Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;TableIn w397090770 6年前 (2019-04-02) 13268℃ 5评论18喜欢
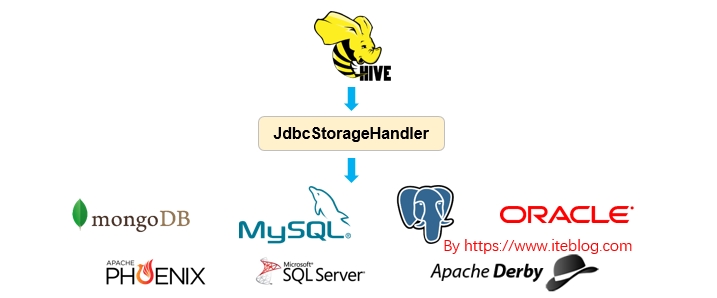
Apache Hive 从 HIVE-1555 开始引入了 JdbcStorageHandler ,这个使得 Hive 能够读取 JDBC 数据源,关于 Apache Hive 引入 JdbcStorageHandler 的背景可以参见 《Apache Hive 联邦查询(Query Federation)》。本文主要简单介绍 JdbcStorageHandler 的使用。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop语法JdbcStorageHandler 使 w397090770 6年前 (2019-04-01) 3713℃ 0评论9喜欢
Apache Cassandra 是一个开源的、分布式、无中心、弹性可扩展、高可用、容错、一致性可调、面向行的数据库,它基于 Amazon Dynamo 的分布式设计和 Google Bigtable 的数据模型,由 Facebook 创建,在一些最流行的网站中得到应用。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop为什么会诞生 Apache Cassand w397090770 6年前 (2019-03-31) 3292℃ 4评论6喜欢