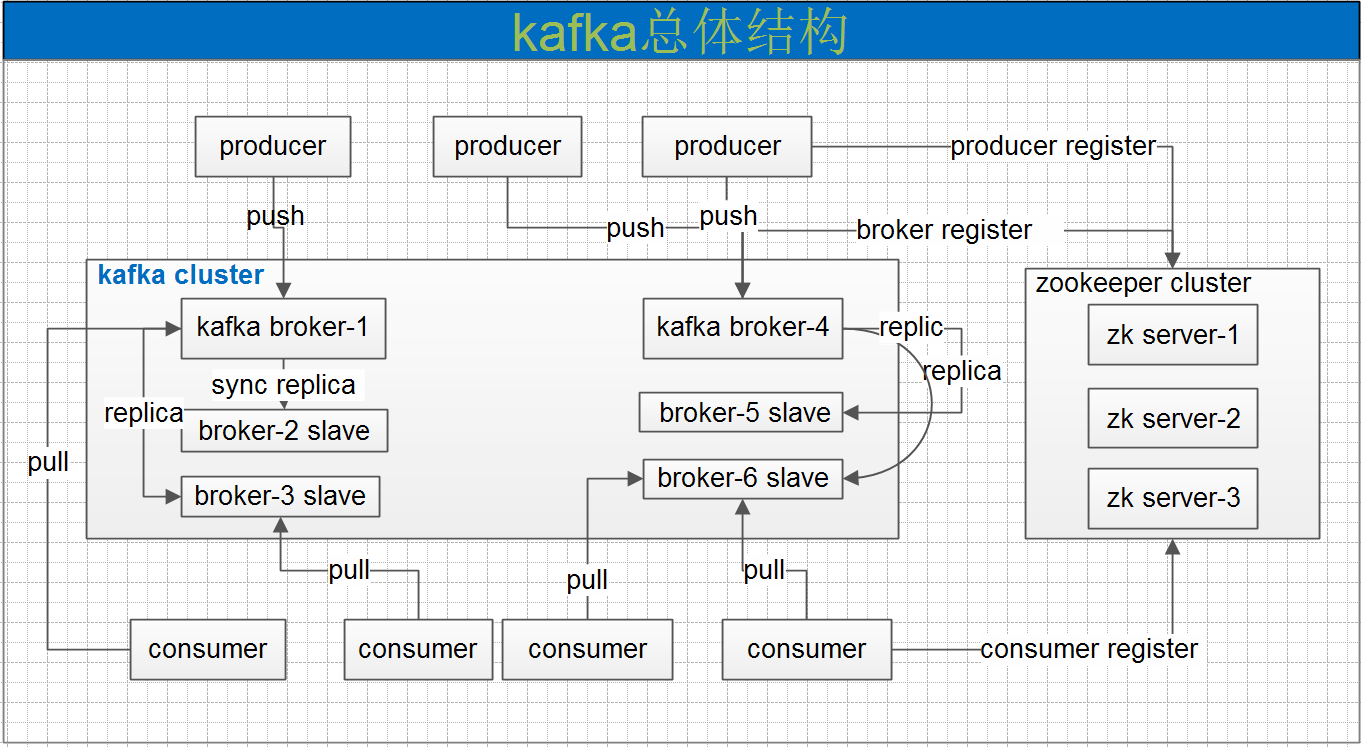
熟悉 Kafka 的同学肯定知道,每个主题有多个分区,每个分区会存在多个副本,本文今天要讨论的是这些副本是怎么样放置在 Kafka 集群的 Broker 中的。大家可能在网上看过这方面的知识,网上对这方面的知识是千变一律,都是如下说明的:为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。Kafka分配Replica的 8年前 (2017-08-08) 7109℃ 26喜欢
本文节选自《大数据之路:阿里巴巴大数据实践》,关注 iteblog_hadoop 公众号并在这篇文章里面文末评论区留言(认真写评论,增加上榜的机会)。留言点赞数排名前5名的粉丝,各免费赠送一本《大数据之路:阿里巴巴大数据实践》,活动截止至08月11日18:00。这篇文章评论区留言才有资格参加送书活动:https://mp.weixin.qq.com/s/BR7M8Rty 8年前 (2017-08-03) 1743℃ 0评论11喜欢
Kafka的基本介绍Kafka最初由Linkedin公司开发,是一个分布式、分区、多副本、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常用于web/nginx日志、访问日志,消息服务等等场景。Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。Kafka主要设计目标如下: 8年前 (2017-08-03) 5473℃ 0评论14喜欢
假设我们有个需求,需要解析文件里面的Json数据,我们的Json数据如下:[code lang="xml"]{"website": "www.iteblog.com", "email": "hadoop@iteblog.com"}[/code]我们使用play-json来解析,首先我们引入相关依赖:[code lang="xml"]<dependency> <groupId>com.typesafe.play</groupId> <artifactId>play-json_2.10</artifactId 8年前 (2017-08-02) 3045℃ 0评论16喜欢
和其他大数据系统类似,Flink 内置也提供 metric system 供我们监控 Flink 程序的运行情况,包括了JobManager、TaskManager、Job、Task以及Operator等组件的运行情况,大大方便我们调试监控我们的程序。系统提供的一些监控指标名字有下面几个: metrics.scope.jm 默认值: <host>.jobmanager job manager范围内的所有metrics将会使用这 8年前 (2017-08-01) 3294℃ 0评论6喜欢
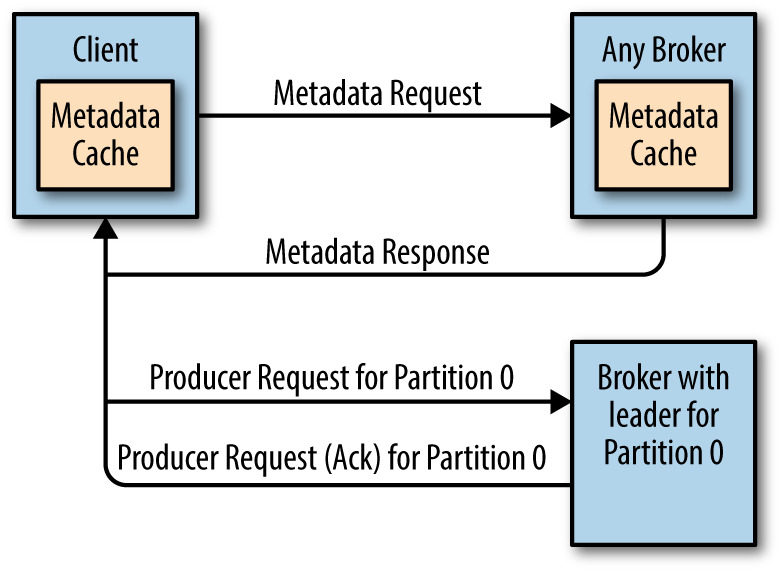
在正常情况下,Kafka中的每个Topic都会有很多个分区,每个分区又会存在多个副本。在这些副本中,存在一个leader分区,而剩下的分区叫做 follower,所有对分区的读写操作都是对leader分区进行的。所以当我们向Kafka写消息或者从Kafka读取消息的时候,必须先找到对应分区的Leader及其所在的Broker地址,这样才可以进行后续的操作。本文将 8年前 (2017-07-28) 2131℃ 0评论6喜欢
众所周知,Kafka自己实现了一套二进制协议(binary protocol)用于各种功能的实现,比如发送消息,获取消息,提交位移以及创建topic等。具体协议规范参见:Kafka协议 这套协议的具体使用流程为:客户端创建对应协议的请求客户端发送请求给对应的brokerbroker处理请求,并发送response给客户端如果想及时了解Spark、Hadoop或者HBase 8年前 (2017-07-27) 443℃ 0评论0喜欢
最近使用ElasticSearch的时候遇到以下的异常[code land="bash"]2017-07-27 16:06:48.482 MessageHandler - message process error: java.lang.NoClassDefFoundError: Could not initialize class org.elasticsearch.common.xcontent.smile.SmileXContent at org.elasticsearch.common.xcontent.XContentFactory.contentBuilder(XContentFactory.java:124) ~[elasticsearch-2.3.4.jar:2.3.4] at org.elasticsearch.action.support.ToX 8年前 (2017-07-27) 8807℃ 0评论13喜欢
我们都知道,目前 Apache Beam 仅仅提供了 Java 和 Python 两种语言的 API,尚不支持 Scala 相关的 API。基于此全球最大的流音乐服务商 Spotify 开发了 Scio ,其为 Apache Beam 和 Google Cloud Dataflow 提供了Scala API,使得我们可以直接使用 Scala 来编写 Beam 应用程序。Scio 开发受 Apache Spark 和 Scalding 的启发,目前最新版本是 Scio 0.3.0,0.3.0版本之前依赖 8年前 (2017-07-25) 1325℃ 0评论7喜欢
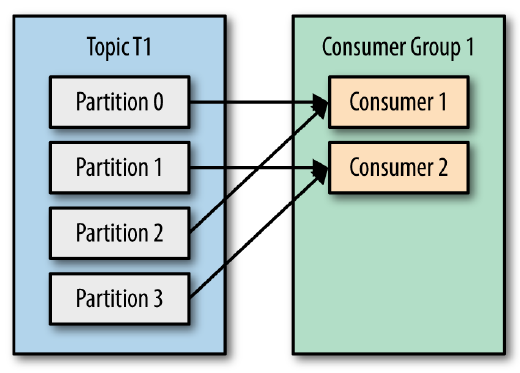
问题用过 Kafka 的同学应该都知道,每个 Topic 一般会有很多个 partitions。为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会启动一个或多个streams去分别消费 Topic 对应分区中的数据。我们又知道,Kafka 存在 Consumer Group 的概念,也就是 group.id 一样的 Consumer,这些 Consumer 属于同一个Consumer Group 8年前 (2017-07-22) 18079℃ 3评论27喜欢