

在Sortable公司,很多数据处理的工作都是使用Spark完成的。在使用Spark的过程中他们发现了一个能够提高Spark job性能的一个技巧,也就是修改数据的分区数,本文将举个例子并详细地介绍如何做到的。
查找质数
比如我们需要从2到2000000之间寻找所有的质数。我们很自然地会想到先找到所有的非质数,剩下的所有数字就是我们要找的质数。
我们首先遍历2到2000000之间的每个数,然后找到这些数的所有小于或等于2000000的倍数,在计算的结果中可能会有许多重复的数据(比如6同时是2和3的倍数)但是这并没有啥影响。
我们在Spark shell中计算:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.1
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_45)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
SQL context available as sqlContext.
scala> val n = 2000000
n: Int = 2000000
scala> val composite = sc.parallelize(2 to n, 8).map(x => (x, (2 to (n / x)))).flatMap(kv => kv._2.map(_ * kv._1))
composite: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at flatMap at <console>:29
scala>
scala> val prime = sc.parallelize(2 to n, 8).subtract(composite)
prime: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[7] at subtract at <console>:31
scala> prime.collect()
res0: Array[Int] = Array(563249, 17, 281609, 840761, 1126513, 1958993, 840713, 1959017, 41, 281641, 1681513, 1126441, 73, 1126457, 89, 840817, 97, 1408009, 113, 137, 1408241, 563377, 1126649, 281737, 281777, 840841, 1408217, 1681649, 281761, 1408201, 1959161, 1408177, 840929, 563449, 1126561, 193, 1126577, 1126537, 1959073, 563417, 233, 281849, 1126553, 563401, 281833, 241, 563489, 281, 281857, 257, 1959241, 313, 841081, 337, 1408289, 563561, 281921, 353, 1681721, 409, 281993, 401, 1126897, 282001, 1126889, 1959361, 1681873, 563593, 433, 841097, 1959401, 1408417, 1959313, 1681817, 457, 841193, 449, 563657, 282089, 282097, 1408409, 1408601, 1959521, 1682017, 841241, 1408577, 569, 1408633, 521, 841273, 1127033, 841289,617, 1408529, 1959457, 563777, 841297, 1959473, 577, 593, 563809, 601,...
答案看起来是可靠的,但是我们来看看这个程序的性能。如果我们到Spark UI里面看的话可以发现Spark在整个计算过程中使用了3个stages,下图就是UI中这个计算过程的DAG(Directed Acyclic Graph)可视化图,其中展示了DAG图中不同的RDD计算。

在Spark中,只要job需要在分区之间进行数据交互,那么一个新的stage将会产生(如果使用Spark术语的话,分区之间的数据交互其实就是shuffle)。Spark stage中每个分区将会起一个task进行计算,而这些task负责将这个RDD分区的数据转化(transform)成另外一个RDD分区的数据。我们简单地看下Stage 0的task运行情况:
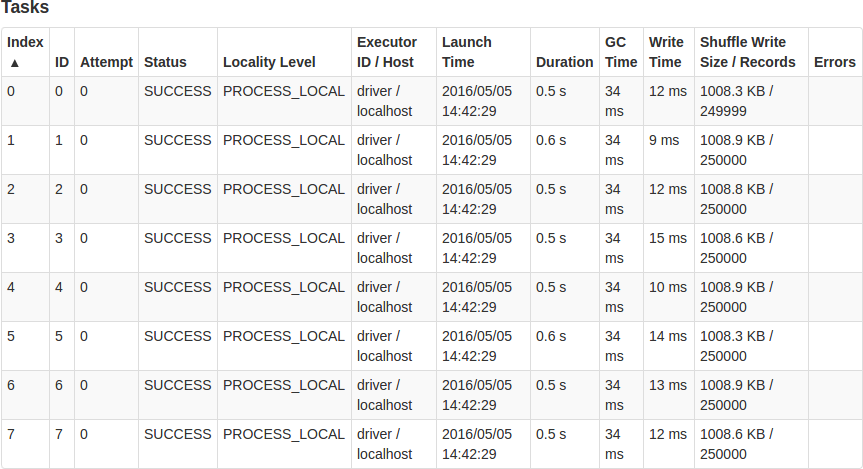
上图中我们对Duration和Shuffle Write Size / Records两列非常感兴趣。sc.parallelize(2 to n, 8)已经生成了1999999 records,而这写记录均匀地分布到8个分区里面;每个task的计算几乎花费了相同的时间,所以这个stage是没问题的。
Stage 1是比较重要的stage,因为它运行了map和flatMap transformation,我们来看看它的运行情况:
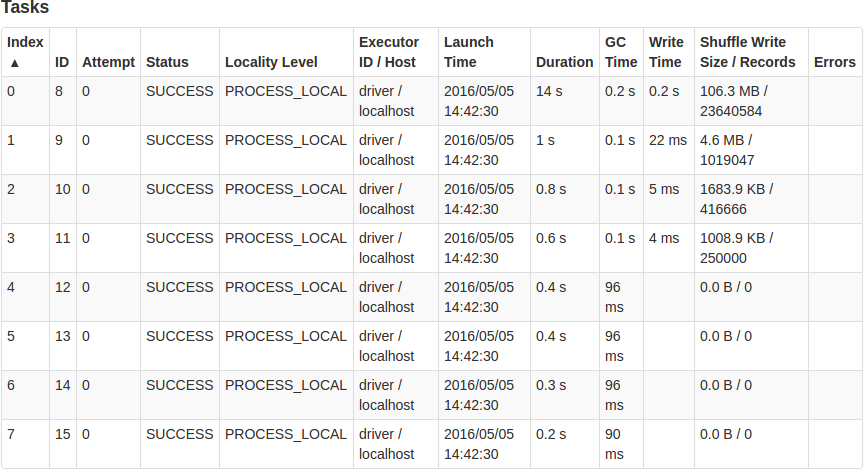
从上图可以看出,这个stage运行的并不好,因为工作负载并没有均衡到所有的task中!93%的数据集中在一个task中,而这个task的计算花费了14s;另外一个比较慢的task花费了1s。然而我们提供了8个core用于计算,而其中的7个core在这13s内都在等待这个stage的完成。这对资源的利用非常不高效。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
为什么会出现这种情况?
当我们运行sc.parallelize(2 to n, 8)语句的时候,Spark使用分区机制将数据很好地分成8个组。它最有可能使用的是range partitioner,也就是说2-250000被分到第一个分区; 250001-500000分到第二个分区等等。然而我们的map函数将这些数转成(key,value)pairs,而value里面的数据大小变化很大(key比较小的时候,value的值就比较多,从而也比较大)。每个value都是一个list,里面存放着我们需要乘上key并小于2000000的倍数值,有一半以上的键值对(所有key大于1000000)的value是空的;而key等于2对应的value是最多的,包含了所有从2到1000000的数据!这就是为什么第一个分区拥有几乎所有的数据,它的计算花费了最多的时间;而最后四个分区几乎没有数据!
如何解决
我们可以将数据重新分区。通过对RDD调用.repartition(numPartitions)函数将会使Spark触发shuffle并且将数据分布到我们指定的分区数中,所以让我们尝试将这个加入到我们的代码中。
我们除了在.map和.flatMap函数之间加上.repartition(8)之外,其他的代码并不改变。我们的RDD现在同样拥有8个分区,但是现在的数据将会在这些分区重新分布,修改后的代码如下:
/** * User: 过往记忆 * Date: 2016年6月24日 * Time: 下午21:16 * bolg: https://www.iteblog.com * 本文地址:https://www.iteblog.com/archives/1695.html * 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货 * 过往记忆博客微信公共帐号:iteblog_hadoop */ val composite = sc.parallelize(2 to n, 8).map(x => (x, (2 to (n / x)))).repartition(8).flatMap(kv => kv._2.map(_ * kv._1))
新的DAG可视化图看起来比之前更加复杂,因为repartition操作会有shuffle操作,所有增加了一个stage。

Stage 0和之前一样,新的 Stage 1看起来和 Stage 0也很类似,每个task大约都处理250000条记录,并且花费1s的时间。 Stage 2是比较重要的stage,下面是其截图:

从上图可以看出,现在的Stage 2比之前旧的Stage 1性能要好很多,这次Stage我们处理的数据和之前旧的Stage 1同样多,但是这次每个task花费的时候大概为5s,而且每个core得到了高效地使用。
两个版本的代码最后一个Stage大概都运行了6s,所以第一个版本的代码运行了大约0.5 + 14 + 6 = ~21s;而对数据进行重新分布之后,这次运行的时间大约为0.5 + 1 + 5 + 6 = ~13s。虽然说修改后的代码需要做一些额外的计算(重新分布数据),但是这个修改却减少了总的运行时间,因为它使得我们可以更加高效地使用我们的资源。
当然,如果你的目标是寻找质数,有比这里介绍的更加高效的算法。但是本文仅仅是用来介绍考虑Spark数据的分布是多么地重要。增加.repartition函数将会增加Spark总体的工作,但好处可以显著大于成本
本文翻译自:Improving Spark Performance With Partitioning
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【通过分区(Partitioning)提高Spark的运行性能】(https://www.iteblog.com/archives/1695.html)







想问一下楼主,我还是不太明白,为什么repartition(8)后就可以使得数据分布的均匀?repartition默认分区器是HashPartitioner,是按hash分区的,而文中的key-value对中value数量随着key增大是逐渐减少的,简单的Hash分区,就能使得各种value均匀分布么?
翻译得很完美