Spark 1.2.0于美国时间2014年12月18日发布,Spark 1.2.0兼容Spark 1.0.0和1.1.0,也就是说不需要修改代码即可用,很多默认的配置在Spark 1.2发生了变化 1、spark.shuffle.blockTransferService由nio改成netty 2、spark.shuffle.manager由hash改成sort 3、在...... w397090770 11年前 (2014-12-19) 4647℃ 1评论2喜欢
Hadoop 2.5.2 w397090770 11年前 (2014-12-01) 11905℃ 0评论5喜欢
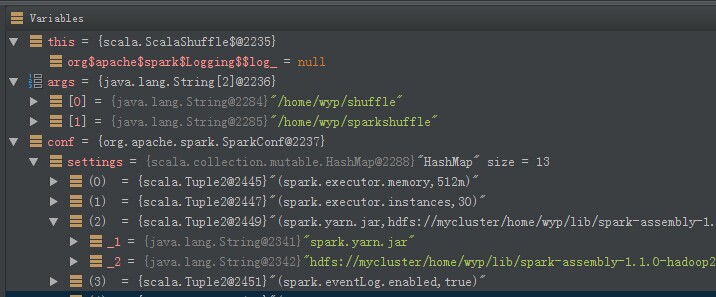
每次当你在Yarn上以Cluster模式提交Spark应用程序的时候,通过日志我们总可以看到下面的信息:21 Oct 2014 14:23:22,006 INFO [main] (org.apache.spark.Logging$class.logInfo:59) - Uploading file:/home/spark-1.1.0-bin-2.2.0/lib/spark-assembly-1.1.0-hado...... w397090770 11年前 (2014-11-10) 11035℃ 2评论12喜欢
我们在编写Spark Application或者是阅读源码的时候,我们很想知道代码的运行情况,比如参数设置的是否正确等等。用Logging方式来调试是一个可以选择的方式,但是,logging方式调试代码有很多的局限和不便。今天我就来介绍如何通过IDE来远程调试Spark的Application或者是Spar...... w397090770 11年前 (2014-11-05) 24107℃ 16评论21喜欢
《Spark源码分析:多种部署方式之间的区别与联系(1)》《Spark源码分析:多种部署方式之间的区别与联系(2)》 在《Spark源码分析:多种部署方式之间的区别与联系(1)》我们谈到了SparkContext的初始化过程会做好几件事情(这里就不再列出,可以去《Spark源码分析:多种...... w397090770 11年前 (2014-10-28) 7766℃ 6评论8喜欢
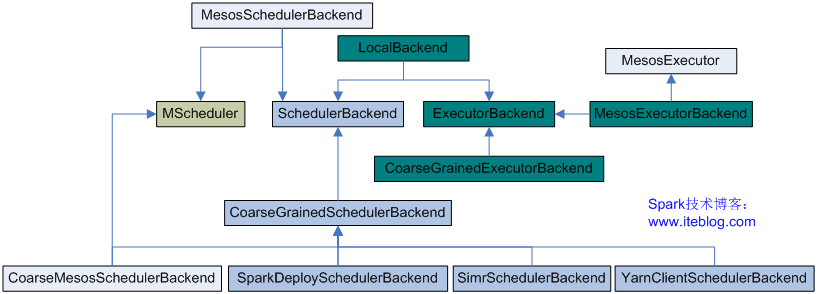
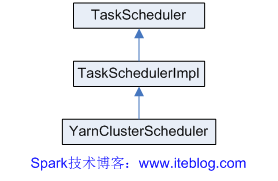
《Spark源码分析:多种部署方式之间的区别与联系(1)》 《Spark源码分析:多种部署方式之间的区别与联系(2)》 从官方的文档我们可以知道,Spark的部署方式有很多种:local、Standalone、Mesos、YARN.....不同部署方式的后台处理进程是不一样的,但是如果我们从...... w397090770 11年前 (2014-10-24) 7775℃ 2评论14喜欢
Spark支持三种模式的部署:YARN、Standalone以及Mesos。本篇说到的Worker只有在Standalone模式下才有。Worker节点是Spark的工作节点,用于执行提交的作业。我们先从Worker节点的启动开始介绍。 Spark中Worker的启动有多种方式,但是最终调用的都是org.apache.spark....... w397090770 11年前 (2014-10-08) 11454℃ 3评论7喜欢
Spark 1.1.0中兼容大部分Hive特性,我们可以在Spark中使用Hive。但是默认的Spark发行版本并没有将Hive相关的依赖打包进spark-assembly-1.1.0-hadoop2.2.0.jar文件中,官方对此的说明是:Spark SQL also supports reading and writing data stored in Apache Hive. Howe...... w397090770 11年前 (2014-09-26) 12978℃ 5评论9喜欢
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 但是Spark官方文档给出的属性只是简单的介绍了一下含义,许多细节并没有涉及到。本文及以后几篇文章将会对Spark官方的各个属性进行说明介绍。以下是根据Spark 1.1.0文档中的属性进行说明。Application相...... w397090770 11年前 (2014-09-25) 18138℃ 1评论20喜欢
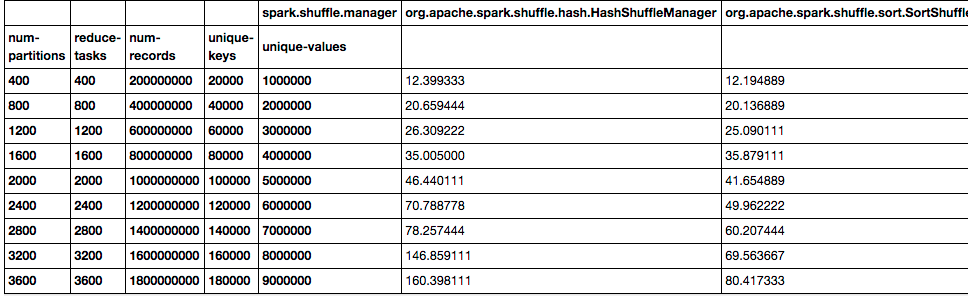
我们都知道Hadoop中的shuffle(不知道原理?可以参见《MapReduce:详细介绍Shuffle的执行过程》),Hadoop中的shuffle是连接map和reduce之间的桥梁,它是基于排序的。同样,在Spark中也是存在shuffle,Spark 1.1之前,Spark的shuffle只存在一种方式实现方式,也就是基于...... w397090770 11年前 (2014-09-23) 15821℃ 3评论15喜欢