在 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章中介绍了如何将 MySQL 中的全量数据导入到 Solr 中。里面提到一个问题,那就是如果数据量很大的时候,一次性导入数据可能会影响 MySQL ,这种情况下能不能分页导入呢?答案是肯定的,本文将介绍如何通过分页的方式将 MySQL 里面的数据导入到 Solr。
分页导数的方法和全量导大部分配置都一样,唯一要修改的地方就是修改 db-data-config.xml 配置文件,具体如下:
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/iteblog" user="root" password="xxx" />
<document>
<entity name="iteblog" query="select id,post_title,post_author from wp_posts order by id limit ${dataimporter.request.length} offset ${dataimporter.request.offset}">
<field column="id" name="id" />
<field column="post_title" name="post_title" />
<field column="post_author" name="post_author" />
</entity>
</document>
</dataConfig>
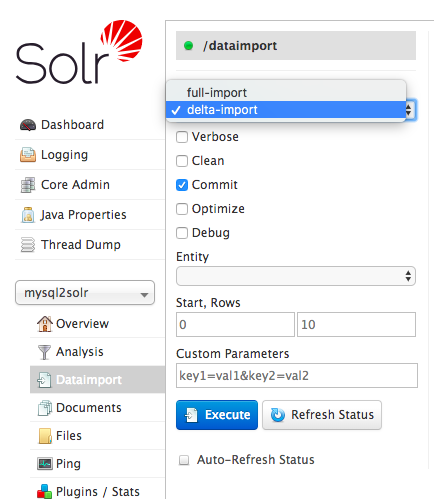
注意 select id,post_title,post_author from wp_posts order by id limit ${dataimporter.request.length} offset ${dataimporter.request.offset} 这行,这就是分页。那我们如何设置 ${dataimporter.request.length} 和 ${dataimporter.request.offset} 参数呢?很简单,如下页面:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
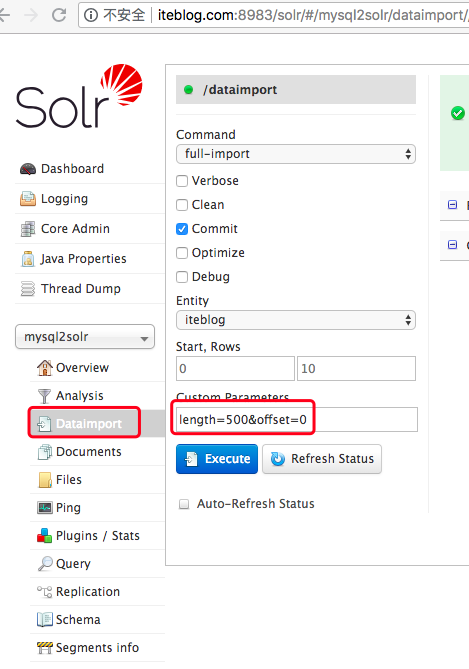
在 Solr Admin UI 页面的 dataimport 里面有个 Custom Parameters 选项,我们只需要填上 length=500&offset=0 参数,意思就是从偏移量0开始,共导入500条数据到 Solr 中,然后我们点击 Execute 按钮,过一会刷新页面就可以得到下面的输出:

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
可以看出我们已经成功导入了500条数据,其实上面的操作实际上等效于执行下面的 URL 请求:
http://iteblog.com:8983/solr/mysql2solr/dataimport?core=mysql2solr&offset=0&indent=on&commit=true&length=500&name=dataimport&clean=false&wt=json&command=full-import
同理,我们接着输入删除 length=500&offset=500 以及 length=500&offset=1000 将剩下的数据全部导完。最后结果如下:

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
实际上我们可以编写脚本来循环执行分页操作:
common="&indent=on&commit=true&length=500&name=dataimport&clean=false&wt=json&command=full-import"
page=2
for (( i=0; i <= $page; i++ )) ; do
curl "http://iteblog.com:8983/solr/mysql2solr/dataimport?core=mysql2solr&offset=$[i*500]$common"
done
上面的 page 就是分页的页数,在实际情况下我们可以直接从 MySQL 获取总的记录条数然后除以每页的条数再加一就是这里的 page。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【将 MySQL 的全量数据以分页的形式导入到 Apache Solr 中】(https://www.iteblog.com/archives/2405.html)