这个文档只是简单的介绍如何快速地使用Spark。在下面的介绍中我将介绍如何通过Spark的交互式shell来使用API。Basics Spark shell提供一种简单的方式来学习它的API,同时也提供强大的方式来交互式地分析数据。Spark shell支持Scala和Python。可以通过以下方式进入到...... w397090770 11年前 (2014-06-10) 77179℃ 26评论156喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复...... w397090770 11年前 (2014-06-06) 30860℃ 40评论6喜欢
Spark 1.0.0于5月30日正式发布,可以到http://spark.apache.org/downloads.html页面下载。Spark 1.0.0是一个主要版本,它标志着Spark已经进入了1.X的时代。这个版本的Spark带来了很多新特性和强API的支持。 Spark 1.0加入了一个主要的组件: Spark SQL,这个组件支持在S...... w397090770 11年前 (2014-06-04) 5367℃ 1评论3喜欢
这几天在集群上部署了Shark 0.9.1,我下载的是已经编译好的,Hadoop版本是2.2.0,下面就总结一下我在安装Shark的过程中遇到的问题及其解决方案。一、YARN mode not available ?Exception in thread "main" org.apache.spark.SparkException: YARN mode not av...... w397090770 11年前 (2014-05-05) 16155℃ 3评论4喜欢
根据官方文档,Spark可以用Maven进行编译,但是我试了好几个版本都编译不通过,所以没用(如果大家用Maven编译通过了Spark,求分享。)。这里是利用sbt对Spark进行编译。中间虽然也遇到了很多问题,但是经过几天的折腾,终于通过了,关于如何解决编译中间出现的问题,可...... w397090770 11年前 (2014-04-18) 11164℃ 3评论7喜欢
这个月的4月7号,Apache Hadoop 2.4.0已经发布了,Hadoop 2.4.0是2014年第二个Hadoop发布版本(在2月20日发布了Apache Hadoop 2.3.0),他在HDFS上做了一些加强,比如对异构存储层次的支持和通过数据节点为存储在HDFS中的数据提供了内存缓存功能。在Hadoop2.4.0主要做了...... w397090770 11年前 (2014-04-12) 8161℃ 0评论3喜欢
如果你想知道Spark作业运行日志,可以查看这里《Spark应用程序运行的日志存在哪里》 Hadoop的日志有很多种,很多初学者往往遇到错而不知道怎么办,其实这时候就应该去看看日志里面的输出,这样往往可以定位到错误。Hadoop的日志大致可以分为两类:(1)、Hadoop系...... w397090770 12年前 (2014-03-14) 53239℃ 5评论40喜欢
分布式计算开源框架Hadoop近日发布了今年的第一个版本Hadoop-2.3.0,新版本不仅增强了核心平台的大量功能,同时还修复了大量bug。新版本对HDFS做了两个非常重要的增强:(1)、支持异构的存储层次;(2)、通过数据节点为存储在HDFS中的数据提供了内存缓存功能。 借...... w397090770 12年前 (2014-03-02) 4222℃ 0评论1喜欢
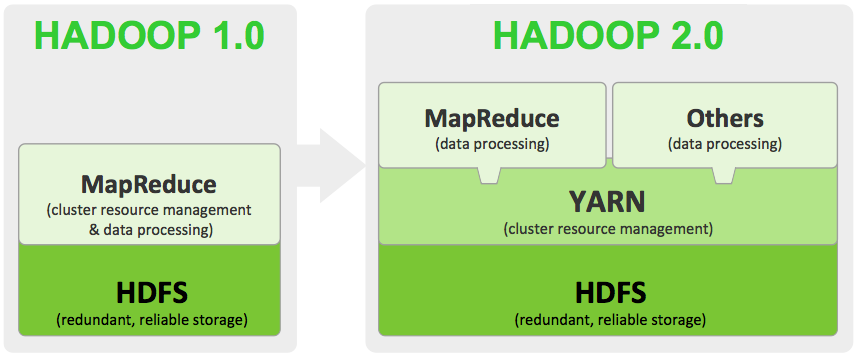
hadoop更新实在是太快了,现在已经更新到Hadoop-2.3.0版本(2014-02-11)。看了一下文档,和之前Hadoop-2.2.0的文档大部分类似,这篇文章主要是翻译一下Hadoop-2.3.0的文档。 Apache Hadoop 2.3.0和之前的Hadoop-1.x稳定版有了很大的提升。本篇文章主要是简要说说Ha...... w397090770 12年前 (2014-02-26) 7620℃ 2评论2喜欢
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务...... w397090770 12年前 (2014-02-17) 30129℃ 8评论30喜欢