为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12544℃ 0评论34喜欢
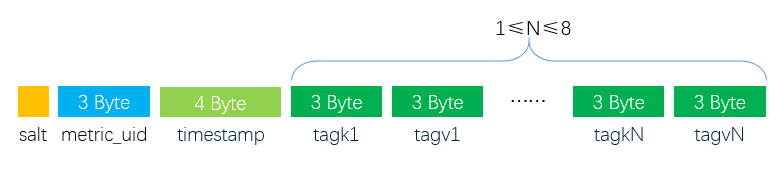
我们在 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章中已经简单介绍了 OpenTSDB 的 RowKey 设计的思路,并简单介绍了列簇以及列名的组成。本文将比较详细的介绍 OpenTSDB 在 HBase 的数据存储模型。OpenTSDB RowKey 设计关于 OpenTSDB 的 RowKey 为什么这么设计可以参见 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》文章了。这里主要介绍 R w397090770 6年前 (2018-12-05) 3008℃ 0评论3喜欢
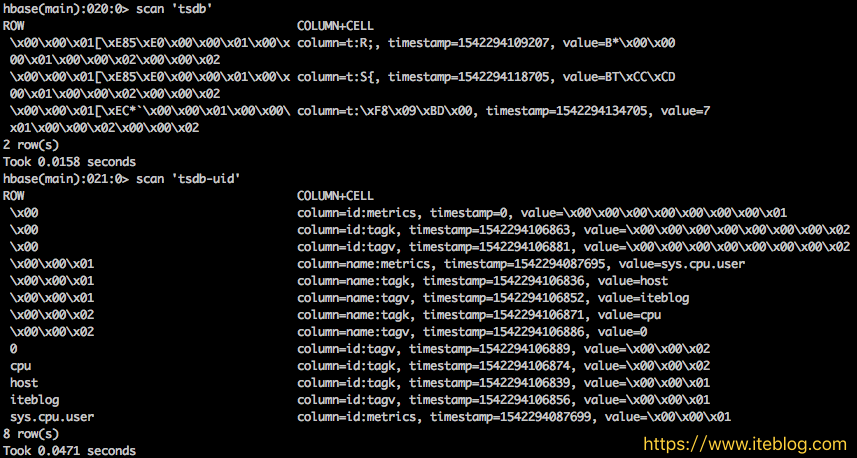
通过《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章我们已经了解 OpenTSDB 底层的 HBase Rowkey 是如何设计的了。我们现在来测试一下 OpenTSDB 导入的时序数据到底长什么样子。在 OpenTSDB 里面默认存时序数据的表为 tsdb。前面说了,每个指标名称、标签名称以及标签值都有唯一的编码,这些编码数据是存放在 tsdb-uid 表里面。为了更加 w397090770 6年前 (2018-11-16) 3032℃ 3评论6喜欢
OpenTSDB 是基于 HBase 的可扩展、开源时间序列数据库(Time Series Database),可以用于存储监控数据、物联网传感器、金融K线等带有时间的数据。它的特点是能够提供最高毫秒级精度的时间序列数据存储,能够长久保存原始数据并且不失精度。它拥有很强的数据写入能力,支持大并发的数据写入,并且拥有可无限水平扩展的存储容量。目 w397090770 6年前 (2018-11-15) 5176℃ 1评论10喜欢