ScalikeJDBC是一款给Scala开发者使用的简洁DB访问类库,它是基于SQL的,使用者只需要关注SQL逻辑的编写,所有的数据库操作都交给ScalikeJDBC。这个类库内置包含了JDBC API,并且给用户提供了简单易用并且非常灵活的API。并且,QueryDSL使你的代码类型安全的并且可重复使用。我们可以在生产环境大胆地使用这款DB访问类库。工作 w397090770 8年前 (2016-03-10) 4259℃ 0评论4喜欢
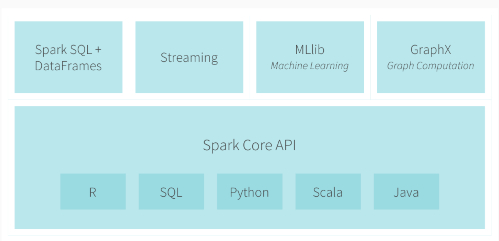
现在Apache Spark已形成一个丰富的生态系统,包括官方的和第三方开发的组件或工具。后面主要给出5个使用广泛的第三方项目。Spark官方构建了一个非常紧凑的生态系统组件,提供各种处理能力。 下面是Spark官方给出的生态系统组件 1、Spark DataFrames:列式存储的分布式数据组织,类似于关系型数据表。 2、Spark SQL:可 w397090770 8年前 (2016-03-08) 4925℃ 2评论7喜欢
XML(可扩展标记语言,英语:eXtensible Markup Language,简称: XML)是一种标记语言,也是行业标准数据交换交换格式,它很适合在系统之间进行数据存储和交换(话说Hadoop、Hive等的配置文件就是XML格式的)。本文将介绍如何使用MapReduce来读取XML文件。但是Hadoop内部是无法直接解析XML文件;而且XML格式中没有同步标记,所以并行地处 w397090770 8年前 (2016-03-07) 5729℃ 1评论7喜欢
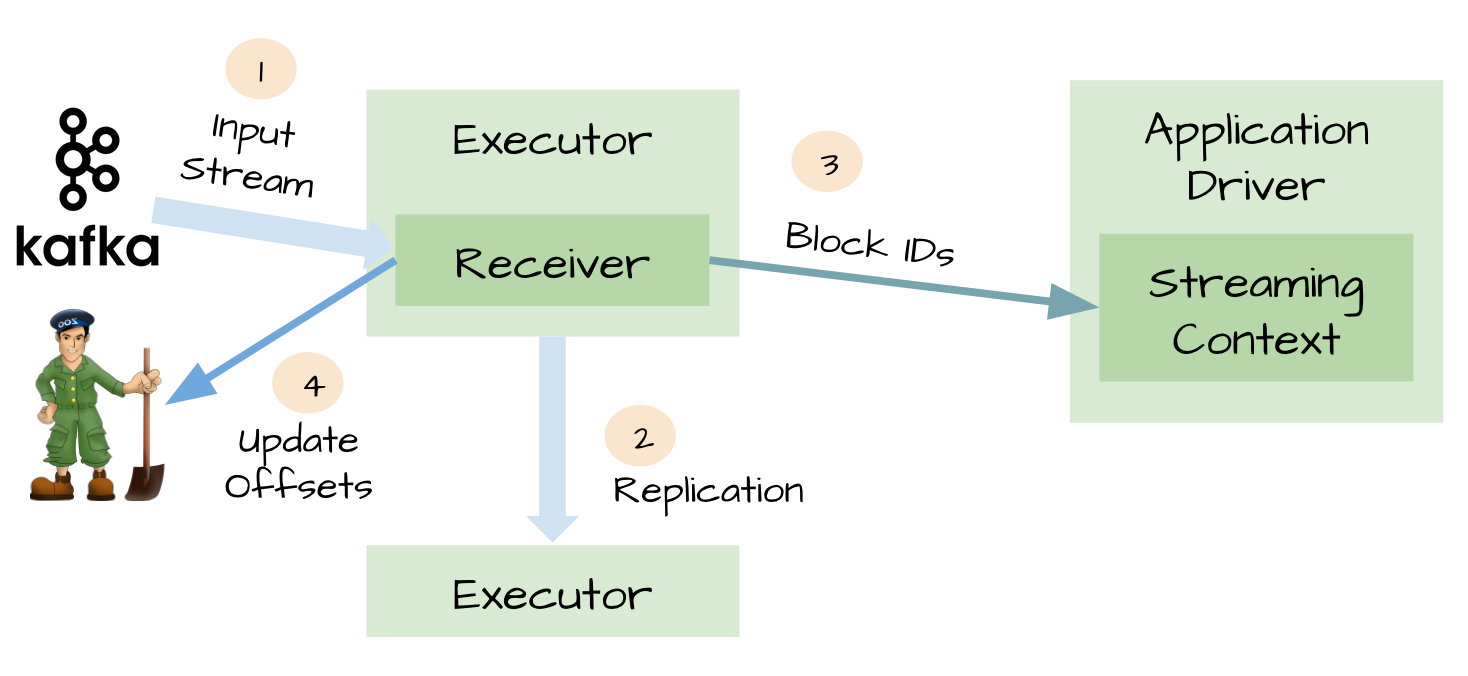
Spark Streaming除了可以使用内置的接收器(Receivers,比如Flume、Kafka、Kinesis、files和sockets等)来接收流数据,还可以自定义接收器来从任意的流中接收数据。开发者们可以自己实现org.apache.spark.streaming.receiver.Receiver类来从其他的数据源中接收数据。本文将介绍如何实现自定义接收器,并且在Spark Streaming应用程序中使用。我们可以用S w397090770 8年前 (2016-03-03) 5857℃ 2评论4喜欢
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。为了体验这个关键的特性,你需要满足以下几个先决条件: 1、输入的数据来自可靠的数据源和可靠的接收器; 2、应用程序的metadata被application的driver持久化了(checkpointed ); 3、启用了WAL特性(Write ahead log)。 下面我将简单 w397090770 8年前 (2016-03-02) 17560℃ 16评论50喜欢
即日起,关注@Spark技术博客 及@ 一位微博好友并转发本文章到微博有机会获取《Spark大数据分析实战》:/archives/1590。3月12日在微博抽奖平台抽取1位同学并赠送此书。本活动已经结束,抽奖信息已经在新浪微博抽奖平台公布 《Spark大数据分析实战》由高彦杰和倪亚宇编写,通过典型数据分析应用场景、算法与系统架构,结 w397090770 8年前 (2016-03-02) 8438℃ 0评论44喜欢
在开发Wordpress的时候,我们可能需要获取到设备的类型,比如手机、电脑或者iPad等,然后做出不同的决定,这就要求我们精确地判断出当前设备的类型。熟悉Wordpress的同学会知道,Wordpress中安装目录下的wp-includes/vars.php文件里面有个名为wp_is_mobile的函数,其代码如下:[code lang="php"]function wp_is_mobile() { static $is_mobile = null; w397090770 8年前 (2016-03-01) 2089℃ 0评论1喜欢
Apache Arrow是Apache基金会下一个全新的开源项目,同时也是顶级项目。它的目的是作为一个跨平台的数据层来加快大数据分析项目的运行速度。 用户在应用大数据分析时除了将Hadoop等大数据平台作为一个经济的存储和批处理平台之外也很看重分析系统的扩展性和性能。过去几年开源社区已经发布了很多工具来完善大数据分 w397090770 8年前 (2016-03-01) 3785℃ 0评论2喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop在使用Git的时候,比如push操作,需要我们输入用户名和密码,如下:[code lang="bash"]D:\iteblog\spark>git push origin initUsername for 'http://gitlab.iteblog.com': iteblogPassword for 'http://iteblog@gitlab.iteblog.com':[/code]如果频繁地进行push等需要输入用户名和密码 w397090770 8年前 (2016-02-29) 2795℃ 0评论4喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 8年前 (2016-02-27) 5602℃ 0评论14喜欢






![Spark Summit East 2016 PPT免费下载[共65个]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/5.jpg)