如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据过往记忆大数据备注:以下的我们均代表 Uber 的 Hadoop 运维团队。介绍随着 Uber 业务的增长,Uber 公司在 5 年内将 Apache Hadoop(本文简称为“Hadoop”)部署扩展到 21000 台以上...... w397090770 4年前 (2021-08-22) 798℃ 0评论4喜欢
摘要:本文整理自 58 同城实时计算平台负责人冯海涛在 Flink Forward Asia 2020 分享的议题《Flink 在 58 同城应用与实践》,内容包括:实时计算平台架实时 SQL 建设Storm 迁移 Flink 实践一站式实时计算平台后续规划如果想及时了解Spark...... w397090770 4年前 (2021-08-17) 347℃ 0评论2喜欢
背景随着集群规模的不断扩张,文件数快速增长,目前集群的文件数已高达2.7亿,这带来了许多问题与挑战。首先是文件目录树的扩大导致的NameNode的堆内存持续上涨,其次是Full GC时间越来越长,导致NameNode宕机越发频繁。此外,受堆内存的影响,RPC延时也越来越高。针对上...... w397090770 4年前 (2021-07-02) 1449℃ 0评论4喜欢
Data + AI Summit 2021 于2021年05月24日至28日举行。本次会议是在线举办的,一共为期五天,第一、二天是培训,第三天到第五天是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,会议涵盖来自从业者的技术内容,他们将使用 Apache Spark™、Delta...... w397090770 4年前 (2021-06-20) 1717℃ 0评论3喜欢
导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用...... w397090770 4年前 (2021-04-05) 1387℃ 0评论4喜欢
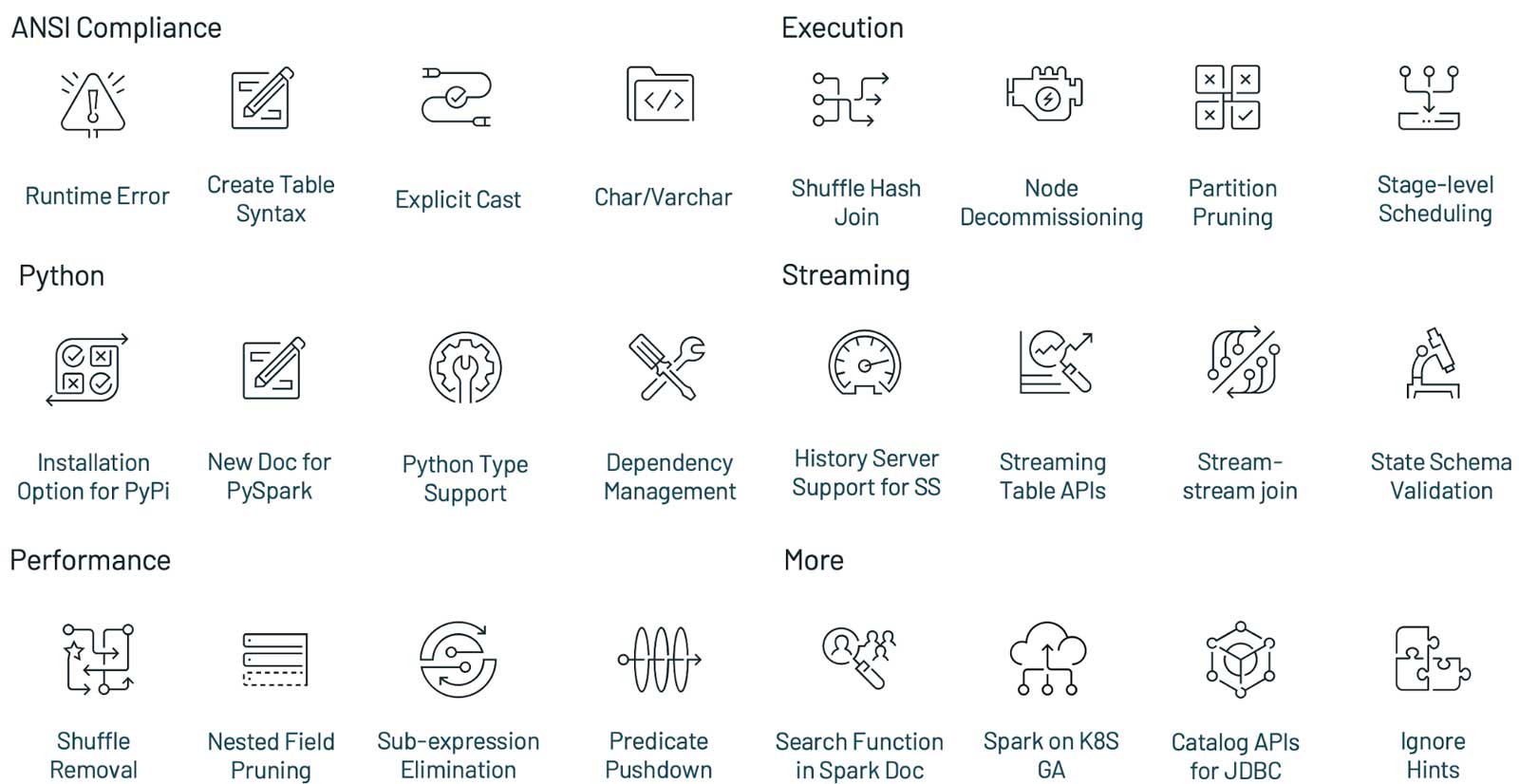
Apache Spark 3.1.1 版本于美国当地时间2021年3月2日正式发布,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server ...... w397090770 4年前 (2021-03-03) 2399℃ 0评论10喜欢
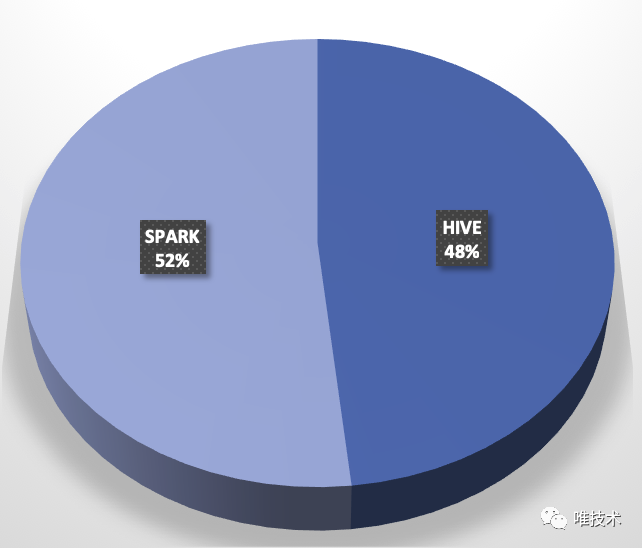
桔妹导读:在滴滴SQL任务从Hive迁移到Spark后,Spark SQL任务占比提升至85%,任务运行时间节省40%,运行任务需要的计算资源节省21%,内存资源节省49%。在迁移过程中我们沉淀出一套迁移流程, 并且发现并解决了两个引擎在语法,UDF,性能和功能方面的差异。迁移背景Spark自...... w397090770 5年前 (2021-01-28) 2674℃ 0评论10喜欢
本文作者:车好多大数据 OLAP 团队-王培,由车好多大数据 OLAP 团队相关同事投稿。Presto 简介简介Presto 最初是由 Facebook 开发的一个分布式 SQL 执行引擎, 它被设计为用来专门进行高速、实时的数据分析,以弥补 Hive 在速度和对接多种数据源上的短板。发展历史如下:...... w397090770 5年前 (2020-12-21) 1004℃ 0评论3喜欢
本文来自车好多大数据离线存储团队相关同事的投稿,本文作者: 车好多大数据离线存储团队:冯武、王安迪。升级的背景HDFS 集群作为大数据最核心的组件,在公司承载了DW、AI、Growth 等重要业务数据的存储重任。随着业务的高速发展,数据的成倍增加,HDFS 集群出现了爆炸式...... w397090770 5年前 (2020-11-24) 1456℃ 0评论2喜欢
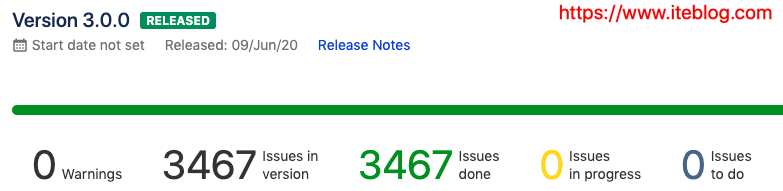
原计划在2019年年底发布的 Apache Spark 3.0.0 今天终于赶在下周二举办的 Spark Summit AI 会议之前正式发布了! Apache Spark 3.0.0 自2018年10月02日开发到目前已经经历了近21个月!这个版本的发布经历了两个预览版以及三次投票:2019年11月06日第一次预览版,参见 https...... w397090770 5年前 (2020-06-18) 1907℃ 0评论4喜欢