
文章目录
在 LinkedIn,我们非常依赖离线数据分析来进行数据驱动的决策。多年来,Apache Spark 已经成为 LinkedIn 的主要计算引擎,以满足这些数据需求。凭借其独特的功能,Spark 为 LinkedIn 的许多关键业务提供支持,包括数据仓库、数据科学、AI/ML、A/B 测试和指标报告。需要大规模数据分析的用例数量也在快速增长。从 2017 年到现在,LinkedIn 的 Spark 使用量同比增长了大约 3 倍。 因此,LinkedIn 的 Spark 引擎现在运行在一个庞大的基础设施之上。我们的生产集群有 10,000 多个节点,Spark 作业现在占集群计算资源使用量的 70% 以上,每日处理的数据量达数十 PB。 解决扩展性挑战以确保我们的 Spark 计算基础设施可持续发展是 LinkedIn Spark 团队工作的核心。
尽管 Apache Spark 有很多好处,这使得它在 LinkedIn 和整个行业中都很受欢迎,但在我们的数据规模下使用 Spark 时,我们仍然遇到了一些挑战。 正如我们在 Spark + AI Summit 2020 演讲中所述,这些挑战涉及多个层面,包括计算资源管理、计算引擎可扩展性和用户生产率。我们将在这篇博文中关注 Spark shuffle 可扩展性挑战,并介绍 Magnet,一种新颖的基于推送模式的 shuffle 服务(push-based shuffle service)。
Shuffle 基础知识
数据 shuffle 是 MapReduce 计算范式中的一项重要操作,为 Apache Spark 和许多其他现代大数据计算引擎提供动力。 shuffle 操作基本上是通过相应阶段的 map 和 reduce 任务之间的 all-to-all 连接来传输中间数据。通过 shuffle,数据将根据每个记录的分区键中的值在所有的 shuffle 分区上进行适当的分区。如图 1 所示:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
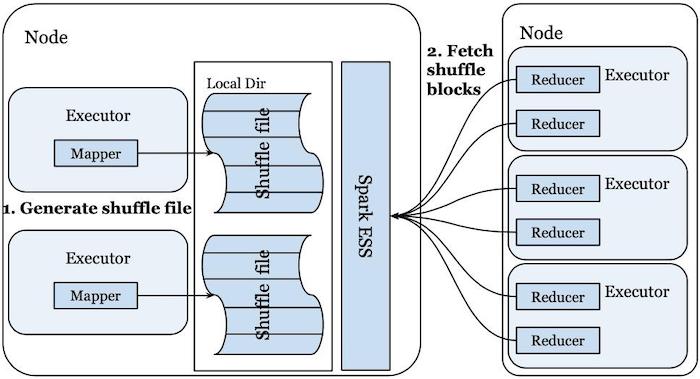
虽然 shuffle 操作的基本概念很简单,但不同的计算引擎采用了不同的方法来实现它。在 LinkedIn,我们在 Apache YARN 之上运行 Spark,并利用 Spark 的External Shuffle Service (ESS) 来进行 shuffle 操作。如图 2 所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
通过这种设置,计算集群中的每个节点都部署了一个 Spark ESS 实例。 当 Spark executors 运行 shuffle 的 mapper 任务时,这些任务会在本地磁盘上生成 shuffle 文件。 每个 shuffle 文件由多个 shuffle 块组成,每个块代表属于相应 shuffle 分区的数据。生成这些 shuffle 文件后,本地 Spark ESS 实例知道在哪里可以找到这些 shuffle 文件以及不同 mapper 任务生成的各个 shuffle 块。 当 Spark 执行器开始运行同一个 shuffle 的 reducer 任务时,这些任务将从 Spark driver 获取有关在哪里可以找到 shuffle 块的信息作为它们的任务输入。然后这些 reducer 会向远程 Spark ESS 实例发送请求,尝试获取它们对应的 shuffle 块。 Spark ESS 收到此类请求后,将从本地磁盘读取相应的 shuffle 块并将数据发送回 reducer。
挑战
Spark 现有的 shuffle 机制在性能和容错要求之间取得了很好的平衡。然而,当在我们的规模下运行 Spark shuffle 时,我们经历了多个挑战,这使得 shuffle 操作成为我们基础设施中的扩展和性能瓶颈。
可靠性问题
第一个挑战是可靠性问题。在我们的生产集群中,由于计算节点数据量大和 shuffle 工作负载的规模,我们注意到集群高峰时段的 shuffle 服务可用性问题。 这可能会导致 shuffle fetch 失败,从而导致昂贵的 stage 重试,这可能非常具有破坏性,因为它们会导致工作流 SLA 违规和作业失败。 图 3 进一步说明了这一点,其中显示了由于 shuffle 导致的每日 Spark stage 失败的数量。到 2019 年底,这一趋势越来越严重,每天有数百到一千多个 stage 因为这个失败。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
效率问题
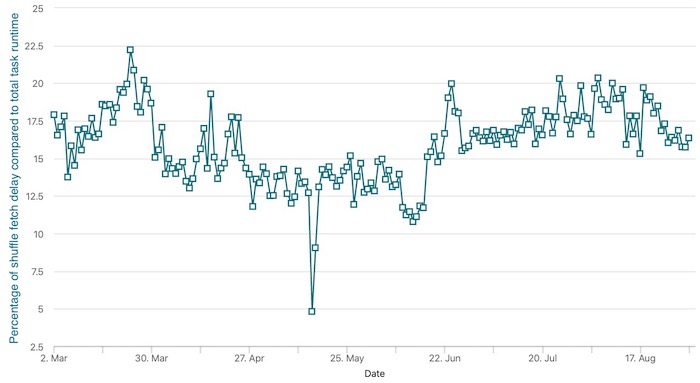
第二个挑战是效率问题。 在 LinkedIn,我们将 shuffle 文件存储在 HDD 上。 由于 reducer 的 shuffle fetch 请求是随机到达的,因此 shuffle 服务也会随机访问 shuffle 文件中的数据。 如果单个 shuffle 块大小较小,则 shuffle 服务产生的小随机读取会严重影响磁盘吞吐量,从而延长 shuffle fetch 等待时间。 这也在下图中进行了说明。正如下图所示,在 2020 年 3 月至 8 月之间,我们生产集群的 10-20% 的计算资源浪费在 shuffle 上,在等待远程 shuffle 数据时处于空闲状态。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
扩展性问题
第三个挑战是扩展问题。由于 external shuffle service 是我们基础架构中的共享服务,因此一些对 shuffle services 错误调优的作业也会影响其他作业。当一个作业错误地配置导致产生许多小的 shuffle blocks 将会给 shuffle 服务带来压力时,它不仅会给自身带来性能下降,还会使共享相同 shuffle 服务的所有相邻作业的性能下降。这可能会导致原本正常运行的作业出现不可预测的运行时延迟,尤其是在集群高峰时段。
Magnet shuffle service
为了解决这些问题,我们设计并实现了 Magnet,这是一种新颖的基于推送(push-based)的 shuffle 服务。Magnet 项目在今年早些时候作为 VLDB 2020 上发表的工业跟踪论文首次向社区亮相,您可以在此处阅读我们的 VLDB 论文:Magnet: Push-based Shuffle Service for Large-scale Data Processing。 最近,我们正在将 Magnet 回馈给 Apache Spark 社区。 这篇博文的其余部分将介绍 Magnet 背后的高级设计及其在生产中的性能,但感兴趣的读者可以到 SPARK-30602 中获取有关该工作的更新以及 SPIP 文档以获取实现级别的详细信息。
Push-based shuffle
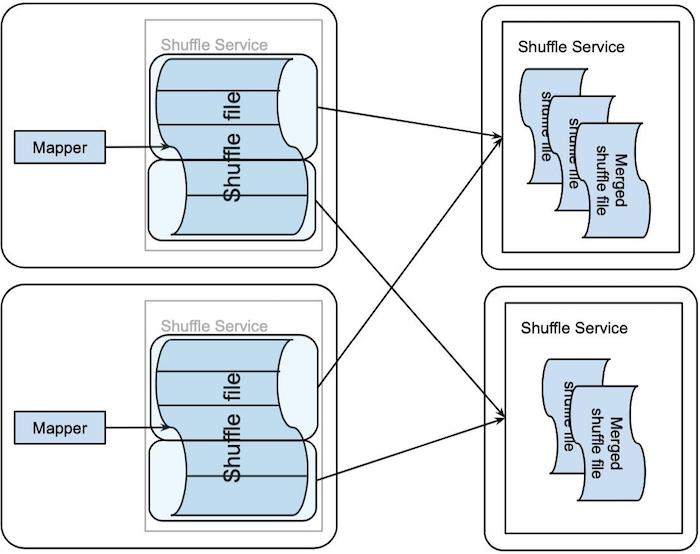
Magnet shuffle 服务背后的核心思想是基于推送的 shuffle 概念,其中 mapper 生成的 shuffle 块也被推送到远程 shuffle 服务,以按每个 shuffle 分区进行合并。push-based shuffle 的 shuffle 写入路径如下图所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
在 map 任务生成其 shuffle 文件后,它准备将 shuffle 块推送到远程 ESS。它将 shuffle 文件中的连续块组装成 MB 大小的块,并将该组数据推到相应的 ESS。大于特定大小的 Shuffle 块将被跳过,因此我们不会推送可能来自大型倾斜分区的块。map 任务以一致的方式确定这个分组和相应的 ESS 目的地,从而将属于同一个 shuffle 分区的不同 mappers 的块推到同一 ESS。分组完成后,这些块的传输将移交给专用线程池,然后 map 任务就完成了。通过这种方式,我们将任务执行线程与块传输线程解耦,在 I/O 密集型数据传输和 CPU 密集型任务执行之间实现了更好的并行性。 ESS 接受远程推送的 shuffle 块,并将相同分区的 shuffle 数据合并到相应的 shuffle 文件中。这是以尽力而为的方式完成的,这并不能保证所有块都被合并。但是,ESS 确实保证在合并期间不会发生数据重复或损坏。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
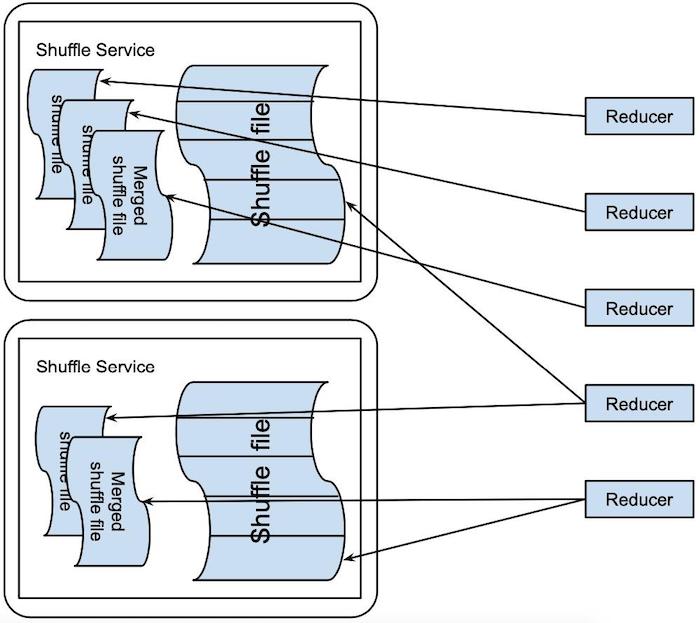
在基于推送的 shuffle 数据读取路径上,reduce 任务可以从合并的 shuffle 文件和 map 任务生成的原始 shuffle 文件中获取其任务输入(如上图)。 ESS 在从合并的 shuffle 文件中读取时可以执行大的顺序 I/O 而不是小的随机 I/O,从而显着提高 I/O 效率。利用这一点,reduce 任务更愿意从合并的 shuffle 文件中获取它们的输入。由于块推送/合并过程是尽力而为的,reduce 任务可以使用未合并的块来填充合并的 shuffle 文件中的任何漏洞。 如果合并的 shuffle 文件变得不可用,他们甚至可以完全回退到获取未合并的块。 Magnet 的高效磁盘 I/O 模式进一步为构建高性能 Spark 集群提供了更大的灵活性,因为它更少依赖 SSD 来实现良好的 shuffle 性能。
Spark driver 负责协调 map 和 reduce 任务中基于推送的 shuffle。在 shuffle 写入路径上,Spark driver 为给定 shuffle 的 map 任务确定要使用的 ESS 列表。这个 ESS 列表作为任务上下文的一部分发送到 Spark executors,这使 map 任务能够在块组和远程 ESS 目的地之间提出上述一致的映射。 Spark 驱动程序进一步协调 map 和 reduce 阶段之间的转换。一旦所有的 map 任务都完成了,Spark 驱动程序会等待一段可配置的时间,然后通知所有选择的 ESS 进行这次 shuffle 以完成合并操作。当 ESS 收到终结请求时,它停止接受来自给定 shuffle 的任何新块。它还向驱动程序响应每个最终 shuffle 分区的元数据列表,其中包括有关合并的 shuffle 文件的位置和大小信息以及指示哪些块已合并的位图。一旦 Spark 驱动程序从所有 ESS 接收到此类元数据,它就会启动 reduce 阶段。此时,Spark 驱动程序拥有 shuffle 数据位置的完整视图,现在在合并的 shuffle 文件和原始 shuffle 文件之间进行了 2 次复制。 Spark 驱动程序利用此信息来协调 reduce 任务的输入位置。此外,合并的 shuffle 文件的位置为 reduce 任务创建了自然的位置偏好。Spark 驱动程序利用该信息可以在存储了 shuffle 信息的机器上启动 reduce 任务,如下图所示:
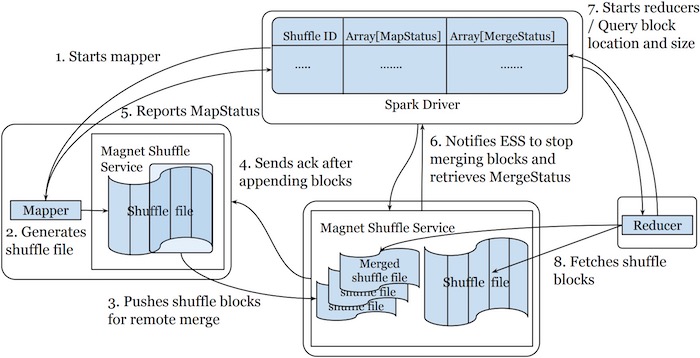
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
push-based shuffle 的优势
Push-based shuffle 为 Spark shuffle 带来了几个关键好处。
提高磁盘 I/O 效率
使用 push-based shuffle,shuffle 服务在访问 shuffle 文件中的 shuffle 数据时,从小的随机读取切换到大的顺序读取,显着提高了磁盘 I/O 效率,特别是对于基于 HDD 的 shuffle 存储。在 shuffle 写路径上,即使对小块进行两次 shuffle 数据写入,整体的 I/O 效率还是有提升的。这是因为小的随机写入可以从多个级别的缓存中受益,例如操作系统页面缓存和磁盘缓冲区。因此,小随机写入可以实现比小随机读取高得多的吞吐量。改进的磁盘 I/O 效率的效果反映在本博文后面显示的性能数据中。关于 I/O 效率提升的更详细分析包含在我们的 VLDB 论文中。
缓解 shuffle 的可靠性/可扩展性问题
Spark 原生 shuffle 操作要成功,需要每个 reduce 任务成功地从所有 map 任务中获取每个相应的 shuffle 块,这在拥有数千个节点的繁忙集群中通常无法满足。 Magnet 通过多种方式实现了更好的 shuffle 可靠性:
- Magnet 采用尽力而为的方法来合并块。块推送/合并过程中的失败不会影响 shuffle 的过程。
- 通过基于推送的 shuffle,Magnet 有效地生成了 shuffle 中间数据的第二个副本。只有在无法从原始 shuffle 文件或合并的 shuffle 文件中获取 shuffle 块时,才会发生 shuffle fetch 失败。
通过 reduce 任务的位置感知调度,它们通常在合并后的 shuffle 文件所在的机器上启动,这允许它们绕过 ESS 读取 shuffle 数据。这使得 reduce 任务对 ESS 可用性或性能问题更具弹性,从而缓解前面提到的可扩展性问题。
在块推送过程中处理 stragglers
在 Spark 的普通 shuffle 操作中,由于多个任务通常是并发运行的,任务中的掉队者(即一些任务运行速度明显慢于其他任务)的影响可以被其他任务隐藏。使用基于推送的 shuffle,如果在块推送操作中有任何落后者,它可能会暂停执行很长时间的作业。这是因为块推送操作介于 shuffle map 和 reduce 阶段之间。 当存在落后者时,可能根本没有任务在运行。然而,通过提前终止技术,Magnet 可以在块推送过程中有效地处理掉队者。 Magnet 不是等待 push 过程完全完成,而是限制它在 shuffle map 和 reduce 阶段之间等待的时间。 Magnet 的尽力而为的特性使其能够容忍由于提前终止而未合并的块。 如下图所示:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
与 Spark 原生集成
Magnet 与 Spark 原生集成,这带来了多种好处:
- Magnet 不依赖于其他外部系统。 这有助于简化 Magnet shuffle 服务的部署、监控和生产。
- 通过与 Spark 的 shuffle 系统的原生集成,Magnet shuffle 服务中的元数据可以暴露给 Spark 驱动程序。这使 Spark 驱动程序能够实现更好的性能(通过任务的位置感知调度)和更好的容错(通过回退到原始 shuffle 块)。
- Magnet 与现有的 Spark 功能(例如自适应查询执行)配合得很好。 Spark AQE 的承诺之一是能够动态优化 skew join,这也需要对 shuffle 进行特殊处理。 Spark AQE 会在多个 reducer 任务之间划分一个倾斜的 shuffle 分区,每个任务只从 mapper 任务的一个子范围中获取 shuffle 块。 由于合并后的 shuffle 文件不再保持每个单独的 shuffle 块的原始边界,因此无法按照 Spark AQE 要求的方式划分合并后的 shuffle 文件。 由于 Magnet 保留原始 shuffle 文件和合并后的 shuffle 文件,因此它可以委托 AQE 处理偏斜分区,同时优化非偏斜分区的 shuffle 操作。
性能对比
我们在 LinkedIn 上使用真实的生产作业评估了 Magnet 的性能,我们看到了非常不错的结果。在下表中,我们展示了运行一个 ML 特征生成作业的性能结果,该作业具有数十个 shuffle 阶段和接近 2 TB 的 shuffle 数据。 与 Spark 中的原生 shuffle 相比,Magnet 取得了非常好的性能结果。请注意,Magnet 将 shuffle fetch 等待时间减少了 98%。这可以通过 Magnet 的高效随机磁盘 I/O 和减少任务的位置感知调度来实现。此外,这个作业并不完全使用 Spark SQL,因为它混合使用了 Spark SQL 和非 SQL 代码组成其计算逻辑。在优化 shuffle 操作时,Magnet 只承担很少的工作本身。
| Total shuffle fetch wait time (min) | Total executor task runtime (min) | End-to-end job runtime (min) | |
| Vanilla Spark shuffle | 20636 | 50771 | 42 |
| Magnet shuffle | 445 (-98%) | 29928 (-41%) | 31 (-26%) |
我们还在 LinkedIn 引入了含有大量 shuffle 的作业。我们的一个生产集群中估计有 15% 的 shuffle 工作负载已迁移到 Magnet。在这些作业中,我们看到 shuffle fetch 等待时间、任务总运行时间和作业端到端运行时间也相应的减少。如下图所示,启用 Magnet 的 Spark 作业平均减少了 3-4 倍的随机提取等待时间。此外,我们已经看到本地访问的 shuffle 数据量增加了大约 10 倍,这表明基于推送的 shuffle 大大改善了数据局部性。最后,我们已经看到作业运行时间在集群高峰时段变得更加稳定。随着我们加入更多的作业,Magnet 将更多的 shuffle 工作负载转换为优化路径,从而减轻了 shuffle 服务的压力,并为集群带来更多好处。另一方面,Magnet 可能会将 shuffle 临时存储需求加倍。我们正在通过为 shuffle 文件切换到 zstd 压缩编解码器来缓解这种情况,与默认压缩编解码器相比,这有可能将 shuffle 文件大小减少 50%。
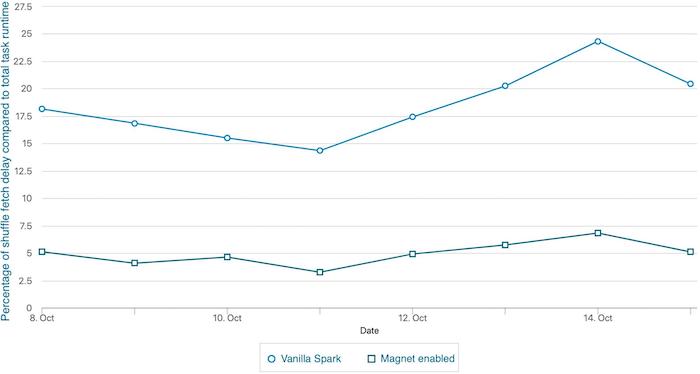
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
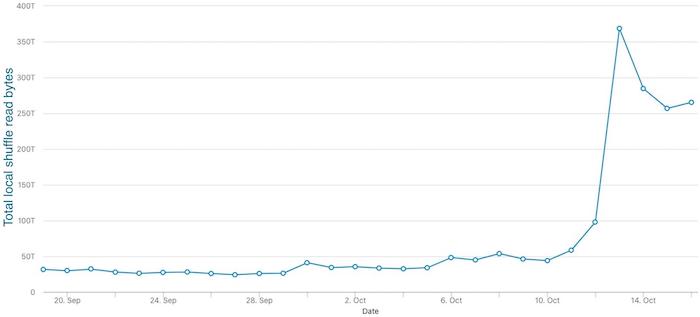
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
结论和未来工作
在这篇博文中,我们介绍了 Magnet shuffle 服务,这是 Apache Spark 的下一代 shuffle 架构。 Magnet 提高了 Spark 中 shuffle 操作的整体效率、可靠性和可扩展性。 最近,我们也看到了业界针对 shuffle 过程提出的其他解决方案,比如 Cosco、Riffle、Zeus 和 Sailfish。 我们在 VLDB 论文中对 Magnet 和其他这些解决方案进行了比较,尤其是 Cosco、Riffle 和 Sailfish。
未来,我们还将考虑在其他部署环境和计算引擎中提供基于 Magnet 推送的 shuffle。 我们当前的集群部署模式为存储和计算是在一起的。 随着 LinkedIn 正在向 Azure 迁移,我们也在评估计算和存储分离的集群中基于推送的 shuffle 的方法。此外,我们目前基于推送的 shuffle 的设计主要针对批处理引擎,我们也在考虑它对流引擎的适用性。
感谢
需要一个专门的团队才能将 Magnet 规模的项目带来曙光。 除了 Min Shen、Ye Zhou 和 Chandni Singh 的努力外,该项目还得到了 Venkata Krishnan Sowrirajan 和 Mridul Muralidharan 的重大贡献。 Erik Krogen、Ron Hu、Minchu Yang 和 Zoe Lin 为 Magnet 的生产部署和可观察性改进做出了贡献。 特别感谢 Yuval Degani 构建的 GridBench——这个工具使得理解各种因素对作业运行时的影响变得非常容易。特别感谢我们的合作伙伴团队,尤其是 Jan Bob 和 Qun Li 的团队,他们是 Magnet 的早期使用者。
像 Magnet 这样的大型基础设施工作需要管理层做出重大而持续的支持。 Sunitha Beeram、Zhe Zhang、Vasanth Rajamani、Eric Baldeschwieler、Kapil Surlakar 和 Igor Perisic:感谢您的坚定支持和指导。 Magnet 的设计也得益于与 Sriram Rao 和 Shirshanka Das 的评论和深入讨论。
Magnet 得到 Apache Spark 社区的大力支持。感谢与 Databricks 的合作以及来自众多社区成员的评论。
本文翻译自:Magnet: A scalable and performant shuffle architecture for Apache Spark
其他资料:
- Enabling push based shuffle in Spark
- SPARK-30602
- Bringing Next-Gen Shuffle Architecture To Data Infrastructure at LinkedIn Scale
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Magnet:LinkedIn 开源的可扩展、高性能的 Apache Spark shuffle 服务】(https://www.iteblog.com/archives/9960.html)







