

文章目录
本文聚焦Apache Spark入门,了解其在大数据领域的地位,覆盖Apache Spark的安装及应用程序的建立,并解释一些常见的行为和操作。
一、 为什么要选择Apache Spark
当前,我们正处在一个“大数据"的时代,每时每刻,都有各种类型的数据被生产。而在此紫外,数据增幅的速度也在显著增加。从广义上看,这些数据包含交易数据、社交媒体内容(比如文本、图像和视频)以及传感器数据。那么,为什么要在这些内容上投入如此多精力,其原因无非就是从海量数据中提取洞见可以对生活和生产实践进行很好的指导。
在几年前,只有少部分公司拥有足够的技术力量和资金去储存和挖掘大量数据,并对其挖掘从而获得洞见。然而,被雅虎2009年开源的Apache Hadoop对这一状况产生了颠覆性的冲击——通过使用商用服务器组成的集群大幅度地降低了海量数据处理的门槛。因此,许多行业(比如Health care、Infrastructure、Finance、Insurance、Telematics、Consumer、Retail、Marketing、E-commerce、Media、 Manufacturing和Entertainment)开始了Hadoop的征程,走上了海量数据提取价值的道路。着眼Hadoop,其主要提供了两个方面的功能:
1、通过水平扩展商用主机,HDFS提供了一个廉价的方式对海量数据进行容错存储。
2、MapReduce计算范例,提供了一个简单的编程模型来挖掘数据并获得洞见。
下图展示了MapReduce的数据处理流程,其中一个Map-Reduce step的输出将作为下一个典型Hadoop job的输入结果:
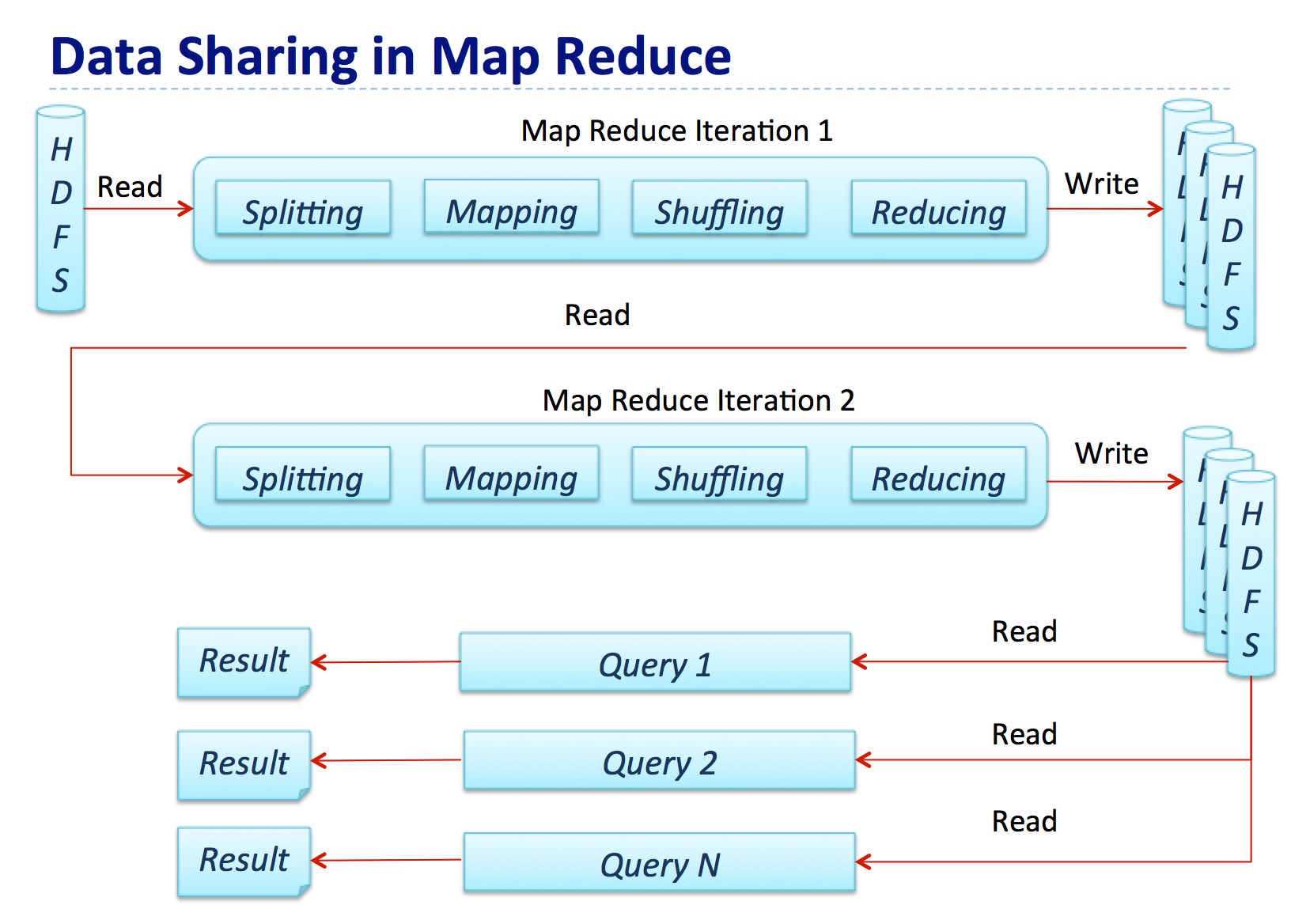
在整个过程中,中间结果会借助磁盘传递,因此对比计算,大量的Map-Reduced作业都受限于IO。然而对于ETL、数据整合和清理这样的用例来说,IO约束并不会产生很大的影响,因为这些场景对数据处理时间往往不会有较高的需求。然而,在现实世界中,同样存在许多对延时要求较为苛刻的用例,比如:
1、对流数据进行处理来做近实时分析。举个例子,通过分析点击流数据做视频推荐,从而提高用户的参与度。在这个用例中,开发者必须在精度和延时之间做平衡。
2、在大型数据集上进行交互式分析,数据科学家可以在数据集上做ad-hoc查询。
下图展示了Hadoop是如何发展成一系列技术的生态系统,这些技术分别解决特定的使用场景:
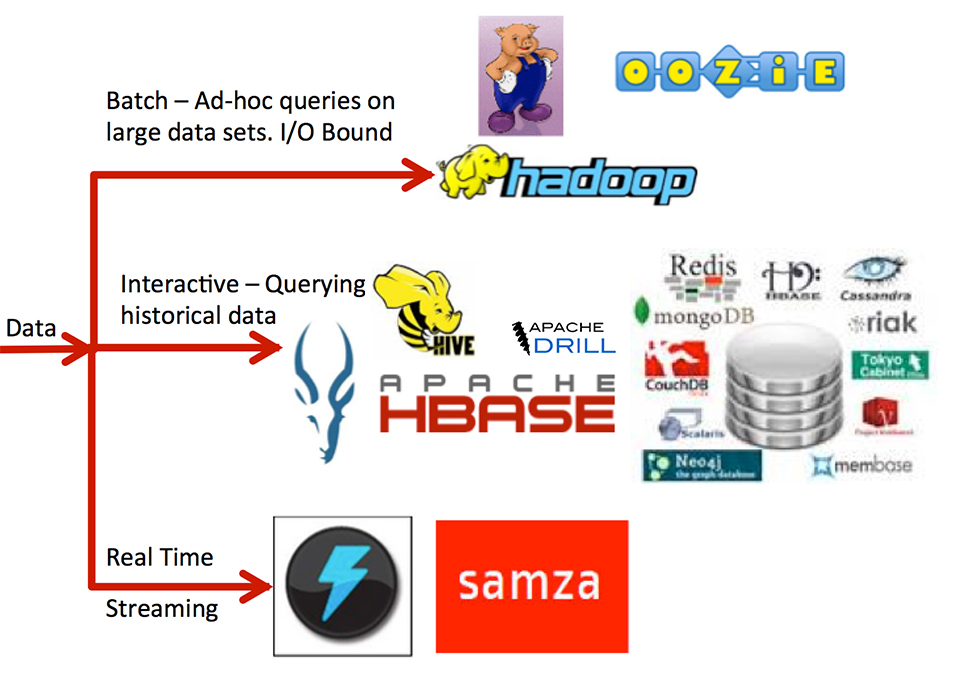
毫无疑问,历经数年发展,Hadoop生态圈中的丰富工具已深受用户喜爱,然而这里仍然存在众多问题给使用带来了挑战:
1.每个用例都需要多个不同的技术堆栈来支撑,在不同使用场景下,大量的解决方案往往捉襟见肘。
2.在生产环境中机构往往需要精通数门技术。
3.许多技术存在版本兼容性问题。
4.无法在并行job中更快地共享数据。
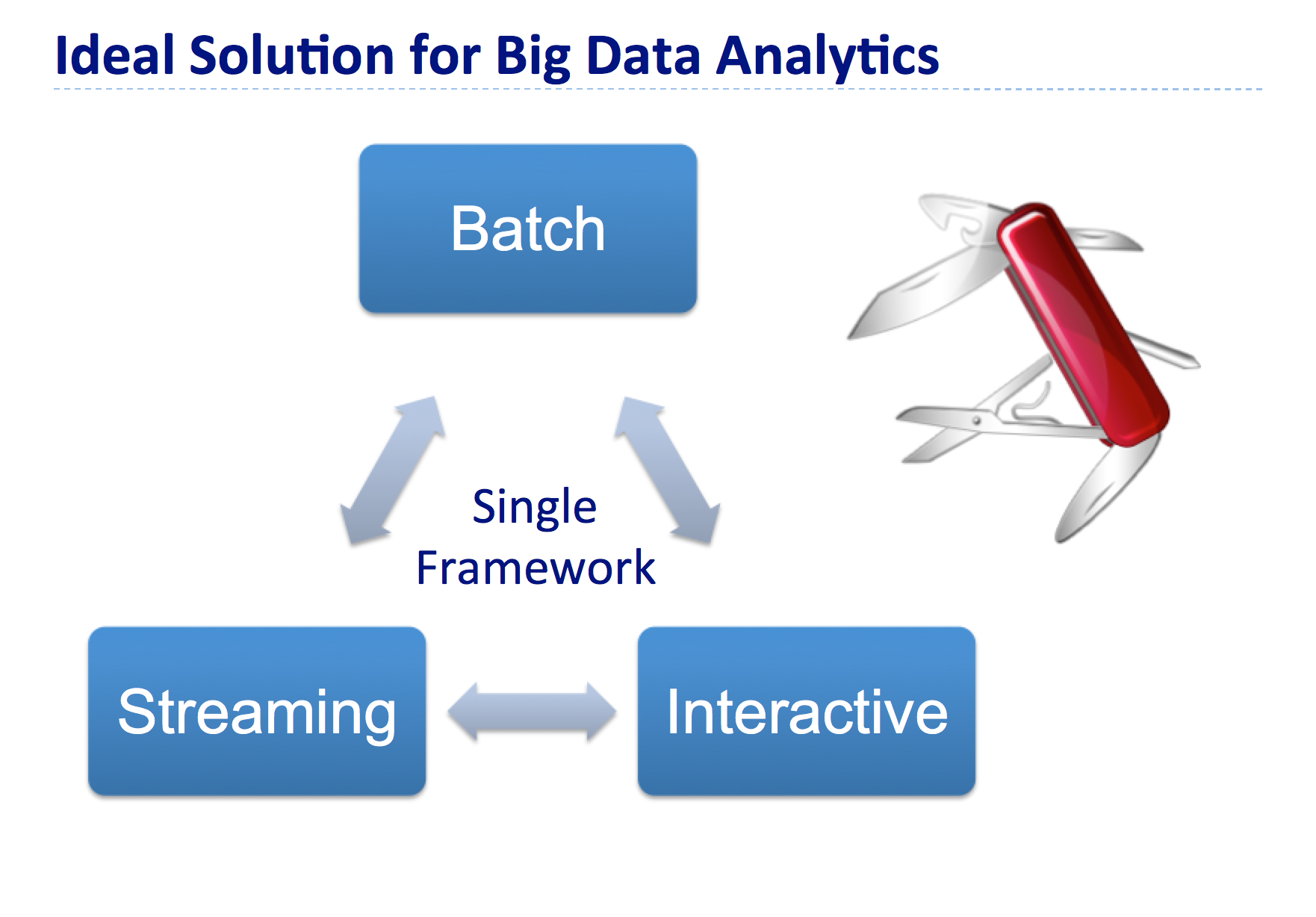
而通过Apache Spark,上述问题迎刃而解!Apache Spark是一个轻量级的内存集群计算平台,通过不同的组件来支撑批、流和交互式用例,如下图:
二、 关于Apache Spark
Apache Spark是个开源和兼容Hadoop的集群计算平台。由加州大学伯克利分校的AMPLabs开发,作为Berkeley Data Analytics Stack(BDAS)的一部分,当下由大数据公司Databricks保驾护航,更是Apache旗下的顶级项目,下图显示了Apache Spark堆栈中的不同组件。

Apache Spark的5大优势
1、更高的性能,因为数据被加载到集群主机的分布式内存中。数据可以被快速的转换迭代,并缓存用以后续的频繁访问需求。很多对Spark感兴趣的朋友可能也会听过这样一句话——在数据全部加载到内存的情况下,Spark可以比Hadoop快100倍,在内存不够存放所有数据的情况下快Hadoop 10倍。

2、通过建立在Java、Scala、Python、SQL(应对交互式查询)的标准API以方便各行各业使用,同时还含有大量开箱即用的机器学习库。
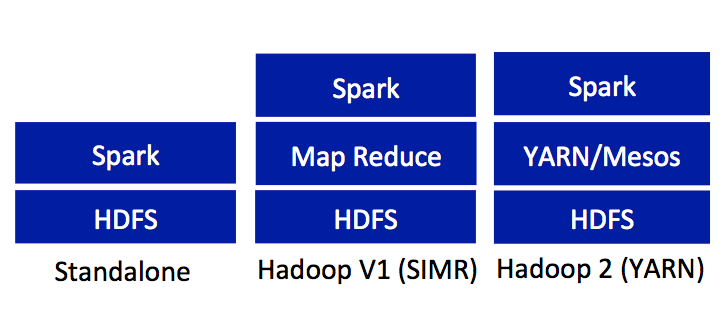
3、与现有Hadoop v1 (SIMR) 和2.x (YARN) 生态兼容,因此机构可以进行无缝迁移。
4、方便下载和安装。方便的shell(REPL: Read-Eval-Print-Loop)可以对API进行交互式的学习。
5、借助高等级的架构提高生产力,从而可以讲精力放到计算上。
同时,Apache Spark由Scala实现,代码非常简洁。
三、安装Apache Spark
下表列出了一些重要链接和先决条件:
| Current Release | 1.0.1 @http://d3kbcqa49mib13.cloudfront.net/spark-1.0.1.tgz |
| Downloads Page | https://spark.apache.org/downloads.html |
| JDK Version (Required) | 1.6 or higher |
| Scala Version (Required) | 2.10 or higher |
| Python (Optional) | [2.6, 3.0) |
| Simple Build Tool (Required) | http://www.scala-sbt.org |
| Development Version | git clone git://github.com/apache/spark.git |
| Building Instructions | https://spark.apache.org/docs/latest/building-with-maven.html |
| Maven | 3.0 or higher |
如上图所示,Apache Spark的部署方式包括standalone、Hadoop V1 SIMR、Hadoop 2 YARN/Mesos。Apache Spark需求一定的Java、Scala或Python知识。这里,我们将专注standalone配置下的安装和运行。
1、安装JDK 1.6+、Scala 2.10+、Python [2.6,3] 和sbt
2、下载Apache Spark 1.0.1 Release
3、在指定目录下Untar和Unzip spark-1.0.1.tgz
test@localhost~/Downloads$ pwd test@localhost~/Downloads$ tar -zxvf spark- 1.0.1.tgz -C ~/spark
4、运行sbt建立Apache Spark
test@localhost~/spark/spark-1.0.1$ pwd ~/spark/spark-1.0.1 test@localhost~/spark/spark-1.0.1$ sbt/sbt assembly
5、发布Scala的Apache Spark standalone REPL
~/spark/spark-1.0.1/bin/spark-shell
如果是Python
~/spark/spark-1.0.1/bin/ pyspark
6、查看SparkUI @ http://localhost:4040
四、Apache Spark的工作模式
Spark引擎提供了在集群中所有主机上进行分布式内存数据处理的能力,下图显示了一个典型Spark job的处理流程。
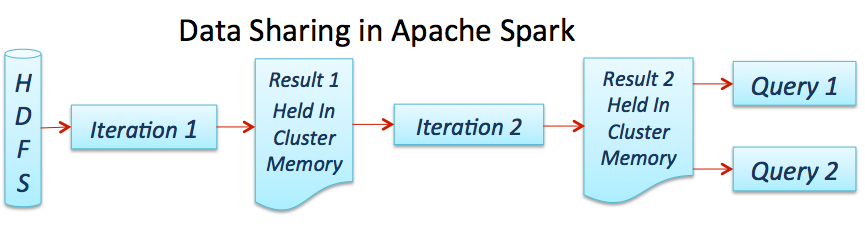
下图显示了Apache Spark如何在集群中执行一个作业:
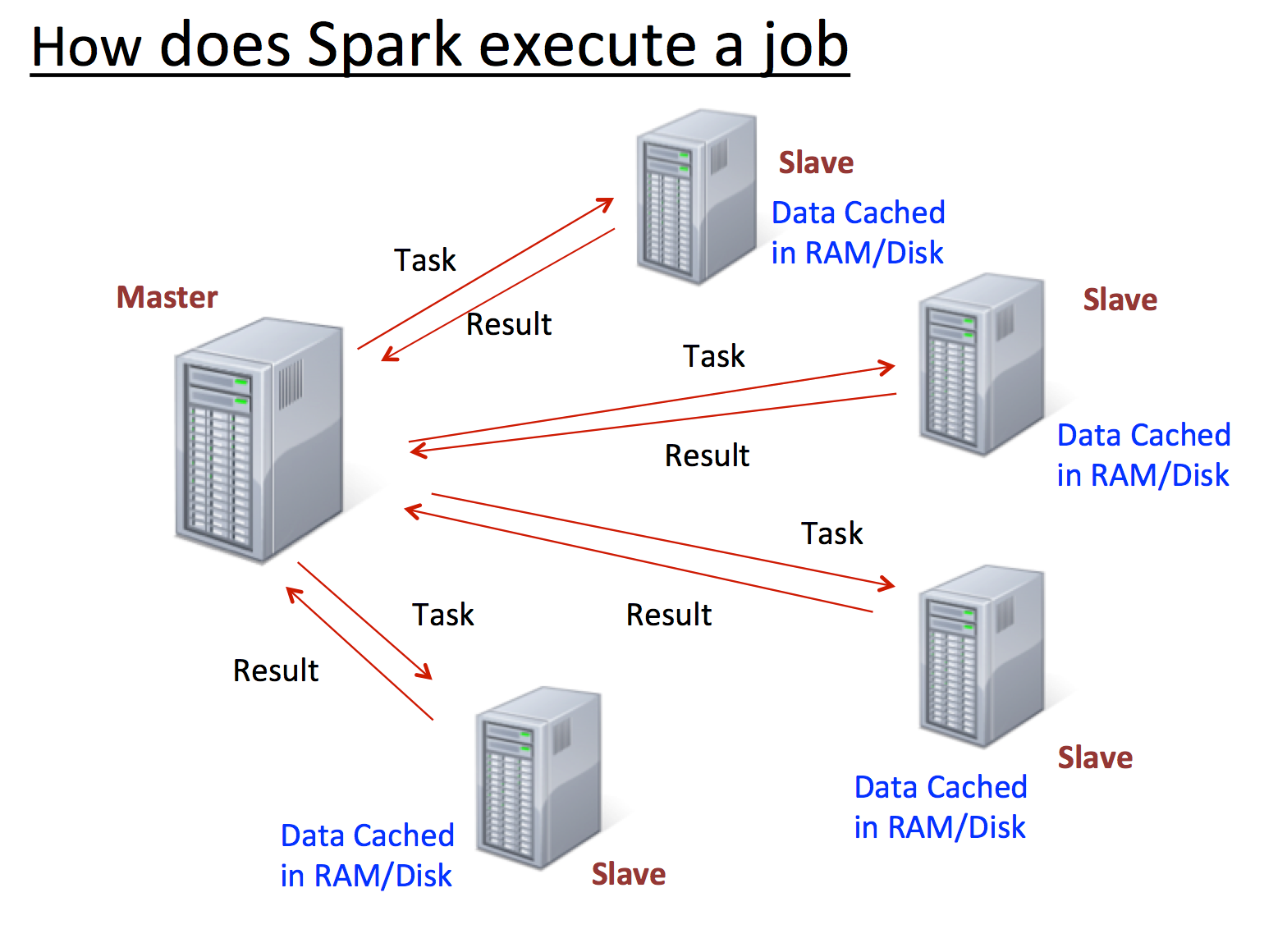
Master控制数据如何被分割,利用了数据本地性,并在Slaves上跟踪所有分布式计算。在某个Slave不可用时,其存储的数据会分配给其他可用的Slaves。虽然当下(1.0.1版本)Master还存在单点故障,但后期必然会被修复。
本文转载自:http://www.csdn.net/article/2015-07-10/2825184,并修改其中部分的错误,如果你英文够好,建议直接看英文。
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Spark快速入门:基本概念和例子(1)】(https://www.iteblog.com/archives/1408.html)







这个,多谢!是不是看不到链接地址呢?