本书是《Spark快速数据处理》第三版,全书基于Spark 2.0.0编写。本书适合Spark入门者,作者Krishna Sankar,由Packt出版社于2016年10月出版,全书共274页。通过本书你将学到以下知识: (1)、安装和设置你的Spark集群; (2)、使用Spark交互式Shell来实现简单的分布式应用程序; (3)、使用新的DataFrame API操作数据; 9年前 (2016-12-14) 4481℃ 0评论5喜欢
Carlos E. Perez对深度学习的2017年十大预测,让我们不妨看一看。有兴趣的话,可以在一年之后回顾这篇文章,看看这十大预测有多少准确命中硬件将加速一倍摩尔定律(即2017年2倍) 如果你跟踪Nvidia和Intel的发展,这当然是显而易见的。Nvidia将在整个2017年占据主导地位,只因为他们拥有最丰富的深度学习生态系统。没有头 9年前 (2016-12-13) 2290℃ 0评论3喜欢
在HDFS中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。 9年前 (2016-12-13) 5981℃ 0评论13喜欢
本书旨在通过教你如何扩展Spark的功能,将你对Spark的有限知识提升到一个新的水平。全书从Spark生态系统开始概述,您将学习如何使用MLlib创建一个完全的神经网络系统,然后您将了解如何调整流处理以获得最佳性能并确保并行处理。本书作者Mike Frampton,由Packt 于2015年09月出版,全书318页,通过本书你将学到以下知识: ( 9年前 (2016-12-04) 3937℃ 0评论9喜欢
如果你使用Apache Spark解决了中等规模数据的问题,但是在海量数据使用Spark的时候还是会遇到各种问题。High Performance Spark将会向你展示如何使用Spark的高级功能,所以你可以超越新手级别。本书适合软件工程师、数据工程师、开发者以及Spark系统管理员的使用。本书作者Holden Karau, Rachel Warren,由O'Reilly于2016年03月出版,全书175页 9年前 (2016-12-04) 5119℃ 0评论6喜欢
Shanghai Apache Spark Meetup第十一次聚会,将于12月10日,举办于上海大连路688号宝地广场22楼小沃科技活动场地。靠近地铁4号线和12号线的大连路站。本次会议得到中国联通小沃科技的大力支持。欢迎大家前来参加!会议主题1、演讲主题:《Spark Streaming构建实时系统介绍》 演讲嘉宾:程然,小沃科技高级架构师,开源爱好者 9年前 (2016-12-01) 1901℃ 0评论5喜欢
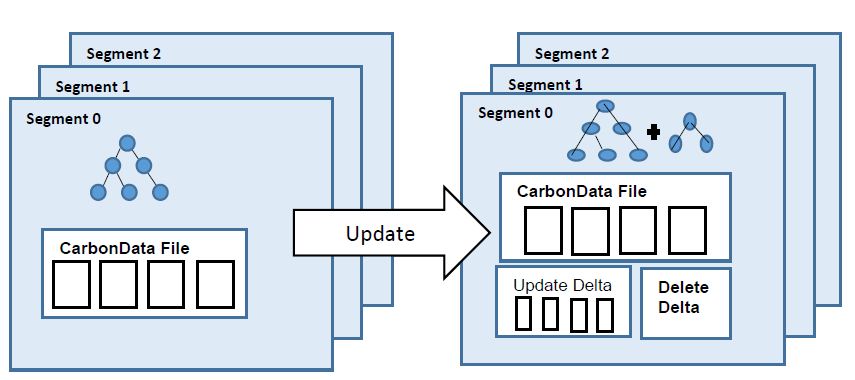
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。 当前,CarbonData暂不支持修改表中已经存在的数据。但是在现实情况下,我们可能很希望这个功能,比如修改 9年前 (2016-11-30) 2922℃ 0评论10喜欢
在《Spark读取Hbase中的数据》文章中我介绍了如何在Spark中读取Hbase中的数据,并提供了Java和Scala两个版本的实现,本文将接着上文介绍如何通过Spark将计算好的数据存储到Hbase中。 Spark中内置提供了两个方法可以将数据写入到Hbase:(1)、saveAsHadoopDataset;(2)、saveAsNewAPIHadoopDataset,它们的官方介绍分别如下: saveAsHad 9年前 (2016-11-29) 17975℃ 1评论29喜欢
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据。我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等。但是这些方式不是慢就是在导入的过程的占用Region资源导致效率低下,所以很不适合一次性导入大量数据。本文将针对这个问题介绍如何通过Hbase的BulkLoad方法来快速将海量数据导入到Hbas 9年前 (2016-11-28) 18254℃ 2评论52喜欢
Apache Flink开源大数据处理系统最近比较火,特别是其流处理框架的设计。本文并不打算介绍Apache Flink的相关概念,如果你感兴趣可以到本博客的Flink分类目录查看Flink的相关文章。 转入正题了,下面将一步一步教你如何提交你的代码到Flink社区。1、提交Issue 既然能够提交代码肯定是发现了什么Bug,或者有什么好 9年前 (2016-11-21) 3556℃ 0评论4喜欢

![[电子书]Fast Data Processing with Spark 2, 3rd Edition下载](https://www.iteblog.com/pic/books/Fast_Data_Processing_with_Spark_2_iteblog.jpg)


![[电子书]Mastering Apache Spark下载](https://www.iteblog.com/pic/books/Mastering_Apache_Spark.jpg)
![[电子书]High Performance Spark下载](https://www.iteblog.com/pic/books/High_Performance_Spark.jpg)


![通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]](https://www.iteblog.com/pic/hbase_Bulkload_iteblog.png)
