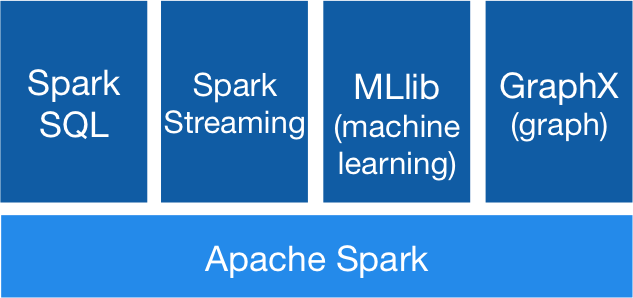
如果你要寻求一种处理海量数据的解决方案,就会有很多可选项。选择哪一种取决于具体的用例和要对数据进行何种操作,可以从很多种数据处理框架中进行遴选。例如Apache的Samza、Storm和Spark等等。本文将重点介绍Spark的功能,Spark不但非常适合用来对数据进行批处理,也...... w397090770 9年前 (2017-02-06) 1712℃ 0评论4喜欢
Apache Flink 1.1.4于2016年12月21日正式发布,本版本是Flink的最新稳定版本,主要以修复Bug为主;强烈推荐所有的用户升级到Flink 1.1.4版本,替换pom中的以为如下:<dependency> <groupId>org.apache.flink</groupId> <artifactId>fl...... w397090770 9年前 (2016-12-27) 2400℃ 0评论3喜欢
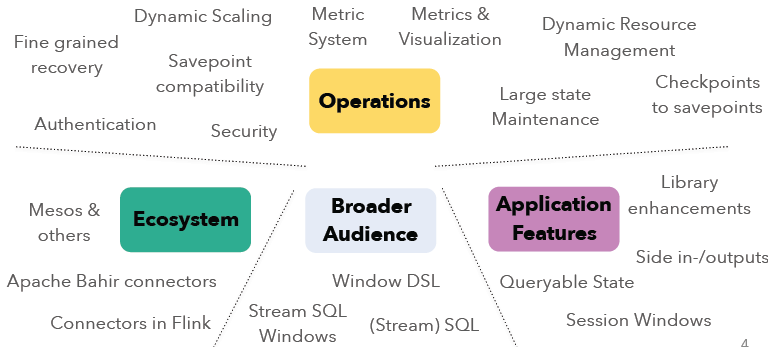
本文将概述即将发布的Apache Flink 1.2.0新功能。在Apache Flink 1.1+版本上,社区主要的集中点在操作性(Operations)、生态系统(Ecosystem)、更广泛的用户(Broader Audience)以及应用特性(Application Features)等方面的开发。各个模块的开发主要包括了如下的方...... w397090770 9年前 (2016-12-18) 2936℃ 0评论4喜欢
本书是《Hadoop权威指南》第三版,新版新特色,内容更详细。本书是为程序员写的,可帮助他们分析任何大小的数据集。本书同时也是为管理员写的,帮助他们了解如何设置和运行Hadoop集群。 本书通过丰富的案例学习来解释Hadoop的幕后机理,阐述了Hadoop如何解决现实生...... zz~~ 9年前 (2016-12-16) 17488℃ 0评论43喜欢
本书作者Venkat Ankam,由Packt Publishing出版社在2016年09月发行,全书供326页。本书基于Spark 2.0和Hadoop 2.7版本介绍,是适合数据分析师和数据科学家的参考手册,当然也适合那些想入门的人。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:...... zz~~ 9年前 (2016-11-21) 4815℃ 0评论6喜欢
流式处理是大数据应用中的非常重要的一环,在Spark中Spark Streaming利用Spark的高效框架提供了基于micro-batch的流式处理框架,并在RDD之上抽象了流式操作API DStream供用户使用。 随着流式处理需求的复杂化,用户希望在流式数据中引入较为复杂的查询和分析,传统...... w397090770 9年前 (2016-11-16) 6146℃ 0评论13喜欢
最近写了一个Spark程序用来读取Hbase中的数据,我的Spark版本是1.6.1,Hbase版本是0.96.2-hadoop2,当程序写完之后,使用下面命令提交作业:[iteblog@www.iteblog.com $] bin/spark-submit --master yarn-cluster --executor-memory 4g --num-executors 5 --queue ite...... w397090770 9年前 (2016-11-03) 3717℃ 0评论7喜欢
Apache Flink 1.1.3仍然在Flink 1.1系列基础上修复了一些Bug,推荐所有用户升级到Flink 1.1.3,只需要在你相关工程的pom.xml文件里面加入以下依赖:<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</art...... w397090770 9年前 (2016-10-16) 1618℃ 0评论5喜欢
我在《Hadoop&Spark解决二次排序问题(Hadoop篇)》文章中介绍了如何在Hadoop中实现二次排序问题,今天我将介绍如何在Spark中实现。问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value...... w397090770 9年前 (2016-10-08) 6293℃ 0评论12喜欢
Apache Hadoop 3.0.0-alpha1相对于hadoop-2.x来说包含了许多重要的改进。这里介绍的是Hadoop 3.0.0的alpha版本,主要是便于检测和收集应用开发人员和其他用户的使用反馈。因为是alpha版本,所以本版本的API稳定性和质量没有保证,如果需要在正式开发中使用,请耐心等待稳定...... zz~~ 9年前 (2016-09-22) 3420℃ 0评论7喜欢


![[电子书]Hadoop权威指南第3版中文版PDF下载](https://www.iteblog.com/pic/Hadoop_the_definitive_guide_Third_Edition.jpg)
![[电子书]Big Data Analytics pdf下载](https://www.iteblog.com/pic/big-data-analytics-iteblog.jpg)



