在 《HDFS 块和 Input Splits 的区别与联系》 文章中介绍了HDFS 块和 Input Splits 的区别与联系,其中并没有涉及到源码级别的描述。为了补充这部分,这篇文章将列出相关的源码进行说明。看源码可能会比直接看文字容易理解,毕竟代码说明一切。为了简便起见,这里只描述 TextInputFormat 部分的读取逻辑,关于写 HDFS 块相关的代码请参 8年前 (2018-05-16) 2437℃ 0评论19喜欢
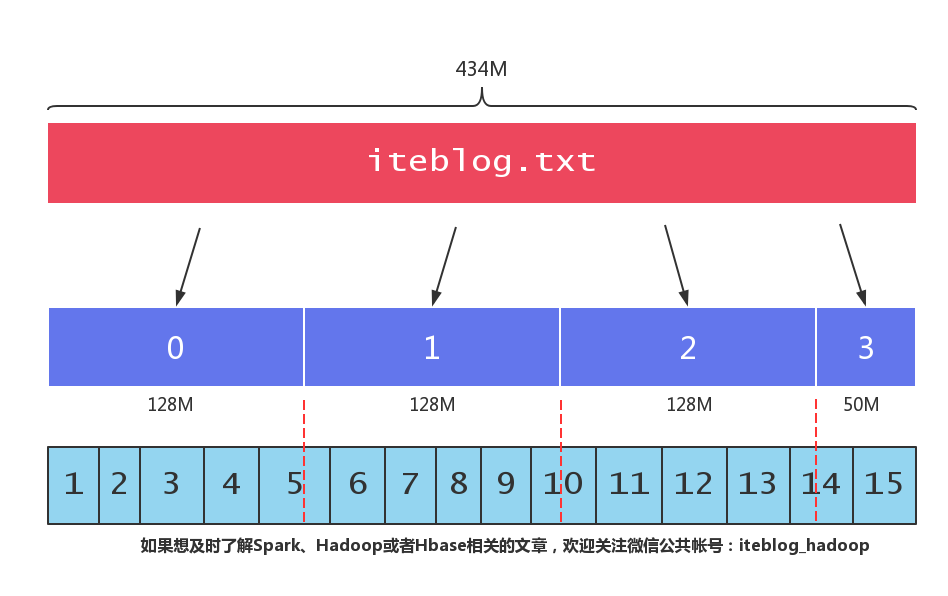
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 8年前 (2018-05-16) 2764℃ 4评论28喜欢
Apache Kafka 从 0.11.0.0 版本开始支持在消息中添加 header 信息,具体参见 KAFKA-4208。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文将介绍如何使用 spring-kafka 在 Kafka Message 中添加或者读取自定义 headers。本文使用各个系统的版本为:Spring Kafka: 2.1.4.RELEASESpring Boot: 2.0.0.RELEASEApache Kafka: kafka 8年前 (2018-05-13) 5081℃ 0评论0喜欢
杭州第六次 Spark & Flink Meetup 于2018年05月12日在华为杭研所1号楼1楼报告厅进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop议题本次会议的议题如下:冯叶磊 - 华为云 《Time GeoSpatial on Flink SQL》范文臣 - Spark PMC 《deep dive into structural streaming》梁永峰 - 阿里《基于Flink的流计算平台 8年前 (2018-05-13) 3974℃ 1评论8喜欢
Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越多,其中就包含了大量的中国用户,这些中国用户可能有很多人英文不是特别好,或者没那么多时间去看英文文档。基于 8年前 (2018-05-09) 10919℃ 0评论22喜欢
一致性问题在介绍分布式系统一致性问题之前,我们先来了解一下副本概念。分布式系统会存在许多异常问题,比如机器宕机;为了提供高可用服务,一般会将数据或者服务部署到很多机器上,这些机器中的数据或服务可以称为副本。如果其中任何一台节点出现故障,用户可以访问其他机器上的数据或服务。由于副本的存在,如 8年前 (2018-05-04) 4731℃ 0评论10喜欢
二叉树的前序遍历给你二叉树的根节点 root ,返回它节点值的 前序 遍历。示例 1:输入: [code lang="bash"] 1 \ 2 / 3 [/code]输出: [1,2,3]示例 2:输入: [code lang="bash"] 1 /2[/code]输出: [1,2]递归首先我们需要了解什么是二叉树的前序遍历:按照访问根节点——左子树——右子树的方式遍历这棵树,而在 8年前 (2018-05-02) 128℃ 0评论0喜欢
本文来自 恩爸 的文章,原文地址:https://blog.csdn.net/zzcclp/article/details/80161130前言一个偶然的机会,从某Spark微信群知道了CarbonData,从断断续续地去了解,到测试 1.2 版本,再到实际应用 1.3 版本的流式入库,也一年有余,在这期间,得到了 CarbonData 社区的陈亮,李昆,蔡强等大牛的鼎力支持,自己也从认识CarbonData 到应用 Carbo 8年前 (2018-05-02) 2883℃ 0评论7喜欢
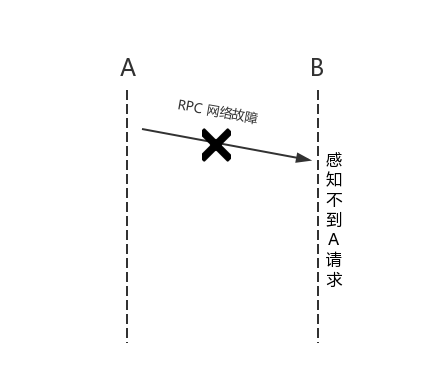
在传统的单机系统中,我们调用一个函数,这个函数要么返回成功,要么返回失败,其结果是确定的。可以概括为传统的单机系统调用只存在两态(2-state system):成功和失败。然而在分布式系统中,由于系统是分布在不同的机器上,系统之间的请求就相对于单机模式来说复杂度较高了。具体的,节点 A 上的系统通过 RPC (Remote Proc 8年前 (2018-04-20) 2634℃ 0评论9喜欢
4月6日,Apache Hadoop 3.1.0 正式发布了,Apache Hadoop 3.1.0 是2018年 Hadoop-3.x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,这个版本并不推荐在生产环境下使用,如果需要在正式环境下使用,请等待 3.1.1 或 3.1.2 版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop这个版 8年前 (2018-04-08) 3700℃ 0评论15喜欢