从Apache Zeppelin 0.5.6 版本开始,内置支持 Elasticsearch Interpreter了。我们可以直接在Apache Zeppelin中查询 ElasticSearch 中的数据。但是默认的 Apache Zeppelin 发行版本中可能并没有包含 Elasticsearch Interpreter。这种情况下我们需要自己安装。如果你参照了官方的这篇文档,即使你全部看完这篇文档,也是无法按照上面的说明启用 Elasticsearch Interpre w397090770 7年前 (2017-07-05) 1834℃ 0评论5喜欢
Apache Zeppelin 0.6.2发布。从上一个版本开始,Apache Zeppelin社区就在努力解决对Spark 2.0的支持以及一些Bug的修复。本次共有26位贡献者提供超过40多个补丁改进Apache Zeppelin和Bug修复。从Apache Zeppelin 0.6.1版本开始,编译的时候默认使用Scala 2.11。如果你想使用Scala 2.10来编译Apache Zeppelin,或者安装使用Scala 2.10编译的interpreter请参见官方文 w397090770 8年前 (2016-10-18) 1956℃ 0评论2喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 在前面的两篇文章中我们介绍了如何编译和部署Apache Zeppelin、如何使用Apache Zeppelin。这篇文章中将介绍如何将外部依赖库加入到Apache Zeppelin中。 在现实情况下,我们编写程序一般都是需要依赖外部的相关类库 w397090770 8年前 (2016-02-04) 7980℃ 0评论7喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖使用Apache Zeppelin 编译和启动完Zeppelin相关的进程之后,我们就可以来使用Zeppelin了。我们进入到https://www.iteblog.com:8080页面,我们可以在页面上直接操作Zeppelin,依次选择Notebook->Create new note,然后会弹出一个对话框 w397090770 8年前 (2016-02-03) 25217℃ 2评论31喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析。原生就支持Spark、Scala、SQL 、shell, markdown等。而且它是完全开源的,目前还处于Apache孵化阶段。本文所有的操作都是基于Apache Zeppelin w397090770 8年前 (2016-02-02) 20537℃ 9评论20喜欢
默认情况下,Apache Zeppelin启动Spark是以本地模式起的,master的值是local[*],我们可以通过修改conf/zeppelin-env.sh文件里面的MASTER的值如下:[code lang="bash"]export MASTER= yarn-clientexport HADOOP_HOME=/home/q/hadoop/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/[/code]然后启动Zeppelin,但是我们有时会发现日志出现了以下的异常信息:ERRO w397090770 9年前 (2016-01-22) 12021℃ 16评论12喜欢
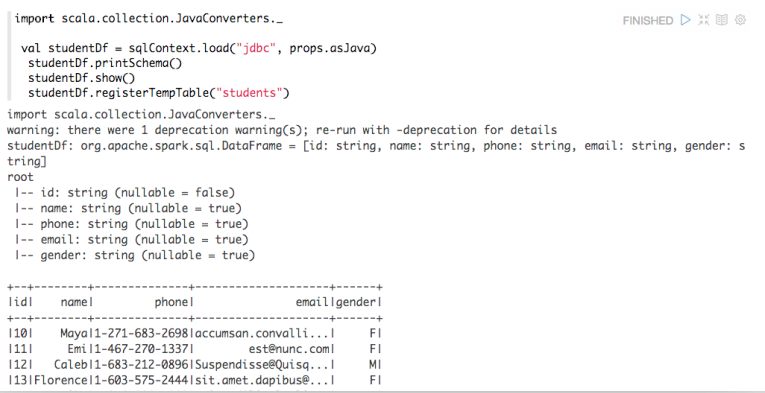
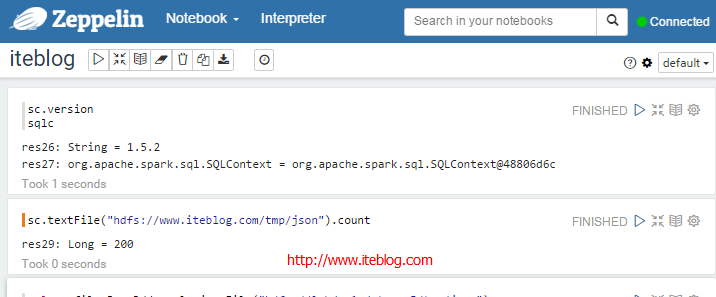
我下载的Apache Zeppelin和Apache Spark版本分别为:0.6.0-incubating-SNAPSHOT和1.5.2,在Zeppelin中使用SQLContext读取Json文件创建DataFrame的过程中出现了以下的异常:[code lanh="scala"]val profilesJsonRdd =sqlc.jsonFile("hdfs://www.iteblog.com/tmp/json")val profileDF=profilesJsonRdd.toDF()profileDF.printSchema()profileDF.show()profileDF.registerTempTable("profiles") w397090770 9年前 (2016-01-21) 6813℃ 2评论11喜欢