 2307℃ 0评论6喜欢
在过去一年有很多 Apache 孵化项目顺利毕业成顶级项目(Top-Level Project ,简称 TLP ),在这里我将给大家盘点 2020 年晋升为 Apache TLP 的大数据相关项目。在2020年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® ShardingSphere™、Apache® Hudi™、Apache® Iceberg™ 以及 Apache® IoTDB™,这里以毕业的时间顺序依次介绍。关于过 w397090770 4年前 (2021-01-03) 1423℃ 0评论5喜欢
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。Apache Iceberg 的底层数据组织我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache I w397090770 4年前 (2020-11-29) 3704℃ 0评论4喜欢
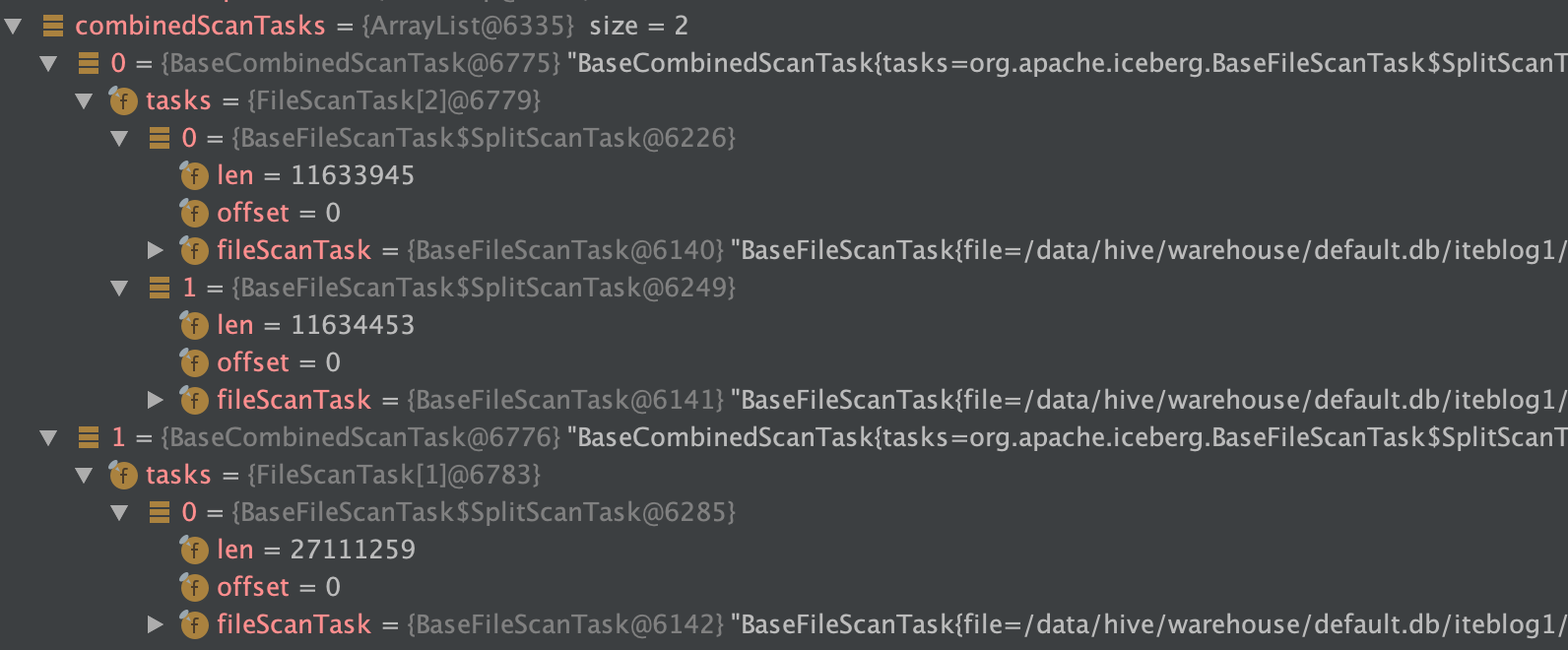
在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中我们分析了 Apache Iceberg 写数据的源码。如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局(测试代码在 这里):[code lang="bash"]/data/hive/warehouse/default.db/iteblog├── data│ └── ts_year=2020│ ├── id_bucket=0│ │ ├── 00000-0-19603f5a-d38a w397090770 4年前 (2020-11-20) 6869℃ 6评论8喜欢
本文基于 Apache Iceberg 0.9.0 最新分支,主要分析 Apache Iceberg 中使用 Spark 2.4.6 来写数据到 Iceberg 表中,也就是对应 iceberg-spark2 模块。当然,Apache Iceberg 也支持 Flink 来读写 Iceberg 表,其底层逻辑也 Spark 类似,感兴趣的同学可以去看看。使用 Spark2 将数据写到 Apache Iceberg在介绍下面文章之前,我们先来看下在 Apache Spark 2.4.6 中写数 w397090770 4年前 (2020-11-12) 5968℃ 0评论9喜欢
在 Apache Iceberg 中有很多种方式可以来创建表,其中就包括使用 Catalog 方式或者实现 org.apache.iceberg.Tables 接口。下面我们来简单介绍如何使用。.如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop使用 Hive catalog从名字就可以看出,Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它 w397090770 4年前 (2020-11-08) 2385℃ 0评论5喜欢
当前数据湖方向非常热门,市面上也出现了三款开源的数据湖产品:Delta Lake、Apache Hudi 以及 Apache Iceberg。这段时间抽了点时间看了下使用 Apache Spark 读写 Apache Iceberg 的代码。完全看代码肯定有些吃力,所以使用了代码调试功能。由于 Apache Iceberg 支持 Apache Spark 2.x 以及 3.x,并在创建了不同的模块。其相当于 Spark 的 Connect。Apache Spa w397090770 4年前 (2020-10-04) 1900℃ 0评论3喜欢
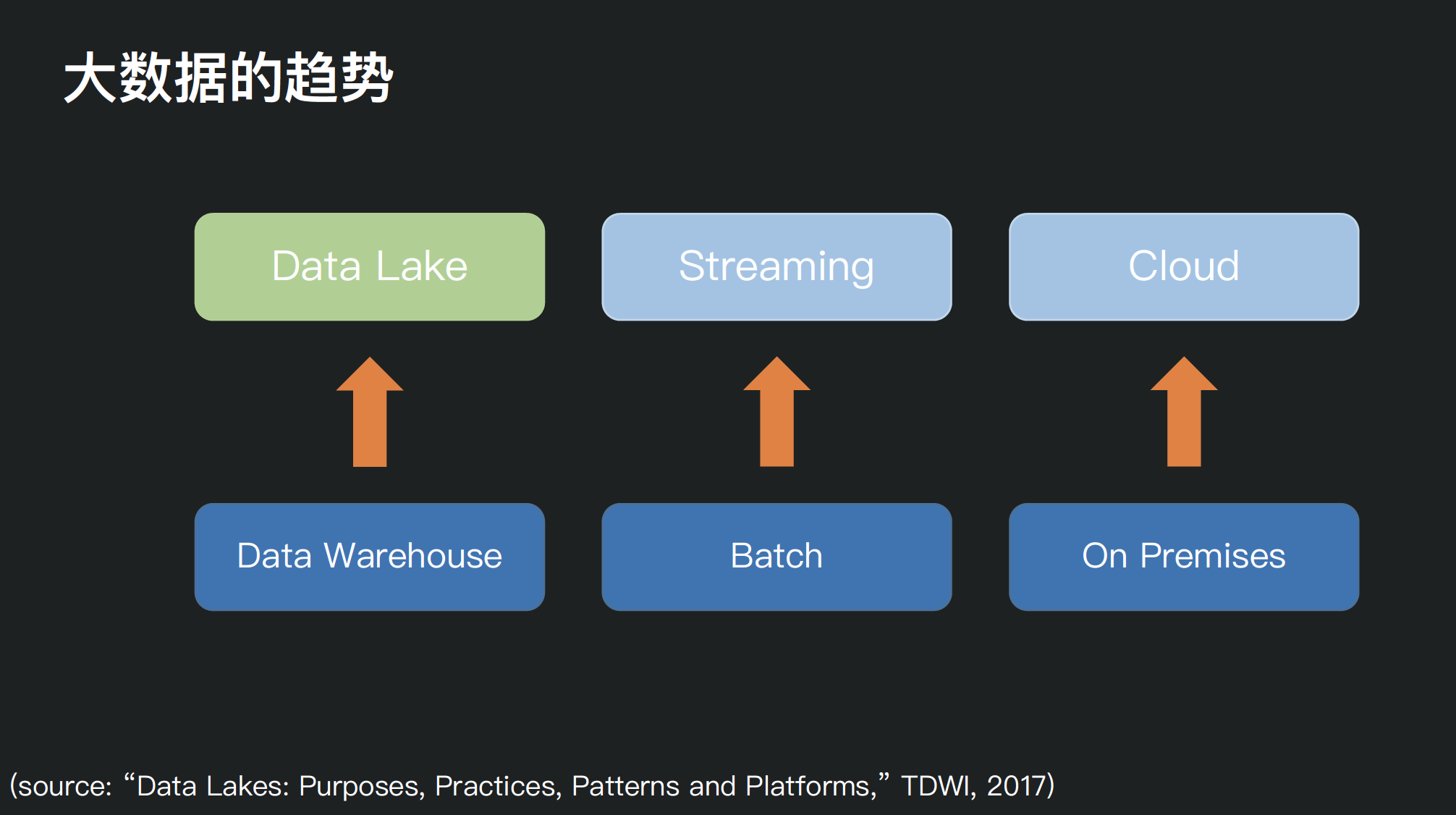
本文资料来自2020年9月5日由快手技术团队主办的快手大数据平台架构技术交流会,分享者邵赛赛,腾讯数据平台部数据湖内核技术负责人,资深大数据工程师,Apache Spark PMC member & committer, Apache Livy PMC member,曾就职于 Hortonworks,Intel 。随着大数据存储和处理需求的多样化,如何构建一个统一的数据湖存储,并在其上进行多种形式 w397090770 4年前 (2020-09-07) 4581℃ 3评论8喜欢
导言本文主要介绍如何快速的通过Spark访问 Iceberg table。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark通过DataSource和DataFrame API访问Iceberg table,或者进行Catalog相关的操作。由于Spark Data Source V2 API还在持续的演进和修改中,所以Iceberg在不同的Spark版本中的使用方式有所不同。版本对比 w397090770 5年前 (2020-06-10) 10131℃ 0评论4喜欢