我们在 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章中已经简单介绍了 OpenTSDB 的 RowKey 设计的思路,并简单介绍了列簇以及列名的组成。本文将比较详细的介绍 OpenTSDB 在 HBase 的数据存储模型。
OpenTSDB RowKey 设计
关于 OpenTSDB 的 RowKey 为什么这么设计可以参见 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》文章了。这里主要介绍 RowKey 的数据模型。
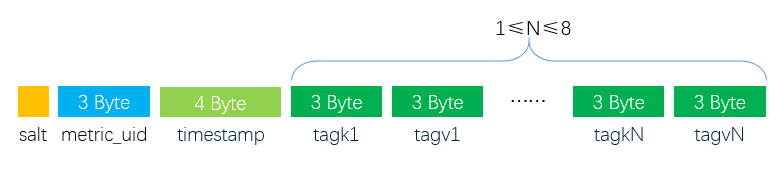
OpenTSDB 的 RowKey 由可选的 salt 位,指标名称编码,基准时间戳以及一系列的标签名编码(tagk)和标签值编码(tagv)组成,格式为 [salt]<metric_uid><timestamp><tagk1><tagv1>[...<tagkn><tagvn>],其中标签对默认最多支持8组,可以通过 tsd.storage.max_tags 参数进行修改。默认情况下,指标名称编码、标签名编码和标签值编码都是由三个字节组成,我们可以通过分别修改 tsd.storage.uid.width.metric、tsd.storage.uid.width.tagk 以及 tsd.storage.uid.width.tagv 参数来设置对应编码占用的字节数。
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
其中
- 如果我们打开了 salting 功能(通过
tsd.storage.salt.width参数),那么 RowKey 的最前面就是 hashed salt ID,具体占用多少字节是由tsd.storage.salt.width参数决定的,比如tsd.storage.salt.width设置为1,则 hashed salt ID 占用1个字节。打开 salting 功能主要是能够更好地将数据分散到集群。 - metric_uid 默认占用三个字节,主要是指标名称的编码。
- timestamp 占用四个字节,主要存储的是精确到秒或毫秒的 Unix 时间(UNIX Epoch time)。我们在前文已经讲了 OpenTSDB 中同一个小时的数据是存放在一行的,所以这里的时间戳被标准化到对应时间的小时时间戳。比如 2018-12-04 23:00:00,多出来的秒或者毫秒是放在列名称里面的。
- tagk 和 tagv 代表的是标签名称和其对应的值,默认各占用三个字节。当然这里存的也是对应的编码。
因为 HBase 的 RowKey 是全局有序的,而且 OpenTSDB 这样的 RowKey 设计(假设没有开启 salting 功能),导致相同指标对应的值一般存放在相邻位置。下面是 unsalted RowKey 的十六进制表示示例。
00000150E22700000001000001 00000150E22700000001000001000002000004 00000150E22700000001000002 00000150E22700000001000003 00000150E23510000001000001 00000150E23510000001000001000002000004 00000150E23510000001000002 00000150E23510000001000003 00000150E24320000001000001 00000150E24320000001000001000002000004 00000150E24320000001000002 00000150E24320000001000003
上面示例代表同一个指标在三个小时的 RowKey 组成。其中
00000150E22700000001000001 '----''------''----''----' metric time tagk tagv 00000150E22700000001000001000002000004 '----''------''----''----''----''----' metric time tagk tagv tagk tagv
OpenTSDB 列名设计
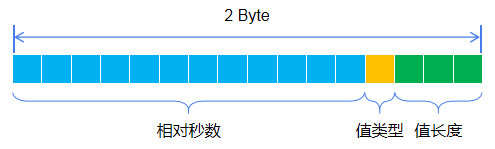
列名是由2到4字节的内容组成。其中包含了相对于 RowKey 中整点时间多出来的秒或毫秒数、标记位(用于标记当前监控值是整型或者是浮点型)以及监控数值占用的字节数。
时间戳到秒级别
如果 Rowkey 里面的时间戳只到秒级别的,比如1544022000,那么列名称占用2个字节。如下所示:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
其中后面三位代表当前列值占用的字节数。
- 如果后三位为100,代表当前列值占了8字节;
- 如果后三位为011,代表当前列值占了4字节;
- 如果后三位为010,代表当前列值占了2字节;
- 如果后三位为000,代表当前列值占了1字节;
- 其他情况就是异常的。
倒数第四为代表当前列值的类型,
- 如果为0,则代表整型数据;
- 如果为1,则代表四字节浮点型数据。
前面12位才表示相对于 Rowkey 的秒数。
时间戳到毫秒级别
如果 Rowkey 里面的时间戳只到毫秒级别的,比如1544022000000,那么列名称占用4个字节。如下所示:

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
其中
- 最前四位固定为全1;
- 最后面四位的含义和前面一样;
- 倒数第5-6位为预留位;
- 剩下的22位才是真正的相对于 Rowkey 里面毫秒数。
OpenTSDB 值设计
OpenTSDB 里面监控的数值只支持整型或浮点型,目前值占用的字节数为1、2、4以及8字节,其他的就为异常(这里没有考虑压缩)。
更多关于 OpenTSDB 的数据模型请参见 这里
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【OpenTSDB 之 HBase的数据模型】(https://www.iteblog.com/archives/2473.html)