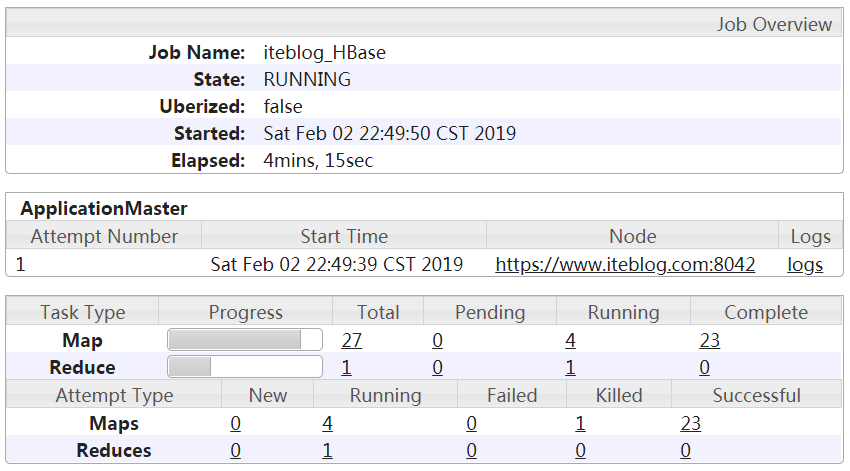
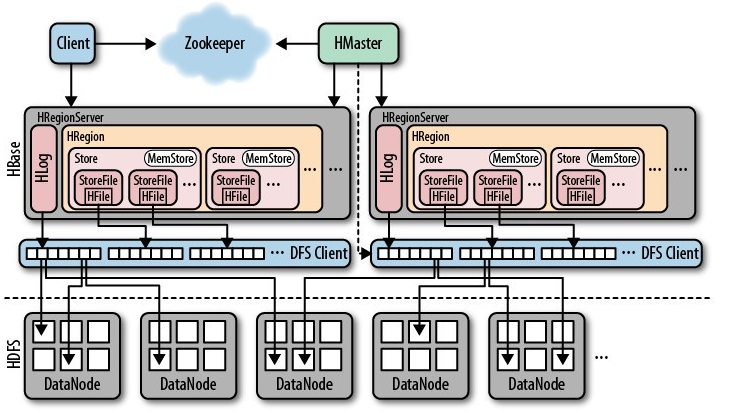
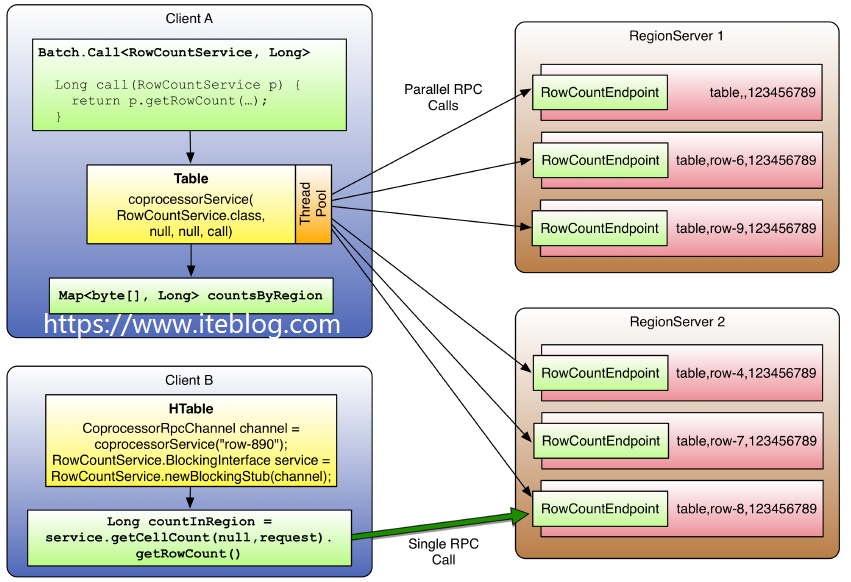
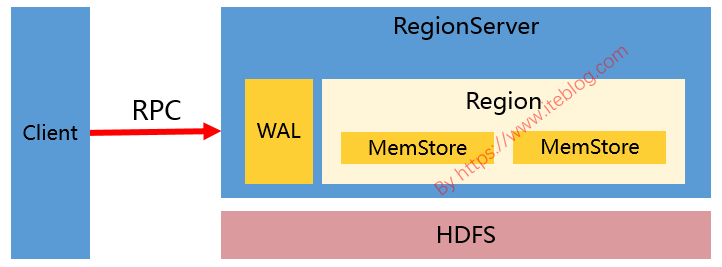
前两篇文章,《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 和 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 分别介绍了两种方法读取加盐之后的 HBase 表。本文将介绍如何在 MapReduce 读取加盐之后的表。在 MapReduce 中也可以使用 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 文章里面的 SaltRangeTableInputForm w397090770 6年前 (2019-02-27) 2954℃ 0评论7喜欢
在 《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能。我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat、OutputFormat 等类。这个工程的描述如下:This module contains implementations of InputFormat, OutputFormat, Mapper w397090770 6年前 (2019-02-26) 3904℃ 0评论16喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀,那么我们怎么将这些数据读出来呢?我将分三篇文章来介绍如何 w397090770 6年前 (2019-02-24) 4728℃ 0评论11喜欢
本文首先对 HBase 做简单的介绍,包括其整体架构、依赖组件、核心服务类的相关解析。再重点介绍 HBase 读取数据的流程分析,并根据此流程介绍如何在客户端以及服务端优化性能,同时结合有赞线上 HBase 集群的实际应用情况,将理论和实践结合,希望能给读者带来启发。如文章有纰漏请在下面留言,我们共同探讨共同学习。HBas w397090770 6年前 (2019-02-20) 5260℃ 0评论11喜欢
HBase 和 MapReduce 有很高的集成,我们可以使用 MR 对存储在 HBase 中的数据进行分布式计算。但是在很多情况下,例如简单的加法计算或者聚合操作(求和、计数等),如果能够将这些计算推送到 RegionServer,这将大大减少服务器和客户的的数据通信开销,从而提高 HBase 的计算性能,这就是本文要介绍的协处理器(Coprocessors)。HBase w397090770 6年前 (2019-02-17) 6327℃ 2评论13喜欢
接触过 HBase 的同学应该对 HBase 写数据的过程比较熟悉(不熟悉也没关系)。HBase 写数据(比如 put、delete)的时候,都是写 WAL(假设 WAL 没有被关闭) ,然后将数据写到一个称为 MemStore 的内存结构里面的,如下图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是,MemStore 毕竟是内存里 w397090770 6年前 (2019-01-13) 7506℃ 4评论32喜欢
在介绍 HBase 是不是列式存储数据库之前,我们先来了解一下什么是行式数据库和列式数据库。行式数据库和列式数据库在维基百科里面,对行式数据库和列式数据库的定义为:列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理(OLAP)和即时查询。相对应的是行式数据库,数据以行相关的存储体 w397090770 6年前 (2019-01-08) 6479℃ 0评论31喜欢
Apache HBase 是构建在 HDFS 之上的数据库,使用 HBase 我们可以随机读写存储在 HDFS 上的数据,但是我们都知道,HDFS 上的文件仅仅只支持追加(Append),其默认是不支持修改已经写好的文件。所以很多人就会问,HBase 是如何实现低延迟的读写能力呢?文本将试图介绍 HBase 写数据的过程。其实 HBase 写数据包括 put 和 delete 操作,在 HBase w397090770 6年前 (2019-01-02) 2583℃ 0评论12喜欢
在《HDFS 快照编程指南》文章中,我简单介绍了 HDFS 的快照功能。本文将介绍 HBase 快照功能,因为 HBase 的底层存储是基于 HDFS 的,所以 HBase 的快照功能也是依赖 HDFS 快照的知识。HBase 快照功能是从 HBase 0.95.0 开始引入的,详见 HBASE-50。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHBase 快 w397090770 6年前 (2019-01-01) 2695℃ 0评论9喜欢
我们知道,一张 HBase 表包含一个或多个列族。HBase 的官方文档中关于 HBase 表的列族的个数有两处描述:A typical schema has between 1 and 3 column families per table. HBase tables should not be designed to mimic RDBMS tables. 以及 HBase currently does not do well with anything above two or three column families so keep the number of column families in your schema low. 上面两句话其实都是 w397090770 6年前 (2019-01-01) 4493℃ 1评论13喜欢