
Apache HBase是基于Hadoop构建的一个分布式的、可伸缩的海量数据存储系统。随着时间的推移,HBase目前不管是在国内还是国外都受到了非常大的欢迎,以下分别是近几年 Google 和百度关于 HBase 的搜索趋势:
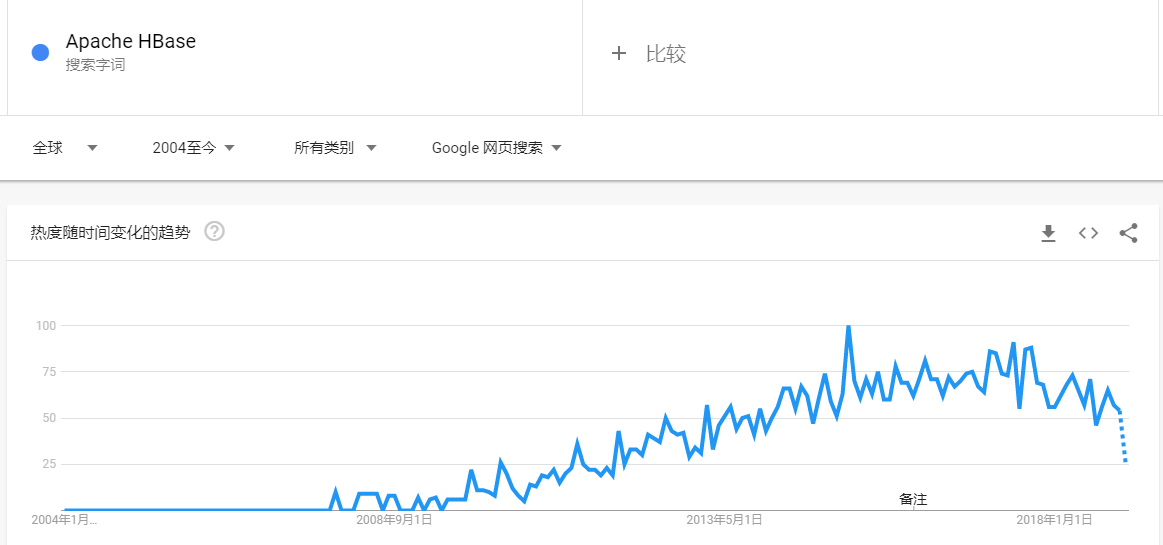 Google
Google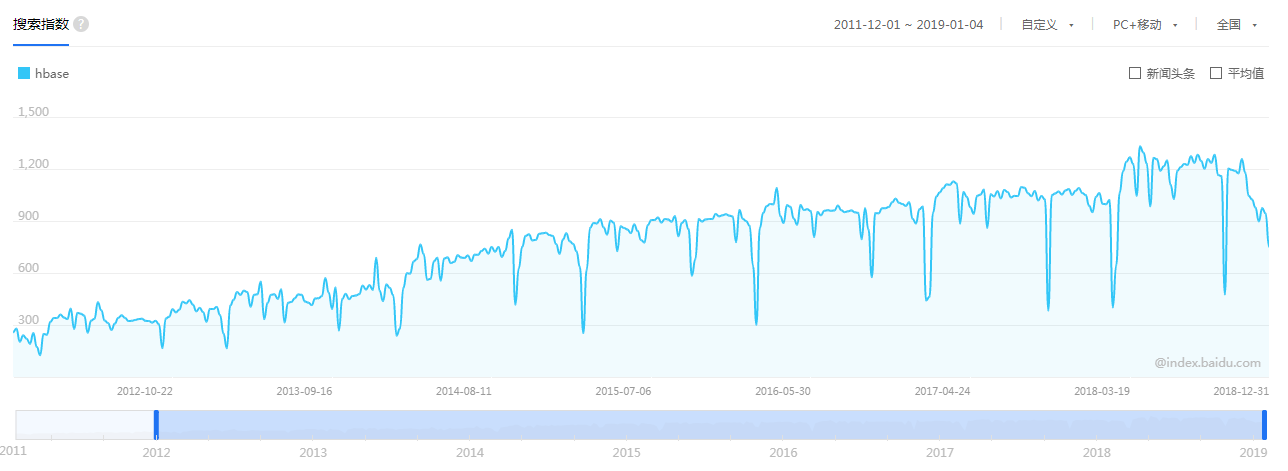
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
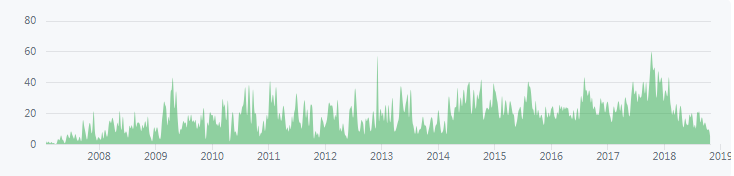
大家可以看到,整体趋势是越来越多的被搜索。我们再看下HBase代码近几年的提交情况:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
可以看出,HBase社区是非常活跃的。同时,在国内,基本上我们知道的大公司都在用HBase作为其公司核心数据库,如下(不完全显示):

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
为了大家能够更好的了解和使用Apache HBase,中国 HBase 技术社区小伙伴们利用元旦假期时间特意做了个 HBase 技术专刊,如下:

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
目录如下:

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
我们也邀请到 HBase PMC & HBase Committer 杨文龙伴我们写了个推荐:
HBase是一个高性能,并且支持无限水平扩展的在线数据库,其存储计算分离的特性非常好地适应了目前的趋势,并且在国内大公司内都被广泛地应用,具有非常好的生态,是构建大数据系统的不二选择。
杨文龙 HBase PMC&HBase Committer
长按识别以下二维码,关注“过往记忆大数据”官方微信公众号,回复“HBase_book”,即可免费获取本书。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【为了让你更全面的了解Apache HBase,我们做了这本专刊】(https://www.iteblog.com/archives/2496.html)







就这就结束了?
到上面提到的公众号可以下载这本书的
好吧,之前没加载出来下面的内容,难道是bug?
图片加载是异步的,可能是网络问题。