这是许多kafka使用者经常会问到的一个问题。本文的目的是介绍与本问题相关的一些重要决策因素,并提供一些简单的计算公式。越多的分区可以提供更高的吞吐量 首先我们需要明白以下事实:在kafka中,单个patition是kafka并行操作的最小单元。在producer和broker端,向每一个分区写入数据是可以完全并行化的,此时,可 w397090770 8年前 (2016-09-08) 10316℃ 2评论22喜欢
Streaming job 的调度与执行 我们先来看看如下 job 调度执行流程图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop为什么很难保证 exactly once 上面这张流程图最主要想说明的就是,job 的提交执行是异步的,与 checkpoint 操作并不是原子操作。这样的机制会引起数据重复消费问题: zz~~ 8年前 (2016-09-08) 8908℃ 5评论12喜欢
相关文章:《Apache Flink 1.1.0和1.1.1发布,支持SQL》 Apache Flink 1.1.2于2016年09月05日正式发布,此版本主要是修复一些小bug,推荐所有使用Apache Flink 1.1.0以及Apache Flink 1.1.1的用户升级到此版本,我们可以在pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</a zz~~ 9年前 (2016-09-06) 1363℃ 0评论1喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第四篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 9年前 (2016-09-04) 7478℃ 0评论8喜欢
样本数据集 现在我们对于基本的东西已经有了一些认识,现在让我们尝试使用一些更加贴近现实的数据集。我准备了一些假想的客户银行账户信息的JSON文档样本。文档具有以下的模式(schema):[code lang="java"]{ "account_number": 0, "balance": 16623, "firstname": "Bradshaw", "lastname": &quo zz~~ 9年前 (2016-09-04) 1060℃ 0评论5喜欢
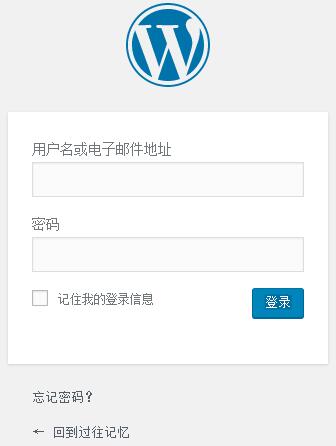
默认情况下,使用WordPress系统的博客登录页面都比较简单,登陆页面显示的logo是WordPress 的logo,链接也是WordPress的链接,如下图所示:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 值得高兴的是,WordPress博客系统为我们提供了很多钩子(hook)来自定义这些信息,比如Logo、链接、提 w397090770 9年前 (2016-09-03) 1921℃ 0评论6喜欢
Elasticsearch提供了近乎实时的数据操作和搜索功能。默认情况下,从你索引/更新/删除你的数据动作开始到它出现在你的搜索结果中,大概会有1秒钟的延迟。这和其它的SQL平台不同,它们的数据在一个事务完成之后就会立即可用。索引/替换文档 我们先前看到,怎样索引一个文档。现在我们再次调用那个命令:[code lan zz~~ 9年前 (2016-09-03) 1584℃ 0评论4喜欢
使用MapReduce解决任何问题之前,我们需要考虑如何设计。并不是任何时候都需要map和reduce job。MapReduce设计模式(MapReduce Design Pattern)整个MapReduce作业的阶段主要可以分为以下四种: 1、Input-Map-Reduce-Output 2、Input-Map-Output 3、Input-Multiple Maps-Reduce-Output 4、Input-Map-Combiner-Reduce-Output下面我将一一介绍哪种 w397090770 9年前 (2016-09-01) 5757℃ 0评论16喜欢
本文将介绍使用Spark batch作业处理存储于Hive中Twitter数据的一些实用技巧。首先我们需要引入一些依赖包,参考如下:[code lang="scala"]name := "Sentiment"version := "1.0"scalaVersion := "2.10.6"assemblyJarName in assembly := "sentiment.jar"libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.6.0&qu zz~~ 9年前 (2016-08-31) 3338℃ 0评论5喜欢
rest 接口 现在我们已经有一个正常运行的节点(和集群),下一步就是要去理解怎样与其通信。幸运的是,Elasticsearch提供了非常全面和强大的REST API,利用这个REST API你可以同你的集群交互。下面是利用这个API,可以做的几件事情: 1、查你的集群、节点和索引的健康状态和各种统计信息 2、管理你的集群、节点、 zz~~ 9年前 (2016-08-31) 1440℃ 0评论2喜欢