

文章目录
终于到最后一篇了,我们在前面两篇文章中《一条 SQL 在 Apache Spark 之旅(上)》 和 《一条 SQL 在 Apache Spark 之旅(中)》 介绍了 Spark SQL 之旅的 SQL 解析、逻辑计划绑定、逻辑计划优化以及物理计划生成阶段,本文我们将继续接上文,介绍 Spark SQL 的全阶段代码生成以及最后的执行过程。
全阶段代码生成阶段 - WholeStageCodegen
前面我们已经介绍了从逻辑计划生成物理计划(Physical Plan),但是这个物理计划还是不能直接交给 Spark 执行的,Spark 最后仍然会用一些 Rule 对 SparkPlan 进行处理,这个过程是 prepareForExecution 过程,这些 Rule 如下:
protected def preparations: Seq[Rule[SparkPlan]] = Seq( PlanSubqueries(sparkSession), //特殊子查询物理计划处理 EnsureRequirements(sparkSession.sessionState.conf), //确保执行计划分区与排序正确性 CollapseCodegenStages(sparkSession.sessionState.conf), //代码生成 ReuseExchange(sparkSession.sessionState.conf), //节点重用 ReuseSubquery(sparkSession.sessionState.conf)) //子查询重用
上面的 Rule 中 CollapseCodegenStages 是重头戏,这就是大家熟知的全代码阶段生成,Catalyst 全阶段代码生成的入口就是这个规则。当然,如果需要 Spark 进行全阶段代码生成,需要将 spark.sql.codegen.wholeStage 设置为 true(默认)。
为什么需要代码生成
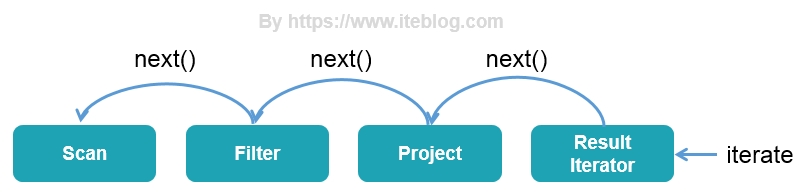
在介绍代码生成之前,我们先来了解一下 Spark SQL 为什么需要引入代码生成。在 Apache Spark 2.0 之前,Spark SQL 的底层实现是基于 Volcano Iterator Model(参见 《Volcano-An Extensible and Parallel Query Evaluation System》) 的,这个是由 Goetz Graefe 在 1993 年提出的,当今绝大多数数据库系统处理 SQL 在底层都是基于这个模型的。这个模型的执行可以概括为:首先数据库引擎会将 SQL 翻译成一系列的关系代数算子或表达式,然后依赖这些关系代数算子逐条处理输入数据并产生结果。每个算子在底层都实现同样的接口,比如都实现了 next() 方法,然后最顶层的算子 next() 调用子算子的 next(),子算子的 next() 在调用孙算子的 next(),直到最底层的 next(),具体过程如下图表示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Volcano Iterator Model 的优点是抽象起来很简单,很容易实现,而且可以通过任意组合算子来表达复杂的查询。但是缺点也很明显,存在大量的虚函数调用,会引起 CPU 的中断,最终影响了执行效率。数砖的官方博客对比过使用 Volcano Iterator Model 和手写代码的执行效率,结果发现手写的代码执行效率要高出十倍!
基于上面的发现,从 Apache Spark 2.0 开始,社区开始引入了 Whole-stage Code Generation,参见 SPARK-12795,主要就是想通过这个来模拟手写代码,从而提升 Spark SQL 的执行效率。Whole-stage Code Generation 来自于2011年 Thomas Neumann 发表的 Efficiently Compiling Efficient Query Plans for Modern Hardware 论文,这个也是 Tungsten 计划的一部分。
Tungsten 代码生成分为三部分:
- 表达式代码生成(expression codegen)
- 全阶段代码生成(Whole-stage Code Generation)
- 加速序列化和反序列化(speed up serialization/deserialization)
表达式代码生成(expression codegen)
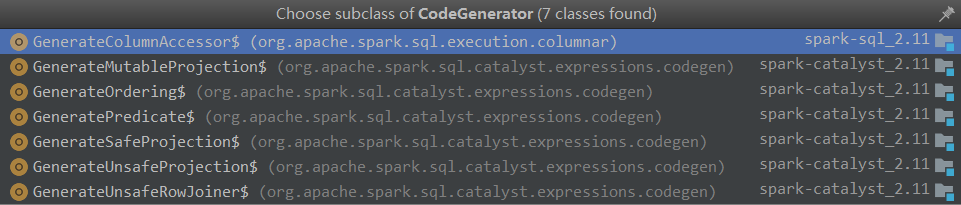
这个其实在 Spark 1.x 就有了。表达式代码生成的基类是 org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator,其下有七个子类:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
我们前文的 SQL 生成的逻辑计划中的 isnotnull(id#8) && (id#8 > 5) 就是最基本的表达式。它也是一种 Predicate,所以会调用 org.apache.spark.sql.catalyst.expressions.codegen.GeneratePredicate 来生成表达式的代码,生成的代码如下:
19/06/18 16:47:15 DEBUG GeneratePredicate: Generated predicate '(isnotnull(input[0, int, true]) && (input[0, int, true] > 5))':
/* 001 */ public SpecificPredicate generate(Object[] references) {
/* 002 */ return new SpecificPredicate(references);
/* 003 */ }
/* 004 */
/* 005 */ class SpecificPredicate extends org.apache.spark.sql.catalyst.expressions.codegen.Predicate {
/* 006 */ private final Object[] references;
/* 007 */
/* 008 */
/* 009 */ public SpecificPredicate(Object[] references) {
/* 010 */ this.references = references;
/* 011 */
/* 012 */ }
/* 013 */
/* 014 */ public void initialize(int partitionIndex) {
/* 015 */
/* 016 */ }
/* 017 */
/* 018 */ public boolean eval(InternalRow i) {
/* 019 */ boolean isNull_2 = i.isNullAt(0); //判断id是否为空
/* 020 */ int value_2 = isNull_2 ?
/* 021 */ -1 : (i.getInt(0));
/* 022 */ boolean isNull_0 = false;
/* 023 */ boolean value_0 = false;
/* 024 */
/* 025 */ if (!false && !(!isNull_2)) { //如果id为空那么整个表达式就是false
/* 026 */ } else {
/* 027 */ boolean isNull_3 = true;
/* 028 */ boolean value_3 = false;
/* 029 */ boolean isNull_4 = i.isNullAt(0); //继续判断id是否为空
/* 030 */ int value_4 = isNull_4 ? //根据id值为空获取对应的值
/* 031 */ -1 : (i.getInt(0));
/* 032 */ if (!isNull_4) { //如果id对应的值不为空,那么判断这个值是否大于5
/* 033 */
/* 034 */
/* 035 */ isNull_3 = false; // resultCode could change nullability.
/* 036 */ value_3 = value_4 > 5;
/* 037 */
/* 038 */ }
/* 039 */ if (!isNull_3 && !value_3) {
/* 040 */ } else if (!false && !isNull_3) { //id之大于5
/* 041 */ value_0 = true;
/* 042 */ } else {
/* 043 */ isNull_0 = true;
/* 044 */ }
/* 045 */ }
/* 046 */ return !isNull_0 && value_0; //这个就是表达式isnotnull(id#8) && (id#8 > 5)对每行执行的结果
/* 047 */ }
/* 048 */
/* 049 */
/* 050 */ }
上面就是对表达式 isnotnull(id#8) && (id#8 > 5) 生成的代码,里面用到了 org.apache.spark.sql.catalyst.expressions.And、org.apache.spark.sql.catalyst.expressions.IsNotNull 以及 org.apache.spark.sql.catalyst.expressions.GreaterThan 三个 Predicate 的代码生成,然后组成了上面的 SpecificPredicate 。SpecificPredicate 会对每行应用 eval 函数去判断是否满足条件,上面生成的 SpecificPredicate 类逻辑并不复杂,大家可以去细细品味。
表达式代码生成主要是想解决大量虚函数调用(Virtual Function Calls),泛化的代价等。需要注意的是,上面通过表达式生成完整的类代码只有在将 spark.sql.codegen.wholeStage 设置为 false 才会进行的,否则只会生成一部分代码,并且和其他代码组成 Whole-stage Code。
全阶段代码生成(Whole-stage Code Generation)
全阶段代码生成(Whole-stage Code Generation),用来将多个处理逻辑整合到单个代码模块中,其中也会用到上面的表达式代码生成。和前面介绍的表达式代码生成不一样,这个是对整个 SQL 过程进行代码生成,前面的表达式代码生成仅对于表达式的。全阶段代码生成都是继承自 org.apache.spark.sql.execution.BufferedRowIterator 的,生成的代码需要实现 processNext() 方法,这个方法会在 org.apache.spark.sql.execution.WholeStageCodegenExec 里面的 doExecute 方法里面被调用。而这个方法里面的 rdd 会将数据传进生成的代码里面 ,比如我们上文 SQL 这个例子的数据源是 csv 文件,底层使用 org.apache.spark.sql.execution.FileSourceScanExec 这个类读取文件,然后生成 inputRDD,这个 rdd 在 WholeStageCodegenExec 类中的 doExecute 方法里面调用生成的代码,然后执行我们各种判断得到最后的结果。WholeStageCodegenExec 类中的 doExecute 方法部分代码如下:
// rdds 可以从 FileSourceScanExec 的 inputRDDs 方法获取
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
......
rdds.head.mapPartitionsWithIndex { (index, iter) =>
// 编译生成好的代码
val (clazz, _) = CodeGenerator.compile(cleanedSource)
// 前面说了所有生成的代码都是继承自 BufferedRowIterator
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
// 调用生成代码的 init 方法,主要传入 iter 迭代器,这里面就是我们要的数据
buffer.init(index, Array(iter))
new Iterator[InternalRow] {
override def hasNext: Boolean = {
// 这个会调用生成的代码中 processNext() 方法,里面就会根据表达式对每行数据进行判断
val v = buffer.hasNext
if (!v) durationMs += buffer.durationMs()
v
}
override def next: InternalRow = buffer.next()
}
}
......
那么我们生成的代码长什么样呢?我们还是对前面文章的 SQL 进行分析,这个 SQL 生成的物理计划如下:
== Physical Plan ==
*(3) HashAggregate(keys=[], functions=[sum(cast(v#16 as bigint))], output=[sum(v)#22L])
+- Exchange SinglePartition
+- *(2) HashAggregate(keys=[], functions=[partial_sum(cast(v#16 as bigint))], output=[sum#24L])
+- *(2) Project [(3 + value#1) AS v#16]
+- *(2) BroadcastHashJoin [id#0], [id#8], Inner, BuildRight
:- *(2) Project [id#0, value#1]
: +- *(2) Filter (((((isnotnull(cid#2) && isnotnull(did#3)) && (cid#2 = 1)) && (did#3 = 2)) && (id#0 > 5)) && isnotnull(id#0))
: +- *(2) FileScan csv [id#0,value#1,cid#2,did#3] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/iteblog/t1.csv], PartitionFilters: [], PushedFilters: [IsNotNull(cid), IsNotNull(did), EqualTo(cid,1), EqualTo(did,2), GreaterThan(id,5), IsNotNull(id)], ReadSchema: struct<id:int,value:int,cid:int,did:int>
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)))
+- *(1) Project [id#8]
+- *(1) Filter (isnotnull(id#8) && (id#8 > 5))
+- *(1) FileScan csv [id#8] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/iteblog/t2.csv], PartitionFilters: [], PushedFilters: [IsNotNull(id), GreaterThan(id,5)], ReadSchema: struct<id:int>
从上面的物理计划可以看出,整个 SQL 的执行分为三个阶段。为了简便起见,我们仅仅分析第一个阶段的代码生成,也就是下面物理计划:
+- *(1) Project [id#8]
+- *(1) Filter (isnotnull(id#8) && (id#8 > 5))
+- *(1) FileScan csv [id#8] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/iteblog/t2.csv], PartitionFilters: [], PushedFilters: [IsNotNull(id), GreaterThan(id,5)], ReadSchema: struct<id:int>
通过全阶段代码生成,上面过程得到的代码如下:
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] filter_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[2];
/* 010 */ private scala.collection.Iterator[] scan_mutableStateArray_0 = new scala.collection.Iterator[1];
/* 011 */
/* 012 */ public GeneratedIteratorForCodegenStage1(Object[] references) {
/* 013 */ this.references = references;
/* 014 */ }
/* 015 */
/* 016 */ public void init(int index, scala.collection.Iterator[] inputs) { //在WholeStageCodegenExec类中的doExecute被调用
/* 017 */ partitionIndex = index;
/* 018 */ this.inputs = inputs;
/* 019 */ scan_mutableStateArray_0[0] = inputs[0];
/* 020 */ filter_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 021 */ filter_mutableStateArray_0[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 022 */
/* 023 */ }
/* 024 */
/* 025 */ protected void processNext() throws java.io.IOException { //处理每行数据,这个就是isnotnull(id#8) && (id#8 > 5)表达式的判断
/* 026 */ while (scan_mutableStateArray_0[0].hasNext()) {
/* 027 */ InternalRow scan_row_0 = (InternalRow) scan_mutableStateArray_0[0].next();
/* 028 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(1);
/* 029 */ do {
/* 030 */ boolean scan_isNull_0 = scan_row_0.isNullAt(0); //判断id是否为空
/* 031 */ int scan_value_0 = scan_isNull_0 ? //如果为空则scan_value_0等于-1,否则就是id的值
/* 032 */ -1 : (scan_row_0.getInt(0));
/* 033 */
/* 034 */ if (!(!scan_isNull_0)) continue; //如果id为空这行数据就不要了
/* 035 */
/* 036 */ boolean filter_value_2 = false;
/* 037 */ filter_value_2 = scan_value_0 > 5; //id是否大于5
/* 038 */ if (!filter_value_2) continue; //如果id不大于5,则这行数据不要了
/* 039 */
/* 040 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[1] /* numOutputRows */).add(1);
/* 041 */
/* 042 */ filter_mutableStateArray_0[1].reset();
/* 043 */
/* 044 */ if (false) {
/* 045 */ filter_mutableStateArray_0[1].setNullAt(0);
/* 046 */ } else {
/* 047 */ filter_mutableStateArray_0[1].write(0, scan_value_0); //这个就是符合isnotnull(id#8) && (id#8 > 5)表达式的id
/* 048 */ }
/* 049 */ append((filter_mutableStateArray_0[1].getRow())); //得到符号条件的行
/* 050 */
/* 051 */ } while(false);
/* 052 */ if (shouldStop()) return;
/* 053 */ }
/* 054 */ }
/* 055 */
/* 056 */ }
上面代码逻辑很好理解,大部分代码我都注释了,其实就是对每行的 id 进行 isnotnull(id#8) && (id#8 > 5) 表达式判断,然后拿到符合条件的行。剩余的其他阶段的代码生成和这个类似,生成的代码有点多,我就不贴出来了,感兴趣的同学可以自己去看下。相比 Volcano Iterator Model,全阶段代码生成的执行过程如下:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
通过引入全阶段代码生成,大大减少了虚函数的调用,减少了 CPU 的调用,使得 SQL 的执行速度有很大提升。
代码编译
生成代码之后需要解决的另一个问题是如何将生成的代码进行编译然后加载到同一个 JVM 中去。在早期 Spark 版本是使用 Scala 的 Reflection 和 Quasiquotes 机制来实现代码生成的。Quasiquotes 是一个简洁的符号,可以让我们轻松操作 Scala 语法树,具体参见 这里。虽然 Quasiquotes 可以很好的为我们解决代码生成等相关的问题,但是带来的新问题是编译代码时间比较长(大约 50ms - 500ms)!所以社区不得不默认关闭表达式代码生成。
为了解决这个问题,Spark 引入了 Janino 项目,参见 SPARK-7956。Janino 是一个超级小但又超级快的 Java™ 编译器. 它不仅能像 javac 工具那样将一组源文件编译成字节码文件,还可以对一些 Java 表达式,代码块,类中的文本(class body)或者内存中源文件进行编译,并把编译后的字节码直接加载到同一个 JVM 中运行。Janino 不是一个开发工具, 而是作为运行时的嵌入式编译器,比如作为表达式求值的翻译器或类似于 JSP 的服务端页面引擎,关于 Janino 的更多知识请参见这里。通过引入了 Janino 来编译生成的代码,结果显示 SQL 表达式的编译时间减少到 5ms。在 Spark 中使用了 ClassBodyEvaluator 来编译生成之后的代码,参见 org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator。
需要主要的是,代码生成是在 Driver 端进行的,而代码编译是在 Executor 端进行的。
SQL 执行
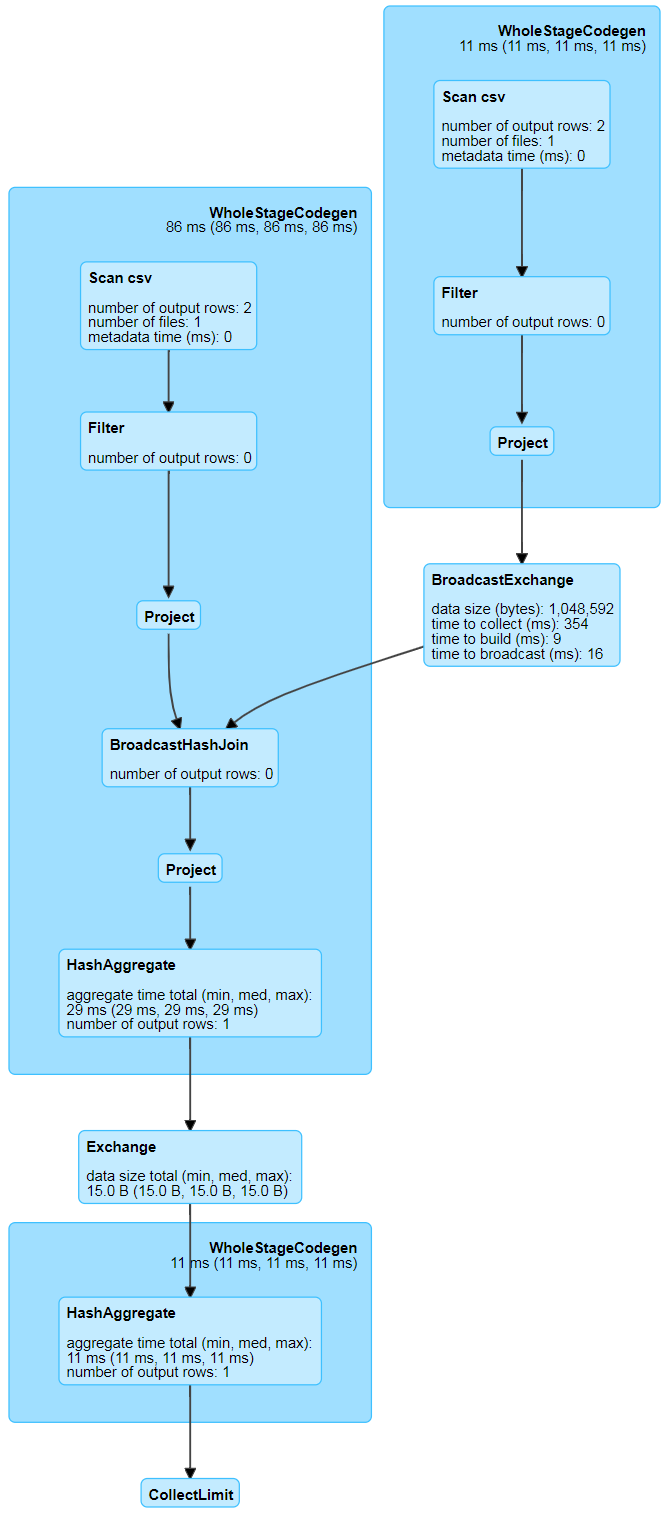
终于到了 SQL 真正执行的地方了。这个时候 Spark 会执行上阶段生成的代码,然后得到最终的结果,DAG 执行图如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【一条 SQL 在 Apache Spark 之旅(下)】(https://www.iteblog.com/archives/2563.html)






