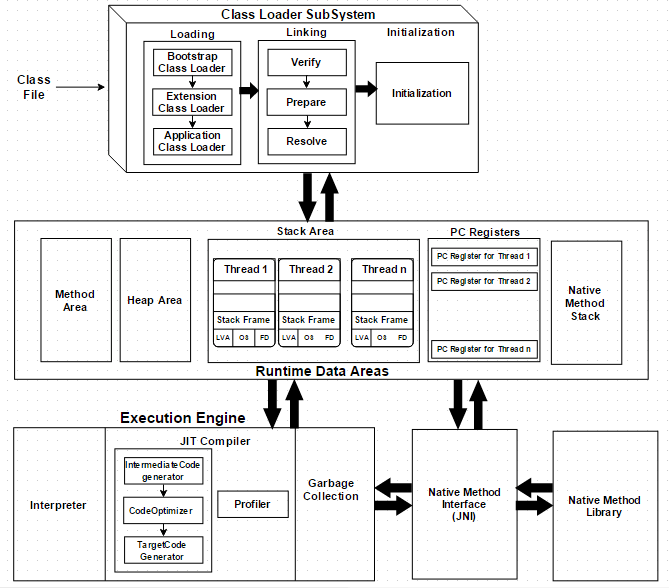
每个Java开发人员都知道字节码经由JRE(Java运行时环境)执行。但他们或许不知道JRE其实是由Java虚拟机(JVM)实现,JVM分析字节码,解释并执行它。作为开发人员,了解JVM的架构是非常重要的,因为它使我们能够编写出更高效的代码。本文中,我们将深入了解Java中的JVM架构和JVM的各个组件。JVM 虚拟机是物理机的软件 9年前 (2017-01-01) 3732℃ 0评论12喜欢
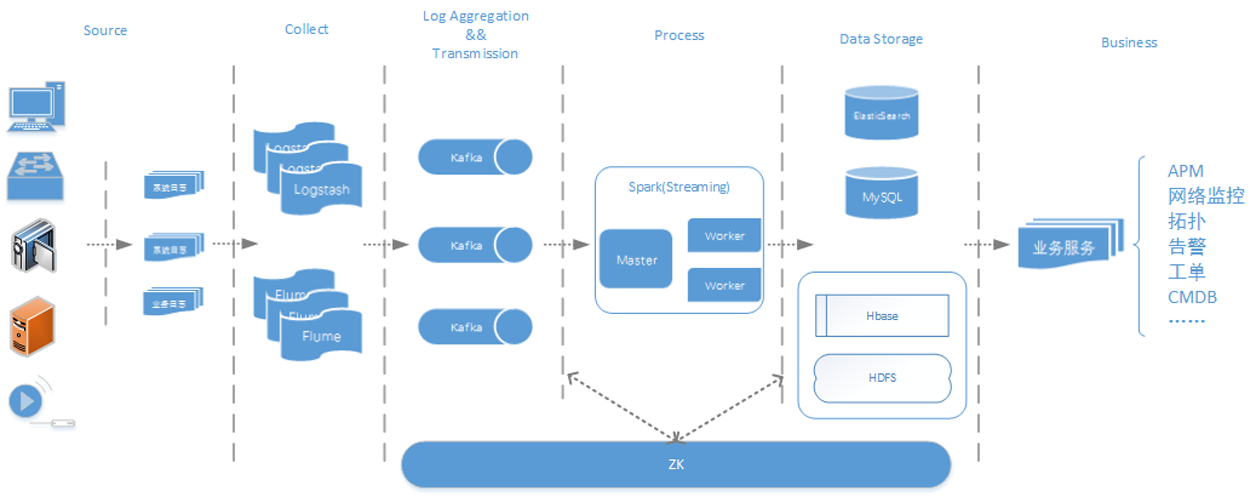
公安行业存在数以万计的前后端设备,前端设备包括相机、检测器及感应器,后端设备包括各级中心机房中的服务器、应用服务器、网络设备及机房动力系统,数量巨大、种类繁多的设备给公安内部运维管理带来了巨大挑战。传统通过ICMP/SNMP、Trap/Syslog等工具对设备进行诊断分析的方式已不能满足实际要求,由于公安内部运维管 9年前 (2017-01-01) 11418℃ 1评论39喜欢
今天我将介绍如何在Java工程使用Scala代码。对于那些想在真实场景中尝试使用Scala的开发人员来说,会非常有意思。这和你项目中有什么类型的东西毫无关系:不管是Spring还是Spark还是别的。我们废话少说,开始吧。抽象Java Maven项工程 这里我们使用Maven来管理我们的Java项目,项目的结果如下所示:如果想及时了解Spa 9年前 (2017-01-01) 9988℃ 0评论24喜欢
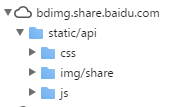
相信很多网站为了方便使用了百度分享工具,但是官方提供的类库只支持HTTP方式来访问,如果你网站升级成HTTPS之后,将无法使用百度分享。不过大家别担心,本文就是来教大家解决这个问题的。 原理很简单,下载本文下面提供的包(static.tgz),然后放到你网站的根目录,这些文件其实就是从百度分享网站下载下来的,如 9年前 (2016-12-31) 3060℃ 0评论8喜欢
Apache Spark 2.1.0是 2.x 版本线的第二个发行版。此发行版在为Structured Streaming进入生产环境做出了重大突破,Structured Streaming现在支持了event time watermarks了,并且支持Kafka 0.10。此外,此版本更侧重于可用性,稳定性和优雅(polish),并解决了1200多个tickets。以下是本版本的更新:Core and Spark SQL Spark官方发布新版本时,一般 9年前 (2016-12-30) 4341℃ 0评论8喜欢
如果你经常写MapReduce作业,你肯定看到过以下的异常信息:[code lang="bash"]Application application_1409135750325_48141 failed 2 times due to AM Container forappattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container[pid=4733,containerID=container_1409135750325_48141_02_000001] is running beyond physical memory limits.Current usage: 2.0 GB of 2 GB physical memory used; 6.0 GB of 9年前 (2016-12-29) 4361℃ 1评论11喜欢
Apache Flink 1.1.4于2016年12月21日正式发布,本版本是Flink的最新稳定版本,主要以修复Bug为主;强烈推荐所有的用户升级到Flink 1.1.4版本,替换pom中的以为如下:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.1.4</version></dependency><dependency> & 9年前 (2016-12-27) 2422℃ 0评论3喜欢
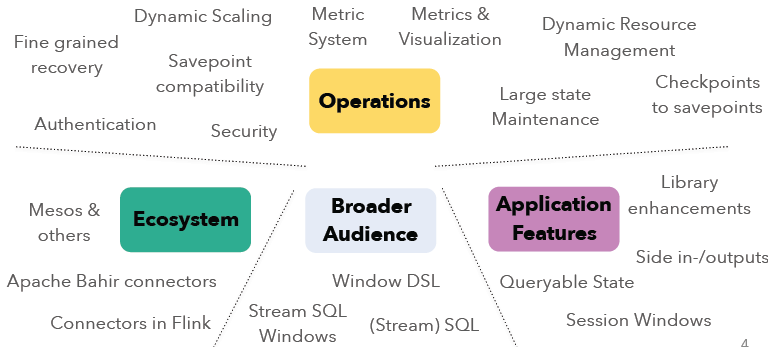
本文将概述即将发布的Apache Flink 1.2.0新功能。在Apache Flink 1.1+版本上,社区主要的集中点在操作性(Operations)、生态系统(Ecosystem)、更广泛的用户(Broader Audience)以及应用特性(Application Features)等方面的开发。各个模块的开发主要包括了如下的方向:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号 9年前 (2016-12-18) 3029℃ 0评论4喜欢
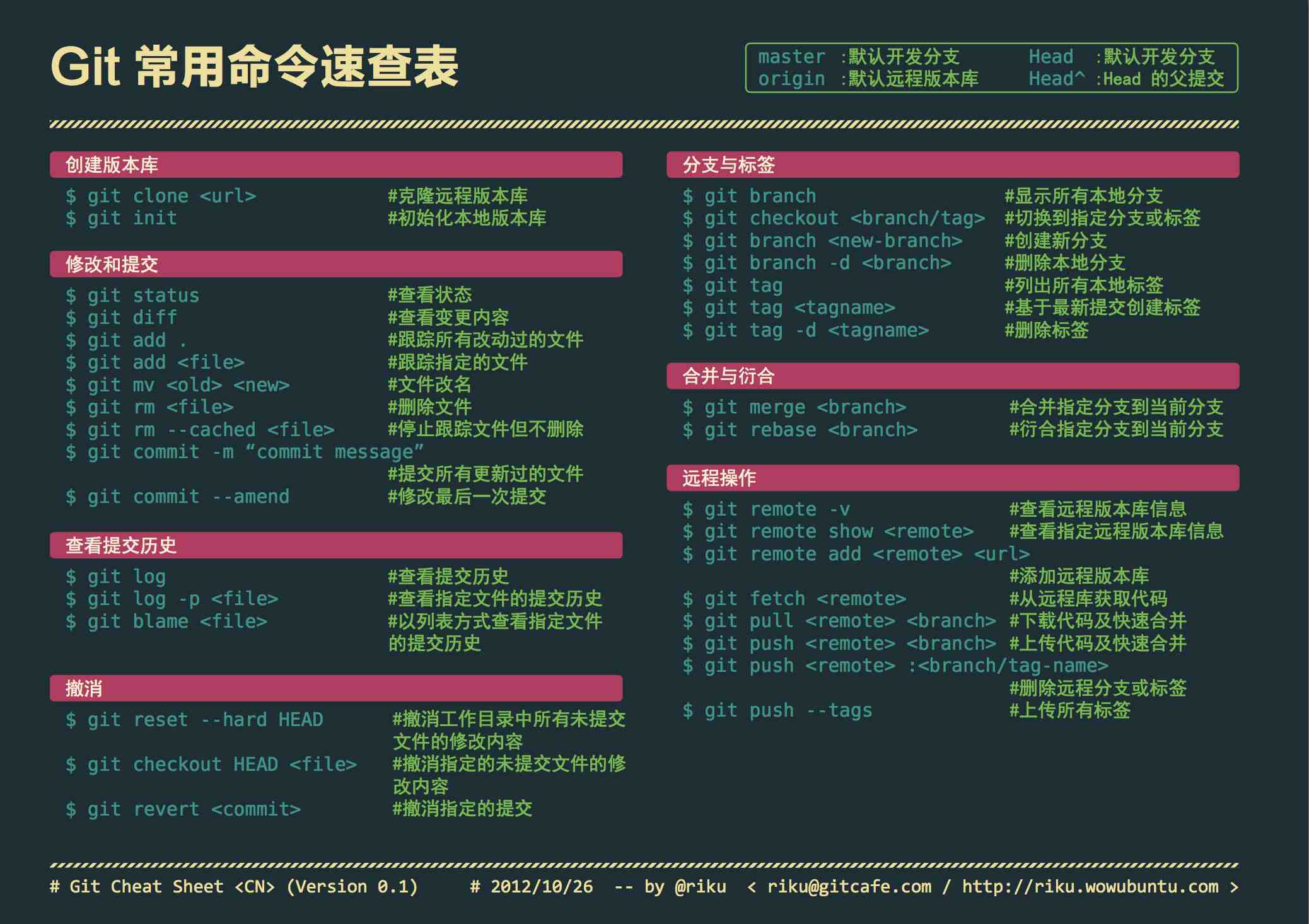
本文列出Git常用命令,点击下图查看大图如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop入门[code lang="bash"]git initorgit clone url[/code]配置[code lang="bash"]git config --global color.ui truegit config --global push.default currentgit config --global core.editor vimgit config --global user.name "John Doe" 9年前 (2016-12-16) 2481℃ 0评论2喜欢
在今年的09月08日,Google在其安全博客中宣布:为了让用户更加方便了解他们与网站之间的连接是否安全,从2017年1月份正式发布的Chrome 56开始,Google将彻底把含有密码登录和交易支付等个人隐私敏感内容的HTTP页面标记为【不安全】,并且将会在后续更新的Chrome版本中,逐渐把所有的HTTP网站标记为【不安全】。HTTPS已成为网站的 9年前 (2016-12-15) 3717℃ 0评论9喜欢