近日,由华为团队开发的Spark-SQL-on-HBase项目通过Spark SQL/DataFrame并调用Hbase内置的访问API读取HBase上面的数据,该项目具有很好的可扩展性和可靠性。这个项目具有以下的特点: 1、基于部分评估技术,该项目具有强大的数据剪枝和智能扫描特点; 2、支持自定义过滤规则、协处理器等以便支持超低延迟的处理; 3 w397090770 9年前 (2015-07-23) 22575℃ 0评论22喜欢
Apache Spark于北京时间2015年07月16日05点正式发布。Spark 1.4.1主要是维护版本,包含了大量的稳定性修复。该版本是基于branch-1.4分支。社区推荐所有1.4.0使用升级到这个稳定版本。此版本有85位开发者参与。 Spark 1.4.1包含了大量的Bug修复,这些Bug出现在Spark的DataFrame、外部数据源支持以及其他组建的一些bug修复。一些比较重要 w397090770 9年前 (2015-07-16) 4332℃ 0评论10喜欢
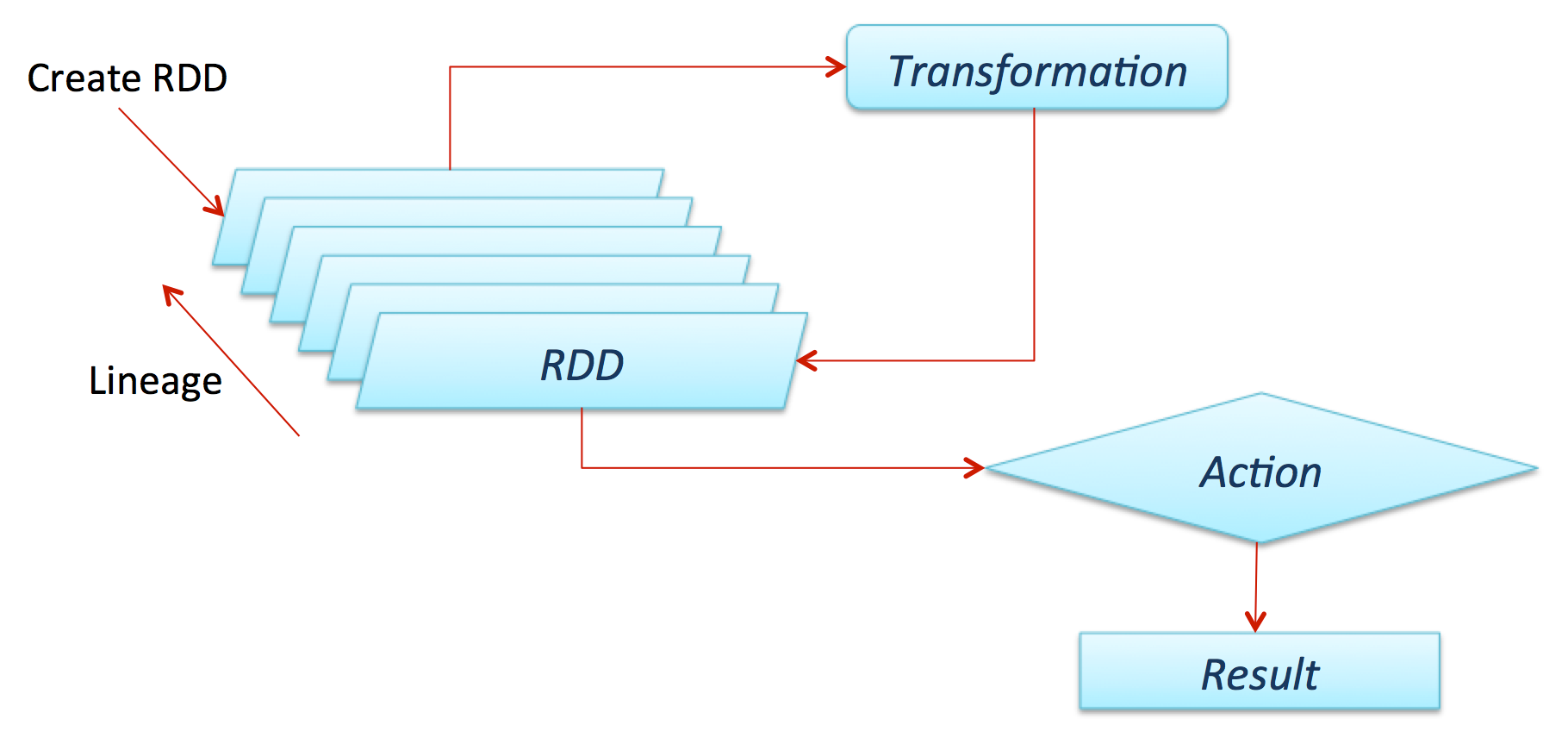
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》五、弹性分布式数据集(Resilient Distributed Dataset,RDD) 弹性分布式数据集(RDD,从Spark 1.3版本开始已被DataFrame替代)是Apache Spark的核心理念。它是由数据组成的不可变分布式集合,其主要进行两个操作:transformation和action。Tr w397090770 9年前 (2015-07-13) 7650℃ 0评论8喜欢
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》 本文聚焦Apache Spark入门,了解其在大数据领域的地位,覆盖Apache Spark的安装及应用程序的建立,并解释一些常见的行为和操作。一、 为什么要选择Apache Spark 当前,我们正处在一个“大数据"的时代,每时每刻,都有各 w397090770 9年前 (2015-07-13) 6085℃ 1评论24喜欢
在MapReduce作业中的数据输入和输出必须使用到相关的InputFormat和OutputFormat类,来指定输入数据的格式,InputFormat类的功能是为map任务分割输入的数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop InputFormat类中必须指定Map输入参数Key和Value的数据类型,以及对输入的数据如何进行分 w397090770 9年前 (2015-07-11) 5423℃ 0评论14喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-07-09) 3371℃ 1评论3喜欢
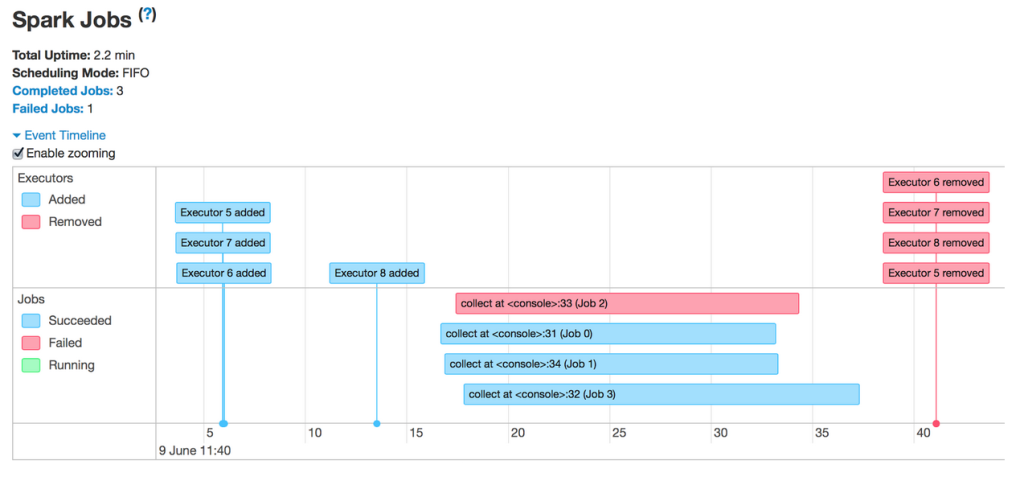
在过去,Spark UI一直是用户应用程序调试的帮手。而在最新版本的Spark 1.4中,我们很高兴地宣布,一个新的因素被注入到Spark UI——数据可视化。在此版本中,可视化带来的提升主要包括三个部分:Spark events时间轴视图Execution DAGSpark Streaming统计数字可视化我们会通过一个系列的两篇博文来介绍上述特性,本次则主要分享前 w397090770 9年前 (2015-07-08) 5812℃ 1评论13喜欢
Apache Hadoop 2.7.1于美国时间2015年07月06日正式发布,本版本属于稳定版本,是自Hadoop 2.6.0以来又一个稳定版,同时也是Hadoop 2.7.x版本线的第一个稳定版本,也是 2.7版本线的维护版本,变化不大,主要是修复了一些比较严重的Bug(其中修复了131个Bugs和patches)。比较重要的特性请参见《Hadoop 2.7.0发布:不适用于生产和不支持JDK1.6》 w397090770 9年前 (2015-07-08) 17835℃ 0评论23喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-07-06) 5298℃ 0评论7喜欢
上海Spark Meetup第五次聚会将于2015年7月18日在太库科技创业发展有限公司举办,详细地址上海市浦东新区金科路2889弄3号长泰广场 C座12层,太库。本次聚会由七牛和Intel联合举办。大会主题 1、hadoop/spark生态的落地实践 王团结(七牛)七牛云数据平台工程师。主要负责数据平台的设计研发工作。关注大数据处理,高 w397090770 9年前 (2015-07-06) 3146℃ 0评论6喜欢